고정 헤더 영역
상세 컨텐츠
본문 제목
[Advanced ML & DL Week6] Simple Project_Multivariate LSTM-FCNs for Time Series Classification
본문
작성자 : 14기 김태영
논문링크 : Multivariate LSTM-FCNs for Time Series Classification
Multivariate LSTM-FCNs for Time Series Classification
Over the past decade, multivariate time series classification has received great attention. We propose transforming the existing univariate time series classification models, the Long Short Term Memory Fully Convolutional Network (LSTM-FCN) and Attention L
arxiv.org
1. Basic
https://kubig-2022-2.tistory.com/94
[Advanced ML & DL Week5] Multivariate LSTM-FCNs for Time Series Classification
작성자 : 14기 김태영 논문링크 : Multivariate LSTM-FCNs for Time Series Classification Multivariate LSTM-FCNs for Time Series Classification Over the past decade, multivariate time series classification has received great attention. We propose tr
kubig-2022-2.tistory.com
2. Data
다변량 시계열 데이터 분류과제로 사용한 데이터는 아래 Kaggle CareerCon 2019-Help Navigate Robots Competition에서 공개된 데이터이다.
Data Source : https://www.kaggle.com/competitions/career-con-2019
CareerCon 2019 - Help Navigate Robots | Kaggle
www.kaggle.com
(1) Competition Goal : Make sure robot recognize the floor surface they're standing on using data collection from IMU sensors
(2) Task : Predict which one of the nine floor(carpet, tiles, concrete) / using sensor data such as acceleration and velocity
(3) X_Train / Test Specification
- Covering 10 sensor channels and 128 measuremnet per time seires plus three ID columns
- row_id : ID for this row
- series_id : ID number of the measurement series. Foreign key to y_train, sample_submission
- measurement_number : measurement number within thee series
- angular velocity : angle and speed of motion
- linear acceleration components : describes how the speed is changing at different times
- 10 sensor channels
(4) y_train
- series_id : ID number of the measurement series.
- group_id : ID number of all of the measurements taken in a recording session. Provided for the training set only
- surface : the target for this competition
3. Setting
(1) Convert Datatypes
ROOT = '/content/drive/MyDrive/22-2 DL/LSTM-FCN'
SAMPLE = ROOT+'/sample_submission.csv'
TRAIN = ROOT+'/X_train.csv'
TARGET = ROOT+'/y_train.csv'
TEST = ROOT+'/X_test.csv'
ID_COLS = ['series_id', 'measurement_number']
x_cols = {
'series_id': np.uint32,
'measurement_number': np.uint32,
'orientation_X': np.float32,
'orientation_Y': np.float32,
'orientation_Z': np.float32,
'orientation_W': np.float32,
'angular_velocity_X': np.float32,
'angular_velocity_Y': np.float32,
'angular_velocity_Z': np.float32,
'linear_acceleration_X': np.float32,
'linear_acceleration_Y': np.float32,
'linear_acceleration_Z': np.float32
}
y_cols = {
'series_id': np.uint32,
'group_id': np.uint32,
'surface': str
}x_trn = pd.read_csv(TRAIN, usecols=x_cols.keys(), dtype=x_cols)
x_tst = pd.read_csv(TEST, usecols=x_cols.keys(), dtype=x_cols)
y_trn = pd.read_csv(TARGET, usecols=y_cols.keys(), dtype=y_cols)
x_trn.head()
Pytorch Wrapper
- Convert Pandas to Pytorch-specific data types
