고정 헤더 영역
상세 컨텐츠
본문
작성자 : 16기 윤지현
본 포스팅은 다음 자료들을 참고하여 작성되었습니다.
https://www.datamaker.io/posts/34/
AlexNet 소개 논문
ImageNet Classification with Deep Convolutional Neural Networks
저자 : Alex Krizhevsky, Ilya Sutskever, Geoffrey E.Hinton
https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
1. AlexNet 이란?
AlexNet은 2012년 개최된 ILSVRC(ImageNet Large Scale Visual Recognition Challenge) 대회에서 16.4%의 오차율로 우승을 차지한 CNN 구조이다. 그 당시 2011년 우승 모델의 오차율인 25.8%와 비교하였을 때 성능이 약 40% 좋아진 획기적인 정확도를 가진 모델이었다.
2. AlexNet의 구조

AlexNet은 총 8개의 층으로 이루어져 있으며, 첫 5개의 층은 Convolution, 나머지 3개의 층은 Fully-Connected 층이다. 각각의 층들은 독립적으로 Feature Extraction 하여 가중치를 조절함으로써 필터를 학습시킨다.
Output volume size : (Input width + 2 × padding size - filter size)/stride + 1
- 입력영상
크기: 227×227×3
- 1~2번째 layer
: 1~2층은 Max Pooling 층으로 이를 통해 데이터의 중요한 요소들만 요약하여 추출한다.
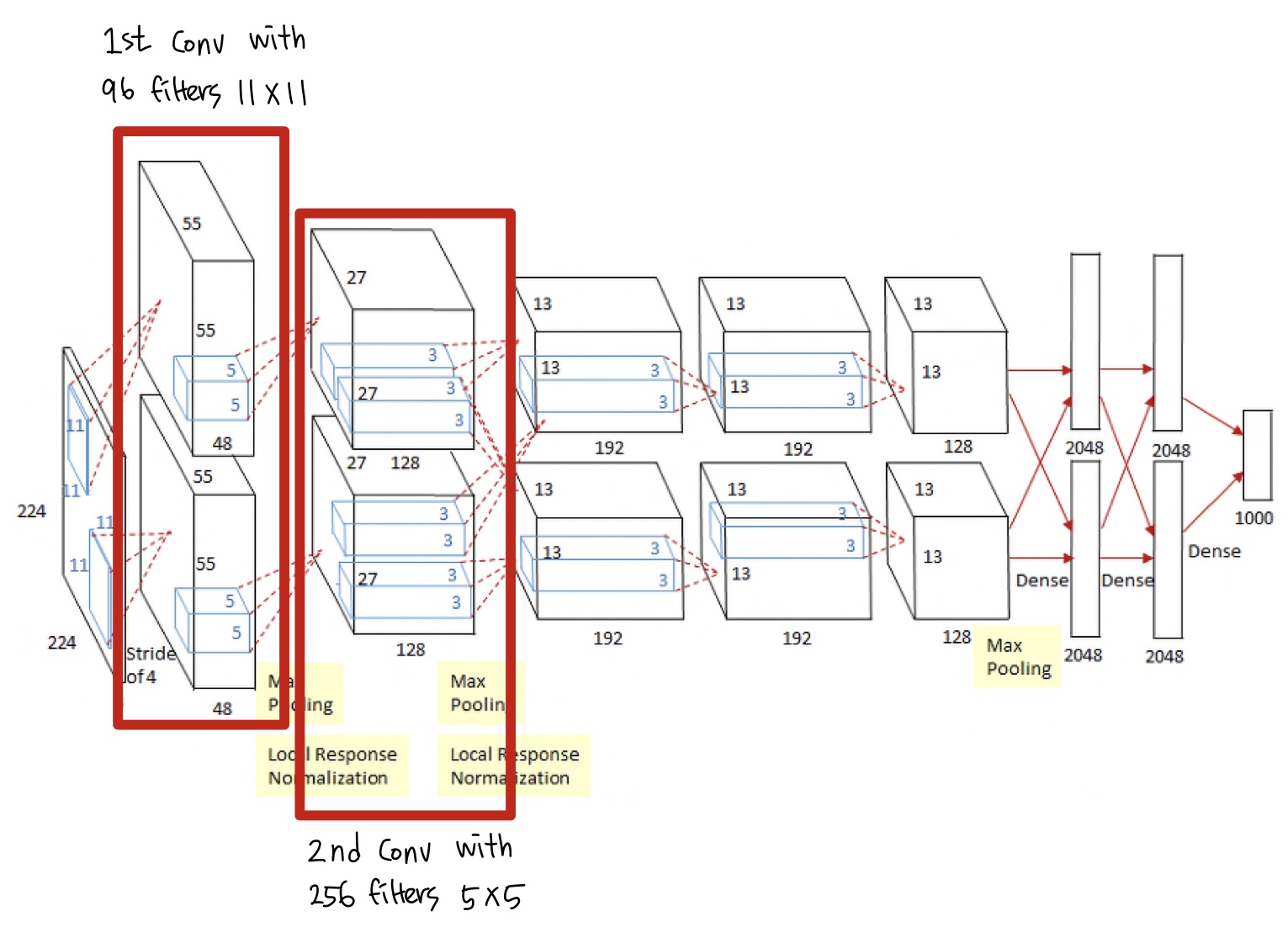
- 첫번째 layer
필터 : 96개의 11×11×3
stride : 4
zero padding : 0
Output : Output volume size 결정식에 의해 (277+2×0-11)/4+1=55 → 55×55×96
- 두번째 layer
필터 : 256개의 5×5×48
stride : 1
zero padding : 2
Output : 27×27×256
- 3~5번째 layer
: 3~5층은 층들을 서로 연결하는 역할을 한다.

