고정 헤더 영역
상세 컨텐츠
본문
작성자 : 16기 하예은
본 포스팅은 다음 자료들을 참고하여 작성되었습니다.
- https://hongl.tistory.com/158
- https://pytorch.org/docs/stable/generated/torch.Tensor.backward.html
- https://blog.paperspace.com/pytorch-101-understanding-graphs-and-automatic-differentiation/
1. 문제 상황 정의

gradient를 구하기 위해서는 tensor의 requires_grad인자에 True 값을 부여한 후, backward 함수를 사용해야 한다.

그러나 gradient가 계속 누적되는 현상이 발생한다.
따라서 문제 상황은 'PyTorch에서 backward 함수를 사용했을 때 gradient가 초기화되지 않고 누적되는 현상'이라 할 수 있다.
2. 문제 발생 원인 분석
gradient가 누적되는 현상의 원인을 분석하기 위해 먼저 backward 함수와 grad 함수의 정의를 살펴보았다.


backward 함수와 grad 함수 모두 gradient를 누적하는 성질을 가지고 있었다.

동일한 페이지에서 gradient를 누적하는 방식에 대한 설명을 찾을 수 있었다.

반복문을 사용하여 gradient가 누적되는 현상을 다시 한 번 더 확인하였다.

backward 함수에 대한 Source Code를 읽어보았다. source code 마지막 줄에 accumulate_grad=True라는 내용이 있었고, 이를 통해 Variable._execution_engine.run_backward() 함수에 인자로 전달되는 것을 알 수 있었다. 그러나, backward 함수에는 이에 대한 input 값이 없어서 torch package 사용 시 backward 알고리즘 자체의 수정은 어려울 것으로 생각했다.
그러면 왜 backward 함수는 gradient를 누적하는 성질을 가지고 있는 것일까?
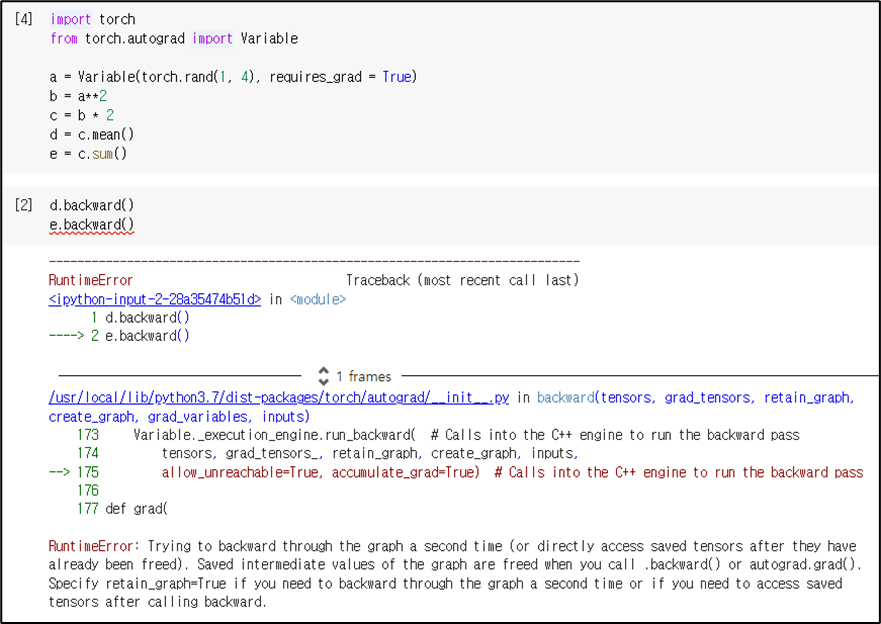
a에 대한 식인 d와 e에 대해서 각각 backward 함수를 적용하면 'Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed)'라는 RuntimeError가 발생한다. 즉 backward 함수는 한 번 적용되면 중간 계산 값들을 지우는 성질을 가지고 있는 것이다. 위와 같은 경우에 에러가 발생하지 않으려면 d.backward(retain_graph=True)로 설정한 다음에 e.backward()를 적용하면 된다.
이러한 backward 함수의 성질로 미루어보아, backward 함수는 중간 계산값들을 지우기 때문에 최종 계산값인 gradient 만은 저장하려는 성질을 가지고 있는 것이 아닐까 추측해보았다.
3. 문제 해결책 제시

gradient가 누적되는 문제를 해결하기 위해서는 grad에 zero_() 메서드를 활용하여 초기화해줘야 한다.
이 외에도 딥러닝 모델이나 optimizer에서는 zero_grad()를 사용할 수 있다.

'심화 스터디 > Dive into Deep Learning' 카테고리의 다른 글
| [Dive into Deep Learning / CNN] Fully connected layer / pooling layer (0) | 2022.11.13 |
|---|---|
| [Dive into Deep Learning / 3주차] Python Class (2) | 2022.09.30 |
| [Dive into Deep Learning / 2주차] PyTorch Automatic Differentiation (1) | 2022.09.25 |
| [Dive into Deep Learning / 2주차] Tensor Manipulation (0) | 2022.09.25 |
| [Dive to Deep Learning/1주차] 딥러닝이란? (What is Deep Learning?) (1) | 2022.09.18 |





댓글 영역