고정 헤더 영역
상세 컨텐츠
본문 제목
[Advanced ML & DL Week1] Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles
본문

작성자 : 14기 김태영
논문 링크 : Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles - DeepMind

1. Introduction and Basic
1) 신경망 모델의 한계점
다양한 신경망 모델들이 발전하면서 그 성능은 지속적으로 개선되고 있고 높은 accuracy를 보여주고 있다. 하지만 이런 높은 accuracy 이면에는 크게 다음과 같은 두가지 문제점이 있다.
< Uncertainty >
예측 불확실성, Predictive Uncertainty는 그 측정 자체에 대한 방법론이 잘 연구되지 않았었고 강조되지 않았던 내용이다.
신경망 모델들이 높은 성능을 보인다는 것은 confidence가 강하다라고 표현할 수 있다. 다만 이 confidence가 강한 것이 중요하고 이 confidence만을 평가 metrice으로 삼게되면 많은 문제점이 생긴다.
이 논문에서는 이런 이유로 predictive uncertainty를 적절한 방법론으로 측정해야 함을 강조하고 있는데 이 주장의 합리성은 여러 도메인에 비추어 생각할 수 있다. 예를 들면 자율주행자동차의 주행 시 객체 인식, 의료분야의 질병 진단의 경우 같이 생명과 직결되는 경우 모델이 높은 confidence만을 갖도록만 하고 모델의 uncertainty를 측정하지 않게 되면 그 위험성을 판단할 수 없게된다.
위 기존 모델의 문제점과 uncertainty의 측정 필요성을 알았다면 이것이 어떻게 표현되어야 하는지는 아래의 예시를 통해 알 수 있다.
- uncertainty를 반영하는 이상적인 상황 : 자율주행시 사람을 인식하는 모델이 객체를 사람으로 인식할 확률이 70%라면 confidence = 0.7 을 반환
- uncertainty를 반영하지 못하는 현실 : 위 상황에서 100% 가까운 accuracy를 보일 경우 사람에 대해 confidence = 1.0을 보이는 예측분포를 반환
< Out of Distribution >
out of distribution이란 모델이 한 데이터셋을 통해 학습되었고 높은 성능을 내었지만 학습에 없었던 새로운 class가 등장하고 추론해야 할 경우를 말한다. 하지만 기존 모델에서 accuracy라는 metric 하나만으로 측정하고 있었다면 이 accuracy가 낮아지는 정도로 밖에 새로운 class에 대해 설명하지 못한다. 따라서 이 새로운 class 등장에 대한 uncertainty도 표현해야 한다. 이를 표현하기 위해서는 새로운 class에 대해서는 예측분포가 최대한 uniform한 분포가 되어야 한다.
- 개와 고양이 두 class로 이루어진 데이터셋을 통해 분류모델이 학습됨.
- 호랑이라는 새 class가 등장 >> 개와 고양이라는 class에 대해서는 각각 0.5의 예측값을 가져 모델의 uncertainty를 표현해야 함.
2) 기존 Uncertainty 측정 방법
모델이 uncertainty를 표현하는 task에 대해 기존에 연구가 이뤄지지 않았던 것은 아니다. 이전까지는 이 task를 위해 베이지안 모델들이 이 많이 사용되었다. parameter를 확률분포로 가정하고 예측에 대한 predictive distribution을 구하는 모델로 좀 더 자세한 설명과 MC Dropout과 같은 예시는 이 포스팅에서 확인할 수 있다.
하지만 베이지안 기반 uncertainty를 측정하는 방식은 두가지 문제점을 가지고 문제점에 해당하는 논문의 해결책 쌍은 다음과 같이 두가지가 있다.
- 베이지안 방법들은 훈련과정에서 많은 수정이 필요하여 computationally expensive 하며 여러 번 sampling 하는 과정이 필요하다. 그래서 논문에서는 하이퍼 파라미터 튜닝이 별로 필요하지 않고 병렬적으로 실행할 수 있으면서도 uncertainty 추정을 잘하는 non-bayesian방법을 제시한다.
- 베이지안 방법들은 여러 결과를 함께 고려한다는 점이 Ensemble과 비슷하게 보인다. 하지만 Bayesian model averaging(soft model selection)의 경우는 posterior를 잘 근사하였다고 가정하기 때문에 그렇지 않을 경우 결과가 좋지 못하다. 반면 Ensemble(model combination)은 posterior를 잘 근사하지 못해도 좋은 결과를 내며 더욱 robust 한 모델을 얻을 수 있어 논문에서는 이 방법을 사용한다.
2. Deep Ensemble
1번에서는 사전 연구 및 한계점, 개념을 살펴보았고 지금부터는 Ensemble 모델로 어떻게 적절한 predictive uncertainty를 측정할 수 있는지 그 방법론에 대해 기술하겠다.
방법론 기술을 위한 사전 정의는 다음과 같다.
- 학습용 데이터셋 D가 n개의 i.i.d data points로 이루어져 있음. (independently and identically distribution)

