고정 헤더 영역
상세 컨텐츠
본문
1. 데이터 로드
https://www.kaggle.com/c/word2vec-nlp-tutorial
Bag of Words Meets Bags of Popcorn | Kaggle
www.kaggle.com
import pandas as pd
train = pd.read_csv('https://raw.githubusercontent.com/corazzon/KaggleStruggle/master/word2vec-nlp-tutorial/data/labeledTrainData.tsv',
header=0, delimiter='\t', quoting=3)
test = pd.read_csv('https://raw.githubusercontent.com/corazzon/KaggleStruggle/master/word2vec-nlp-tutorial/data/testData.tsv',
header=0, delimiter='\t', quoting=3)
unlabeled_train = pd.read_csv('https://raw.githubusercontent.com/corazzon/KaggleStruggle/master/word2vec-nlp-tutorial/data/unlabeledTrainData.tsv',
header=0, delimiter='\t', quoting=3)
print(train.shape)
print(test.shape)
print(unlabeled_train.shape)
print(train['review'].size)
print(test['review'].size)
print(unlabeled_train['review'].size)

train.head()
2. 전처리
import re
import nltk
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup
from nltk.corpus import stopwords
from nltk.stem.snowball import SnowballStemmer
from multiprocessing import Pool
class KaggleWord2VecUtility(object):
@staticmethod
def review_to_wordlist(review, remove_stopwords=False):
# 1. HTML 제거
review_text = BeautifulSoup(review, "html.parser").get_text()
# 2. 특수문자를 공백으로 바꿔줌
review_text = re.sub('[^a-zA-Z]', ' ', review_text)
# 3. 소문자로 변환 후 나눈다.
words = review_text.lower().split()
# 4. 불용어 제거
if remove_stopwords:
stops = set(stopwords.words('english'))
words = [w for w in words if not w in stops]
# 5. 어간추출
stemmer = SnowballStemmer('english')
words = [stemmer.stem(w) for w in words]
# 6. 리스트 형태로 반환
return(words)
@staticmethod
def review_to_join_words( review, remove_stopwords=False ):
words = KaggleWord2VecUtility.review_to_wordlist(\
review, remove_stopwords=False)
join_words = ' '.join(words)
return join_words
@staticmethod
def review_to_sentences( review, remove_stopwords=False ):
# punkt tokenizer를 로드한다.
"""
이 때, pickle을 사용하는데
pickle을 통해 값을 저장하면 원래 변수에 연결 된 참조값 역시 저장된다.
저장된 pickle을 다시 읽으면 변수에 연결되었던
모든 레퍼런스가 계속 참조 상태를 유지한다.
"""
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
# 1. nltk tokenizer를 사용해서 단어로 토큰화 하고 공백 등을 제거한다.
raw_sentences = tokenizer.tokenize(review.strip())
# 2. 각 문장을 순회한다.
sentences = []
for raw_sentence in raw_sentences:
# 비어있다면 skip
if len(raw_sentence) > 0:
# 태그제거, 알파벳문자가 아닌 것은 공백으로 치환, 불용어제거
sentences.append(\
KaggleWord2VecUtility.review_to_wordlist(\
raw_sentence, remove_stopwords))
return sentences
# 참고 : https://gist.github.com/yong27/7869662
# http://www.racketracer.com/2016/07/06/pandas-in-parallel/
# 속도 개선을 위해 멀티 스레드로 작업하도록
@staticmethod
def _apply_df(args):
df, func, kwargs = args
return df.apply(func, **kwargs)
@staticmethod
def apply_by_multiprocessing(df, func, **kwargs):
# 키워드 항목 중 workers 파라메터를 꺼냄
workers = kwargs.pop('workers')
# 위에서 가져온 workers 수로 프로세스 풀을 정의
pool = Pool(processes=workers)
# 실행할 함수와 데이터프레임을 워커의 수 만큼 나눠 작업
result = pool.map(KaggleWord2VecUtility._apply_df, [(d, func, kwargs)
for d in np.array_split(df, workers)])
pool.close()
# 작업 결과를 합쳐서 반환
return pd.concat(result)
KaggleWord2VecUtility.review_to_wordlist(train['review'][0])[:10]
sentences = []
for review in train["review"]:
sentences += KaggleWord2VecUtility.review_to_sentences(
review, remove_stopwords=False)
for review in unlabeled_train["review"]:
sentences += KaggleWord2VecUtility.review_to_sentences(
review, remove_stopwords=False)
len(sentences)
3. 모델링
gensim의 word2vec 모델을 그대로 사용하기 때문에 arguments(parameters)를 잘 설정하는 게 중요