- 세번째 layer
필터 : 384개의 3×3×128
stride : 1
zero padding : 1
Output : 13×13×384
→ 이때 세번째 layer는 다른 layer와 다르게 이전 단계의 층으로부터 학습된 필터를 모두 가져오는데, 이는 병렬로 학습된 각각의 필터들이 서로의 연관성이 크게 벗어나는 것을 방지하기 위해 적용되는 것이다.
- 네번째 layer
필터 : 384개의 3×3×192
stride : 1
zero padding : 1
Output : 13×13×384
- 다섯번째 layer
필터 : 256개의 3×3×192 크기의 커널로 Convolution 해준다. 이때
stride : 1
zero padding : 1
Output : 13×13×256
- 6~8번째 layer
5번째 layer 뒤에는 Max Pooling 층이 뒤따르고, 출력은 두개의 Fully Connected layer로 구성된다.

- 최종
최종적으로 1000개의 class label이 있는 Softmax 분류기의 backpropagation을 통해 분류된다.
3. AlexNet의 특징
1) Overlapping Pooling Layer
일반적인 CNN 모델에서의 Pooling은 필터가 서로 겹쳐지지 않도록 stride의 크기를 조절하여 사용되는데, AlexNet에서는 stride 크기를 작게 조절하여 필터가 서로 overlap 되도록 설정해 준다. 이처럼 Overlapping Pooling Layer를 사용하면 정확도가 약 0.4% 향상되지만, 계산량이 증가한다.

2) ReLU Activation Function
ReLU 함수를 사용함으로써 모델의 학습 속도를 증가시켰다.

3) LRN(Local Response Normalization)
ReLU activation function을 적용하기 전에 normalization을 적용시킴으로써 결과값이 특정 값에 의해 영향을 적게 받으면서 일반화된 결과를 도출하기 위해 AlexNet에서 처음으로 도입되었다. LRN은 측면억제를 사용하는 것으로 ReLU 함수를 사용함으로써 양수의 방향으로 입력 값이 그래도 사용되어 Convolution이나 Pooling이 진행될 때 상대적으로 주변에 비해 큰 값을 가지는 하나의 픽셀에 의해 주변 픽셀들이 영향을 받는 것을 방지하기 위해 사용된다.


'심화 스터디 > Dive into Deep Learning' 카테고리의 다른 글
| [Dive into Deep Learning / CNN] Convolution Layer (0) | 2022.11.18 |
|---|---|
| [Dive into Deep Learning/3주차] Optimization Algorithm (0) | 2022.11.16 |
| [Dive into Deep Learning / CNN] Fully connected layer / pooling layer (0) | 2022.11.13 |
| [Dive into Deep Learning / 3주차] Python Class (2) | 2022.09.30 |
| [Dive into Deep Learning / 2주차] Backward Function Problem (0) | 2022.09.25 |





댓글 영역