- 분류문제에서는 label이 K개의 class로 이루어져 있음.

- 회귀문제에서는 label이 실수로 이루어져있음.

- input feature X가 주어졌을 때 확률예측분포 모델을 반환하는 neural network를 사용함.

자세한 내용에 앞서 이 논문에서 제안하는 방법을 요약하면 다음과 같이 크게 세가지가 있다.
- 학습 기준으로 적절한 scoring rule을 사용
- 예측분포를 smoothing하기 위해 adversarial training 사용
- M개의 모델을 ensemble 하여 사용
1) Proper Scoring Rule
여기서의 scoring rule은 predicitive uncertainty를 측정하는 criterion을 의미한다.
uncertainty가 아닌 accuracy 등 그 nn 성능을 판단하는 지표로는 cross entropy, rmse를 사용했다. 하지만 본 논문의 목표와 같이 uncertainty 측정을 위해 확률예측분포에 대해 numerical score를 계산해 학습과정에서 더 좋은 calibrated prediction을 연산할 수 있다.
calibration prediction은 nn의 uncertainty에 대해 논의할 때 자주 등장하는 용어이다. 정의는 다음과 같고 위에서 들었던 예시에서 0.7을 그대로 반환한다와 같은 의미이다.
- Calibration : 모형의 출력값이 실제 confidence를 반영하도록 만다는 것. input X의 예측 클래스 Y1에 대해 모델의 출력이 0.8일 경우 실제 출력값 및 출력값 해석이 "80% 확률로 Y1을 예측한다" 라는 결과를 가짐.
그렇다면 final output이 어떤 형태여야 calibrated prediction을 수행할 수 있을까?
regression nn 모델의 경우 하나의 mean 값을 연산한다. 하지만 본 논문에서는 regression 경우 한정, nn의 마지막 layer에서 가우시안 분포의 mean과 variance의 제곱을 모두 구해 모델의 예측 분포를 확인하고 그 uncertainty를 확인하는 방법을 제시한다. 이 때 사용하는 loss function은 negative log likelihood(NLL)이다.
수식은 다음과 같다.

NLL을 사용하는 이유는 MSE를 예로 들어 확인할 수 있다. MSE는 proper scoring rule에 해당하지 않는데 variance를 연산하지 못하기 때문이다. NLL로 부터 MSE 유도가 가능하나 이 때 variance가 constant 취급되기 때문에 MSE는 어떤 경우에도 scoring rule이 되지 못한다.
위의 논의는 regression 한정일 경우지만 이미 사용하는 많은 nn loss들도 proper scoring rule이다. 그 예로는 softmax cross entropy loss, Brier score(label을 원핫벡터로 놓고 예측값과 mean squared loss를 구하는 방식) 등이 있다.
2) Adversarial Training
논문에서 제안한 두번째 방법으로 adversarial training이 있고 이는 predictive distribution을 smoothing 한다는 장점이 있다. 더 자세히 살펴보면 다음과 같다.
- Adversarial Training : 데이터셋에 Adversarial Example(사람의 눈에는 이상이 없어도 모델은 전혀 예측하지 못하도록 수정된 데이터)을 포함하여 학습하는 것
- 대표적인 방법으로는 FGSM(fast grdient sign method)이 있음
- FGSM : loss가 증가하는 방향으로 미세한 preturbation(섭동)을 original 데이터셋에 추가하는 방식. 이런 방식이 적용된 데이터들을 학습에 사용하기 때문에 smoothing이 이뤄짐.

