고정 헤더 영역
상세 컨텐츠
본문 제목
[CV 논문 리뷰 스터디 / 1주차 / 장수혁] Faster R-CNN : Towards Real-Time Object Detection with Region Proposal Networks
본문
Abstract
논문 출판 당시 object detection 분야에서의 SOTA 모델은 object의 위치를 가정하는 region proposal algorithm에 의존하였다.
대표적으로 SPPnet과 Fast R-CNN은 region proposal(RP = 영역추정) 계산을 사용하여 이러한 detection networks의 running time을 감소시켰다. 그러나 여전히 RP단계에서 bottleneck현상이 생긴다는 단점이 있었다.
본 논문에서는 RPN(Region Proposal Network)를 소개하는데, 이는 전체 이미지를 convolution 시킨 feature map을 공유하는 네트워크로 RP를 cost 부담없이 사용할 수 있고(nearly cost-free) fully convolutional networks로서 object bounds와 objectness scores를 동시에 각 포지션에서 예측할 수 있다는 장점이 있다.
여기서 중요한 것은 기존 Fast R-CNN에서 수행했던 RP 계산은 그대로 유지하되, 그 계산을 RPN이라는 새로운 네트워크로 진행한다는 것이다. 즉, RPN과 Fast R-CNN을 conv를 거친 feature map을 공유하는 하나의 network로 합친 것에 의의가 있다.(attention mechanism 이용)
논문에서 제시하는 detection system은 backbone으로 매우 깊은 VGG-16 model을 사용하여 GPU 상에서 5fps(초당 5frame 에 해당하는 frame rate)에 도달하였으며, PASCAL VOC 2007, 2012, MS COCO dataset에서 SOTA를 달성하였다.(only 300 proposals per image)
Introduction
Object detecion의 발전은 R-CNN > Fast R-CNN > Faster R-CNN(본 논문에서 제시) 순으로 이어져 왔다.
초기의 R-CNN(Region-based CNN)은 고비용의 모델이었지만, sharing convolutions 기법을 통해 필요한 계산 비용이 대폭 감소하였다. 그보다 진보한 Fast R-CNN은 RP계산에 들어가는 시간을 제외하면 near real-time rates에 도달할 수 있었다.
Region proposal methods 중 가장 유명한 기법인 Selective Search는 engineered된 low-level features를 그룹화한 superpixel들을 greedy하게 병합하는 방법인데 이미지당 2초씩(CPU상)걸리기 때문에 real-time object detection에 적합하지 않다. 이를 개선한 EdgeBoxes는 proposal quality와 speed에 관해 best tradeoff를 제공하여 이미지당 0.2초씩 소요되지만 여전히 부족하다.
Fast R-CNN은 GPU의 장점을 취할 수 있지만, 모델에서 사용되는 RP 계산은 CPU상에서 이루어지는 것도 문제였다. 이를 해결하기 위한 확실한 방법은 GPU 재구현이나, down-stream detection network을 무시하여 sharing computation을 위한 중요한 기회를 놓친다는 문제가 또 발생한다.
본 논문에서는 이러한 문제를 RPN으로 해결하였다. Test time에서 convolutions을 공유하는 것을 통해 계산시간을 이미지당 10ms초로 줄어들게 만들었다. 저자들은 R-CNN, Fast R-CNN에서 사용했던 conv feature map을 RP를 생성하는데에도 사용할 수 있다고 생각하였다. 저자들은 feature map에 각 지점을 정형화된 grid로 나눠 동시에 bounds와 objectness scores를 구할 수 있는 몇 개의 추가적인 conv layers를 쌓아서 RPN을 구축하였다. RPN은 fully convolutional network의 일종이자 detection proposals를 생성하는 것을 end-to-end로 학습할 수 있다.
RPN은 넓은 범위의 scale과 aspect ratio에서도 효과적으로 RP를 예측할 수 있도록 설계되었다.