sg: 아키텍처 옵션은 skip-gram (default) 또는 CBOW 모델이다. skip-gram (default)은 느리지만 더 나은 결과를 낸다.
hs : Hierarchical softmax (default) 또는 negative 샘플링
sampling : Google 문서는 .00001에서 .001 사이의 값을 권장한다. 여기에서는 0.001에 가까운 값이 최종 모델의 정확도를 높이는 것으로 보여진다.
vector_size : 많은 feature를 사용한다고 항상 좋은 것은 아니지만 대체적으로 좀 더 나은 모델이 된다. 합리적인 값은 수십에서 수백 개가 될 수 있고 여기에서는 300으로 지정했다.
window : 학습 알고리즘이 고려해야하는 컨텍스트의 단어 수는 얼마나 될까? hierarchical softmax 를 위해 좀 더 큰 수가 좋지만 10 정도가 적당하다.
workers : 실행할 병렬 프로세스의 수로 컴퓨터마다 다르지만 대부분의 시스템에서 4에서 6 사이의 값을 사용하다.
min_count : 어휘의 크기를 의미있는 단어로 제한하는 데 도움이 된다. 모든 문서에서이 여러 번 발생하지 않는 단어는 무시된다. 10에서 100 사이가 적당하며, 이 경진대회의 데이터는 각 영화가 30개씩의 리뷰가 있기 때문에 개별 영화 제목에 너무 많은 중요성이 붙는 것을 피하기 위해 최소 단어 수를 40으로 설정한다. 그 결과 전체 어휘 크기는 약 15,000 단어가 된다. 높은 값은 제한 된 실행시간에 도움이 된다.
# 파라메터값 지정
num_features = 300 # 문자 벡터 차원 수
min_word_count = 40 # 최소 문자 수
num_workers = 4 # 병렬 처리 스레드 수
context = 10 # 문자열 창 크기
downsampling = 1e-3 # 문자 빈도 수 Downsample
# 초기화 및 모델 학습
from gensim.models import word2vec
# 모델 학습
model = word2vec.Word2Vec(sentences,
workers=num_workers,
vector_size=num_features,
min_count=min_word_count,
window=context,
sample=downsampling)
model

4. Testing
# 유사도가 없는 단어 추출
model.wv.doesnt_match('man woman child kitchen'.split())
# 가장 유사한 단어를 추출
model.wv.most_similar("man")
model.wv.most_similar("queen")
model.wv.most_similar("film")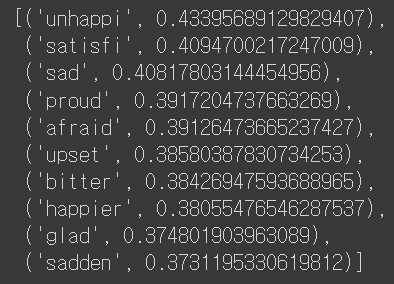
5. 시각화 t-sne
# 참고 https://stackoverflow.com/questions/43776572/visualise-word2vec-generated-from-gensim
from sklearn.manifold import TSNE
import matplotlib as mpl
import matplotlib.pyplot as plt
import gensim
import gensim.models as g
# 그래프에서 마이너스 폰트 깨지는 문제에 대한 대처
mpl.rcParams['axes.unicode_minus'] = False
model_name = '300features_40minwords_10text'
model = g.Doc2Vec.load(model_name)
vocab = list(model.wv.vocab)
X = model[vocab]
print(len(X))
print(X[0][:10])
tsne = TSNE(n_components=2)
# 100개의 단어에 대해서만 시각화
X_tsne = tsne.fit_transform(X[:100,:])
# X_tsne = tsne.fit_transform(X)df = pd.DataFrame(X_tsne, index=vocab[:100], columns=['x', 'y'])
df.shape
fig = plt.figure()
fig.set_size_inches(40, 20)
ax = fig.add_subplot(1, 1, 1)
ax.scatter(df['x'], df['y'])
for word, pos in df.iterrows():
ax.annotate(word, pos, fontsize=30)
plt.show()






댓글 영역