3) Ensemble
Ensemble에 대해 간단히 복습해보면 다음과 같다.
- Ensemble : 여러 모델의 결과물을 합쳐 더 성능이 좋은 모델을 만드는 방식
- Randomization : 앙상블을 이루는 개별 모델들이 독립적으로 학습 >> variance 감소 (Random Forest)
- 개별 모델의 정확도와 모델들이 서로 독립적인 error를 내는 것이 중요
- bagging(bootstraping 이용)이 좋은 방식일 수 있으나 강한 임의성을 전제하지 않은 경우에만 가능
- Bootstraping : N개의 sample data를 가지고 있을 때 1000개의 bootstrap samples를 만들고자 하면, 복원 추출을 N번 실행하여 새로운 sample data set을 만들고 이 작업을 1000번 반복.
- Boosting : 앙상블을 이루는 개별 모델들이 순차적으로 학습 >> bias 감소 (AdaBoost)
- Randomization : 앙상블을 이루는 개별 모델들이 독립적으로 학습 >> variance 감소 (Random Forest)

다만 딥러닝 모델 기준으로 생각해보면 bootstraping은 학습 데이터 감소로 인해 성능 저하를 불러올 수 있다. 성능 저하뿐만 아니라 이미 많은 모델에서 minibatch 기반 SGD 알고리즘 / weight random initialization 을 사용하고 있기에 bootstraping의 필요성 또한 존재하지 않는다. 위 기능으로 이미 각 network의 모델들은 독립적인 error를 반환하고 앙상블이 제 기능을 하게 된다.
3. Training & Experiment
1) Training
training을 수행하는 알고리즘은 다음과 같다.

위 수도코드를 살펴보면 proper scoring rule을 설정한 후 ensemble member m에 대해 step 4-6을 반복하게 된다.
2) Experiment Setup
- 이전에서 언급한 NLL을 classification, regression task의 scoring rule로 사용
- classification의 경우, accuracy와 biers score를 추가적으로 계산

- regression에 대해서는 rmse를 추가적으로 계산
- batch size = 100 / optimizer = Adam (lr = 0.1)
- FGSM 파라미터 = original input data' s range * 0.01
- Dataset = 20 Toy Datasets

3) Result

(1) MSE로 학습한 5개 모델의 평균과 분산
(2) NLL로 학습한 1개 모델의 평균과 분산
(3) (2)에 adversarial training 추가
(4) (3)을 5개로 ensemble 한 것 >> 가장 uncertainty를 잘 표현함.

PBP(Probabilistic backpropagation), MC-dropout, Deep ensemble을 비교한 결과이다. 이 때 NLL을 scoring을 사용했을 때 더 좋은 결과를 얻었음을 확인할 수 있다.