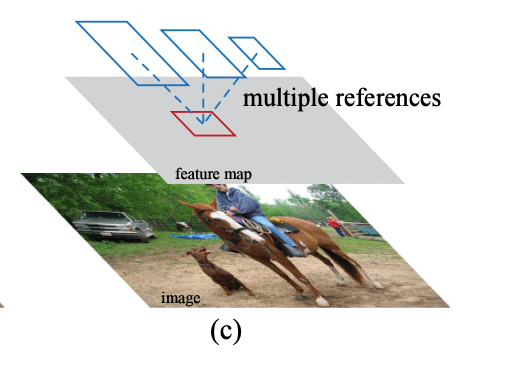
기존의 방법들은 아래 그림처럼 RP를 예측한다. (a)는 다양한 scale의 이미지당 feature map이 대응되고, classifier가 모든 scale에서 돌아가는 방식이다. (b)는 하나의 feature map에 대해 다양한 scale/size를 가진 filter들이 대응되는 개념이다.

저자들은 다양한 scales과 aspect ratios에서 참조로 사용하는 anchor boxes라는 개념을 소개한다. 이것은 regression function안에 reference boxes들이 피라미드식으로 쌓여있는 구조로, 여러 크기의 이미지가 열거되는 것을 막고 single-scale image를 사용해 좋은 성능과 running speed를 보여주었다.
RPN을 Fast R-CNN과 결합하기 위해 저자들은 RP fine tuning과 object detection fine tuning을 번갈아가면서 진행하였다. 이 방식으로 RP와 object detection에서의 convolutional features들을 공유할 수 있는 단일 네트워크를 만들 수 있었으며, 속도도 빨라졌다. PASCAL VOC 데이터 셋에서 실험해 봤을때, RPN과 Fast R-CNN을 결합한 모델(Faster R-CNN)이 Selective Search를 기반으로 한 Fast R-CNN보다 정확도가 높았다. 굉장히 깊은 신경망을 사용해도 GPU상에서 Faster R-CNN은 5fps의 속도를 보여주었다.
즉, 성능과 속도 모두 기존의 모델보다 향상된 것을 알 수 있다. Faster R-CNN은 3D object detection, part-based detection 등 다양한 분야에 적용되고 있으며, 여러 대회에서 수상을 한 모델이다.
Faster R-CNN
Faster R-CNN은 영역을 추정하는 FCN(RPN)과 추정된 영역을 이용하는 Fast R-CNN detector로 이루어져 있다. 전체 시스템은object detection을 위한 하나의 통합된 네트워크로 이루어져 있다. RPN은 attention mechanism처럼 Fast R-CNN detector가 어디에 주목해야 할지를 알려주는 역할을 한다.

1. Region Proposal Networks
RPN은 크기에 상관없이 이미지 전체를 input으로 받고, objectness score와 함께 객체 추정 박스를 반환한다.
저자들은 이 과정을 fully convolutional network에서 일어나게끔 설계하였고, Fast R-CNN의 detector와 RPN이 feature map을 공유할 수 있도록 2개의 모듈이 공통의 conv layer를 가진다는 것을 가정하였다.
RPN은 객체 추정 혹은 영역 추정 박스를 생성하기 위해 슬라이딩 윈도우 방식을 사용한다. 각 슬라이딩 윈도우는 먼저 작은 차원의 features로 매핑된다음, 거기서 구한 features들은 box-regression layer와 box-classficiation layer에 입력된다.