- Split dataset into training and validation subset and wrap them with dataloader
def create_datasets(X, y, test_size=0.2, dropcols=ID_COLS, time_dim_first=False):
enc = LabelEncoder()
y_enc = enc.fit_transform(y)
X_grouped = create_grouped_array(X)
if time_dim_first:
X_grouped = X_grouped.transpose(0, 2, 1)
X_train, X_valid, y_train, y_valid = train_test_split(X_grouped, y_enc, test_size=0.1)
X_train, X_valid = [torch.tensor(arr, dtype=torch.float32) for arr in (X_train, X_valid)]
y_train, y_valid = [torch.tensor(arr, dtype=torch.long) for arr in (y_train, y_valid)]
train_ds = TensorDataset(X_train, y_train)
valid_ds = TensorDataset(X_valid, y_valid)
return train_ds, valid_ds, enc
def create_grouped_array(data, group_col='series_id', drop_cols=ID_COLS):
X_grouped = np.row_stack([
group.drop(columns=drop_cols).values[None]
for _, group in data.groupby(group_col)])
return X_grouped
def create_test_dataset(X, drop_cols=ID_COLS):
X_grouped = np.row_stack([
group.drop(columns=drop_cols).values[None]
for _, group in X.groupby('series_id')])
X_grouped = torch.tensor(X_grouped.transpose(0, 2, 1)).float()
y_fake = torch.tensor([0] * len(X_grouped)).long()
return TensorDataset(X_grouped, y_fake)
def create_loaders(train_ds, valid_ds, bs=512, jobs=0):
train_dl = DataLoader(train_ds, bs, shuffle=True, num_workers=jobs)
valid_dl = DataLoader(valid_ds, bs, shuffle=False, num_workers=jobs)
return train_dl, valid_dl
def accuracy(output, target):
return (output.argmax(dim=1) == target).float().mean().item()
(2) Cyclic Learning Rate
Cyclic Learning Rate schedulers : known as having positive influence on model's convergence speed
## Simple cosine scheduler
class CyclicLR(_LRScheduler):
def __init__(self, optimizer, schedule, last_epoch = -1):
assert callable(schedule)
self.schedule = schedule
super().__init__(optimizer, last_epoch)
def get_lr(self):
return [self.schedule(self.last_epoch, lr) for lr in self.base_lrs]def cosine(t_max, eta_min = 0):
def scheduler(epoch, base_lr):
t = epoch % t_max
return eta_min + (base_lr - eta_min) * (1 + np.cos(np.pi*t/t_max))/2
return schedulern = 100
sched = cosine(n)
lrs = [sched(t,1) for t in range(n * 4)]
plt.plot(lrs)
4. LSTM Model
class LSTMClassifier(nn.Module):
def __init__(self, input_dim, hidden_dim, layer_dim, output_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.layer_dim = layer_dim
self.rnn = nn.LSTM(input_dim, hidden_dim, layer_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
self.batch_size = None
self.hidden = None
def forward(self, x):
h0, c0 = self.init_hidden(x)
out, (hn, cn) = self.rnn(x, (h0, c0))
out = self.fc(out[:, -1, :])
return out
def init_hidden(self, x):
h0 = torch.zeros(self.layer_dim, x.size(0), self.hidden_dim)
c0 = torch.zeros(self.layer_dim, x.size(0), self.hidden_dim)
return [t.cuda() for t in (h0, c0)]print('Preparing datasets')
trn_ds, val_ds, enc = create_datasets(x_trn, y_trn['surface'])
bs = 128
print(f'Creating data loaders with batch size: {bs}')
trn_dl, val_dl = create_loaders(trn_ds, val_ds, bs, jobs=cpu_count())
5. Training