ensemble모델에서 그 수가 많아질록 모든 지표에서 더 좋은 결과를 가짐을 알 수 있다. 또한 Deep ensemble이 더 좋은 성능을 보이고 Adversarial training을 적용했을 때 성능이 개선되었다.
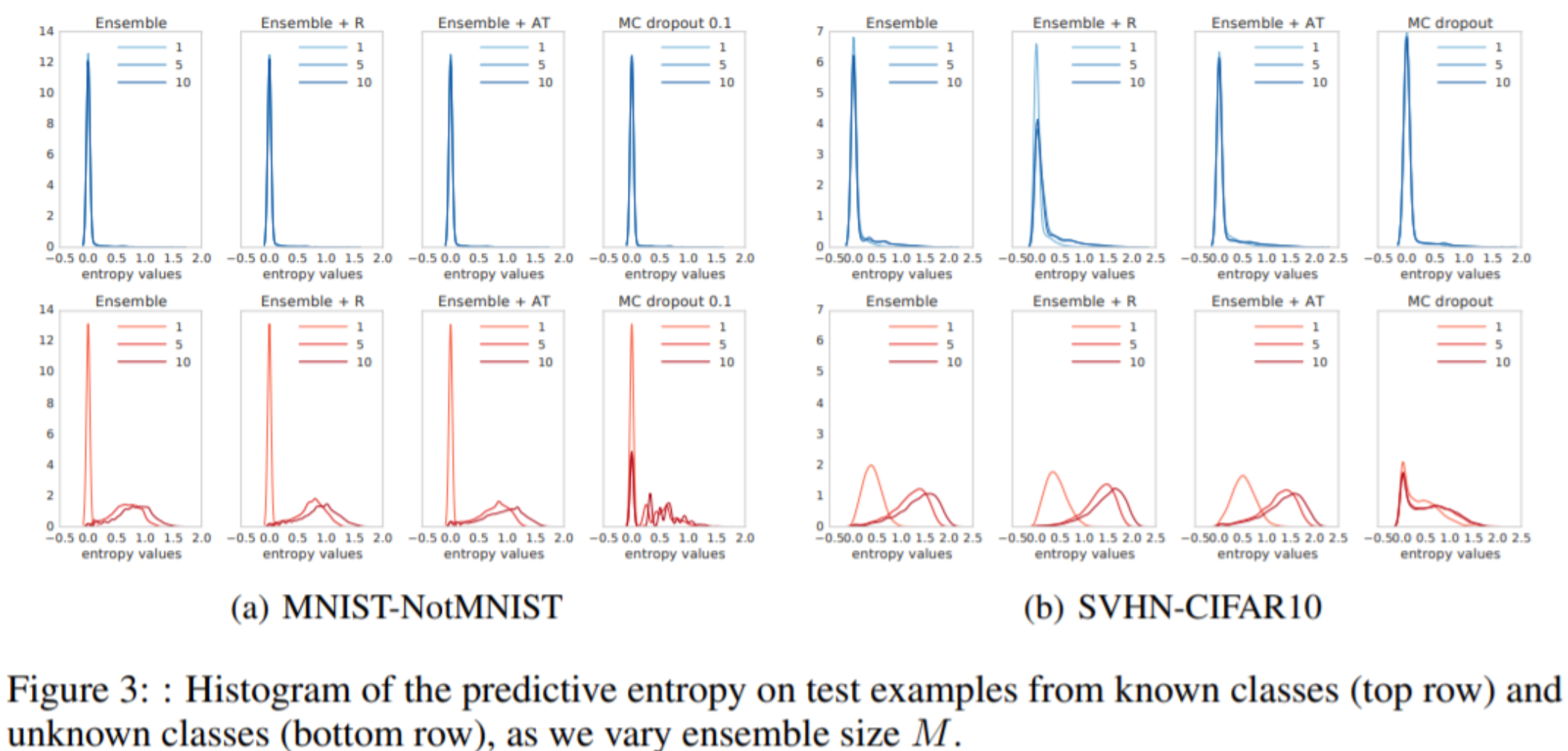
위 실험은 새로운 클래스가 추가되었을 때의 uncertainity를 측정하는 실험이다. MNIST와 Not MNIST / SVHN과 CIFAR10의 쌍과 같이 기존에 학습되지 않은 클래스에 대해 예측하는 실험환경을 세팅하였다.
아래 unknown class에 대한 예측결과를 보면 entropy value가 높을수록 uncertainty를 잘 추정하는 것인데 ensemble 갯수가 많을수록, 그리고 deep ensemble이 MC-dropout보다 좋은 성능을 내고 있음을 알 수 있다.
References
https://www.youtube.com/watch?v=huh4o6iNamo
논문 리뷰: Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles
"Simple and Scalable Predictive Uncertainty Estimation Using Deep Ensembles" (ICML 2017) - DeepMind https://www.edwith.org/bayesiandeeplearning/joinLectures/14426 기존의 연구와 한계, 해결책 딥러닝이..
simpling.tistory.com
'심화 스터디 > Advanced ML & DL paper review' 카테고리의 다른 글
| [Advanced ML & DL Week2] Faster R-CNN (1) | 2022.09.20 |
|---|---|
| [Advanced ML & DL Week1] Semi-supervised Classification with Graph Convolutional Networks (1) | 2022.09.15 |
| [Advanced ML & DL Week1] World Models (1) | 2022.09.15 |
| [Advanced ML & DL Week1] Indexing By Latent Semantic Analysis (0) | 2022.09.15 |
| [Advanced ML & DL Week1] Fast R-CNN (0) | 2022.09.15 |





댓글 영역