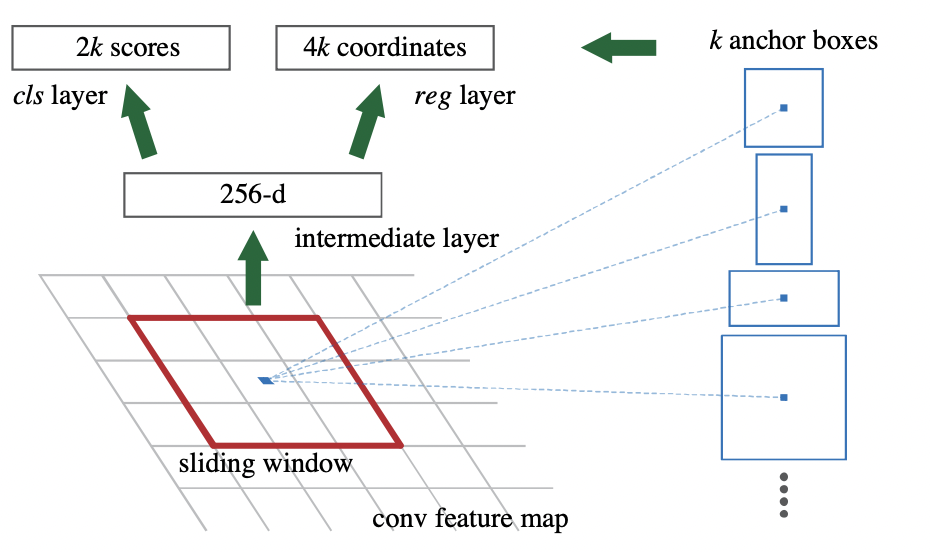
1.1 Anchors
각 슬라이딩 윈도우에서 동시에 여러 영역에 대한 추정이 발생한다. 각 윈도우당 최대 k개의 추정을 할 수 있다. k는 anchor box의 개수와 같다. 경계 박스 하나에는 4개의 좌표값이 있으므로 reg layer는 4k개의 output을 내게 되고, cls layer는 object인지 아닌지, 2개의 클래스에 대한 확률을 추정하기 때문에 2k개의 점수가 나오게 된다.
anchor box는 각 슬라이딩 윈도우의 중심에 위치하며 다양한 scale과 aspect ratio를 가지고 있고 여기서는 default값으로 3 scale, 3 aspect ratio를 사용해 9개의 anchor boxes가 존재한다. conv feature map의 사이즈가 W*H = 2400 일때, anchors box들은 W*H*k 개 만큼 존재한다.
- Translation-Invariant Anchors
- Faster R-CNN에서 중요한 성질 중 하나는 위치 불변성(translation invariant)이다. 이것은 이미지 안에서 객체가 위치가 변하더라도 동일한 객체로 인식하는 성질이다. 만약 객체가 이미지 내에서 움직이게 된다면, 다시 동일한 함수로 변한 위치에 상관없이 추정을 진행한다.
- 반면 MultiBox 기법에서는 이러한 위치 불변성이 보장되지 않는다.
- 위치 불변성 성질은 model size를 줄여주기도 하는데, MultiBoxs (4+1)*800 개의 FC layers를 가진 반면 RPN은 (4+2) * 9(anchor box의 개수 = k) 만큼의 layer만 필요하다. 따라서, MultiBox보다 훨씬 적은 parameters를 가지게 되어 작은 데이터셋에 대한 overfitting이 일어날 확률도 줄어든다.
- Multi-Scale Anchors as Regression References
- Faster R-CNN의 anchors들은 multiple scale과 aspect ratio를 가지고 있다.
- 기존 multi-scale prediction에서는 위의 (a)image/feature pyramids 와 (b)pyramid of filters 방식이 유명했었다.
- 그러나 본 논문에서는 single scale의 image와 feature, single size filter를 사용하고 대신 anchor boxes를 여러 개 활용한다. single scale image에서 계산된 conv features를 추가연산 없이 그대로 사용할 수 있기 때문에 비용적으로 더 효울적이다.
1.2 Loss Function
RPN을 training 할때 저자들은 각 anchor에 binary class label을 할당했다.(object인지 아닌지)
(i)실제 경계 box와의 IoU(합집합 영역 대비 교집합 영역의 비율)가 최대인 anchor, (ii)실제 경계 box와의 IoU가 0.7이상인 anchor의 2가지 경우에 대해 positive label을 부여했다. 여기서 하나의 실제 경계 box가 multiple anchors에 positive label을 할당할 수 있다라는 것이 포인트이다.
보통 (ii)을 따라서 positive label을 부여하지만, 이를 만족하지 않는 경우 (i)의 기준을 사용한다. Negative label은 실제 경계 box와의 IoU가 0.3이하인 anchor에만 부여되고, label을 부여받지 않는 anchor들은 training에서 제외된다. 여기서 Negative label이란 이미지의 배경을 의미한다고 생각하면 된다.