input_dim = 10
hidden_dim = 256
layer_dim = 3
output_dim = 9
seq_dim = 128
lr = 0.0005
n_epochs = 1000
iterations_per_epoch = len(trn_dl)
best_acc = 0
patience, trials = 100, 0
model = LSTMClassifier(input_dim, hidden_dim, layer_dim, output_dim)
model = model.cuda()
criterion = nn.CrossEntropyLoss()
opt = torch.optim.RMSprop(model.parameters(), lr=lr)
sched = CyclicLR(opt, cosine(t_max=iterations_per_epoch * 2, eta_min=lr/100))
print('Start model training')
for epoch in range(1, n_epochs + 1):
for i, (x_batch, y_batch) in enumerate(trn_dl):
model.train()
x_batch = x_batch.cuda()
y_batch = y_batch.cuda()
sched.step()
opt.zero_grad()
out = model(x_batch)
loss = criterion(out, y_batch)
loss.backward()
opt.step()
model.eval()
correct, total = 0, 0
for x_val, y_val in val_dl:
x_val, y_val = [t.cuda() for t in (x_val, y_val)]
out = model(x_val)
preds = F.log_softmax(out, dim=1).argmax(dim=1)
total += y_val.size(0)
correct += (preds == y_val).sum().item()
acc = correct / total
if epoch % 5 == 0:
print(f'Epoch: {epoch:3d}. Loss: {loss.item():.4f}. Acc.: {acc:2.2%}')
if acc > best_acc:
trials = 0
best_acc = acc
torch.save(model.state_dict(), 'best.pth')
print(f'Epoch {epoch} best model saved with accuracy: {best_acc:2.2%}')
else:
trials += 1
if trials >= patience:
print(f'Early stopping on epoch {epoch}')
break
6. Result
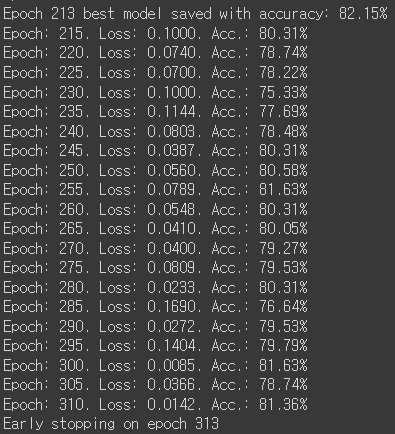
7. LSTM-FCN Architecture


class FCN_model(nn.Module):
def __init__(self,NumClassesOut,N_time,N_Features,N_LSTM_Out=128,N_LSTM_layers = 1
,Conv1_NF = 128,Conv2_NF = 256,Conv3_NF = 128,self.lstmDropP = 0.8,self.FC_DropP = 0.3):
super(FCN_model,self).__init__()
self.N_time = N_time
self.N_Features = N_Features
self.NumClassesOut = NumClassesOut
self.N_LSTM_Out = N_LSTM_Out
self.N_LSTM_layers = N_LSTM_layers
self.Conv1_NF = Conv1_NF
self.Conv2_NF = Conv2_NF
self.Conv3_NF = Conv3_NF
self.lstm = nn.LSTM(self.N_Features,self.N_LSTM_Out,self.N_LSTM_layers)
self.C1 = nn.Conv1d(self.N_Features,self.Conv1_NF,8)
self.C2 = nn.Conv1d(self.Conv1_NF,self.Conv2_NF,5)
self.C3 = nn.Conv1d(self.Conv2_NF,self.Conv3_NF,3)
self.BN1 = nn.BatchNorm1d(self.Conv1_NF)
self.BN2 = nn.BatchNorm1d(self.Conv2_NF)
self.BN3 = nn.BatchNorm1d(self.Conv3_NF)
self.relu = nn.ReLU()
self.lstmDrop = nn.Dropout(lstmDropP)
self.ConvDrop = nn.Dropout(FC_DropP)
self.FC = nn.Linear(self.Conv3_NF + self.N_LSTM_Out,self.NumClassesOut)
def init_hidden(self):
h0 = torch.zeros(self.N_LSTM_layers, self.N_time, self.N_LSTM_Out).to(device)
c0 = torch.zeros(self.N_LSTM_layers, self.N_time, self.N_LSTM_Out).to(device)
return h0,c0
def forward(self,x):
# input x should be in size [B,T,F] , where B = Batch size
# T = Time sampels
# F = features
h0,c0 = self.init_hidden()
x1, (ht,ct) = self.lstm(x, (h0, c0))
x1 = x1[:,-1,:]
x2 = x.transpose(2,1)
x2 = self.ConvDrop(self.relu(self.BN1(self.C1(x2))))
x2 = self.ConvDrop(self.relu(self.BN2(self.C2(x2))))
x2 = self.ConvDrop(self.relu(self.BN3(self.C3(x2))))
x2 = torch.mean(x2,2)
x_all = torch.cat((x1,x2),dim=1)
x_out = self.FC(x_all)
return x_out
References





댓글 영역