위 그림은 Fast R-CNN의 loss함수로서 크게 classification loss와 regression loss로 나누어져 있다. i는 mini-batch에서의 anchor의 index를 의미한다. 1번은 anchor i가 object일 추정확률, 2번은 실제 label로서 anchor가 positive이면 1, negative이면 0이다.
3번은 예측된 경계 박스의 4개의 좌표값, 4번은 실제 경계 박스의 4개의 좌표값이다. 5번은 object, not object 2개의 클래스간 Logloss이며 6번은 robust loss로 2번이 1일때, 즉 anchor가 positive일 때만 활성화된다. 7,8번은 각각 배치사이즈와 feature map의 grid 수(# of anchor locations)로 나누는 정규화과정이며, 마지막으로 9번은 가중치 파라미터이다. 본 논문에서는 classificatoin loss와 regression loss를 equally weighted 하기 위해 람다를 10으로 설정했다.(7,8번은 각각 256, 2400)
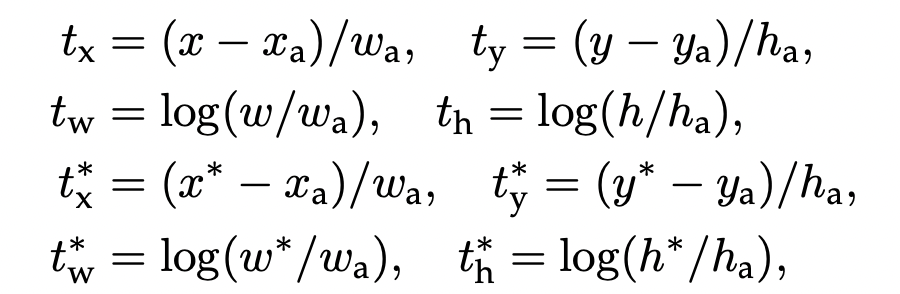
bounding box regression에서 사용되는 파라미터는 위와 같다. x,y는 박스 중심의 좌표이고 w,h는 박스의 width, height이다.
문자 그대로는 predicted box, 문자에 a가 붙어있으면 anchor box, 문자에 *가 붙어있으면 실제 box를 의미한다.
regression은 anchor box에 따라 다르게 진행되는데, k개의 anchor box가 있으면 각각 하나의 scale과 하나의 aspect ratio를 가진 k개의 regressor가 만들어지고, 가중치들은 서로 공유되지 않는다.
1.3 Training RPNs
RPN은 SGD와 back propagation을 통해 end-to-end방식으로 학습될 수 있다. 학습 방식은 기본적으로 'image-centric'을 따른다.
각각의 image들은 많은 positive와 negative anchors들을 가지고 있을텐데, 이미지는 기본적으로 배경이 차지하는 공간 비율이 객체가 차지하는 비율보다 크기 때문에 모든 anchors를 고려해서 최적화하면 negative sample에 편향되는 문제가 발생한다.
따라서, 저자들은 한 image내의 256개의 anchors들을 무작위로 섞고, 최대한 postive : negative 비율을 1 대 1로 맞추는 방식을 이용했다. positive sample이 부족하면 어쩔 수 없이 neagtive sample을 추가한다.
가중치 초기화의 경우 모든 새로운 layer들은 평균 0, 표준편차가 0.01인 가우시안 분포를 이용하였으며, 공유하는 conv 계층은 ImageNet에서 pretrained 된 모델을 사용하였다.
2. Sharing Features for RPN and Fast R-CNN
앞에서 언급했듯, Faster R-CNN은 detector로 Fast R-CNN을 사용한다. Faster R-CNN에서의 중요한 포인트는 RPN과 Fast R-CNN이 convolutional layers를 공유하면서 하나의 단일화된 네트워크로 구성되는 점이다. 원래 이 둘은 독립적으로 훈련되기 때문에, conv layer를 다른 방식으로 변경시킬 수 있다. 이런 점을 해결하기 위해 저자들은 두 개의 네트워크간 conv layer를 공유하면서 훈련할 수 있는 기법을 연구하였다.
Alternating training, Approximate joint training, Non-approximate joint training등 다양한 기법이 연구되었지만 본 논문에서 채택한 방법은 Alternating training이다. 과정을 요약하자면 먼저 RPN을 훈련시킨 후, 추정된 영역을 바탕으로 Fast R-CNN을 훈련시킨다. 다시 tuning된 Fast R-CNN을 바탕으로 RPN을 초기화시킨 후 이것을 반복한다.
저자들은 이것을 바탕으로 4-Step Alternating Training이라는 실용적인 알고리즘을 개발하였다.
- RPN을 ImageNet-pretrained model로 가중치 초기화 시키고, 영역 추정을 위해 end-to-end로 fine tuning된 채로 훈련된다.
- 1에서 generated된 추정 영역을 바탕으로 Fast R-CNN을 훈련시킨다. 가중치 초기화는 역시 ImageNet에서 pretrained 된 모델을 이용한다. 2단계까지는 각자의 네트워크가 공유되지 않는다.
- 2에서 훈련된 detector network를 훈련된 RPN을 초기화하는데 사용한다. 단, shared conv layers는 고정시키고, RPN만 가지고 있는 layer를 fine tuning 시킨다. 이 단계에서 두개의 네트워크가 conv layer를 공유하게 된다.
- 마지막으로 shared conv layers는 고정한 채, Fast R-CNN만이 가지고 있는 layer를 fine tuning한다. 두 개의 네트워크가 동일한 conv layer를 공유한 채, 단일 네트워크를 형성하게 된다.
3. Implementation Details
저자들은 region proposal과 object detection network 모두 single scale image에서 train과 test를 진행하였다.
Image pyramid는 accuracy를 높일 순 있었지만 speed가 떨어졌다. 반면 넓은 범위의 scale 및 aspect ratios를 사용한 anchor box는 성능과 속도 면에서 모두 좋은 모습을 보여주었다.
anchor box는 3 scale(128^2, 256^2, 512^2 pixels), 3 aspect ratio(1:1, 1:2, 2:1)를 갖는 박스들이었는데 아래 그림을 보면 image나 filter pyramid가 없어도 running time을 효과적으로 줄이면서 object detection이 잘 된 것을 알 수 있다.

아래 그림은 각 anchor당 평균 proposal size를 보여주고 있는데, anchor box size보다 큰 객체들도 탐지하고 있다는 것을 알 수 있다.
(proposal의 한 변의 길이가 anchor box의 한 변의 길이보다 긴 경우 존재)

이를 통해, anchor box 안에 객체의 중심부가 포함되면 객체 size가 anchor size를 넘어가도 충분히 영역 추정이 잘 이루어진다는 것을 알 수 있다.
다만, 이미지 경계들을 넘어가는 anchor boxes들은 잘 처리를 해줘야한다. Training에서 저자들은 모든 cross-boundary anchors들을 배제하였다. 일반적으로 1000*600 pixel의 image에는 20000( 60*40*9)개의 anchors가 존재하는데, cross-boundary anchors들을 제외하면 6000개 밖에 남지 않는다. 만약 이것들이 제외되지 않으면 loss함수에 큰 변동이 생기며, training이 잘 되지 않는다.
또한, RPN에서 추정한 영역들이 서로 많이 겹치는 경우가 있는데, 이러한 중복성을 제거하기 위하여 NMS(non-maximum suppression)를 이용하였는데, 이는 경계 박스 가운데 가장 확실한 경계 박스만 남기는 방법이다. 본 논문에서는 cls score가 0.7이상인 경계 박스들에 대해 NMS를 적용하여 이미지당 2000개의 경계 박스만 남게 하였다.(6000개 중 4000개 삭제) 이후에는 detection을 위해 top-N개의 ranked된 proposal regions들을 사용했다. 또한, train에서는 2000개의 proposals를 사용했지만 test에서는 다양한 가지수의 propsals를 사용하였다.(더 늘릴수도, 더 줄일수도 있다)
결론적으로, NMS는 accuracy에 영향을 주진 않았지만 proposals 개수를 현격히 감소시켜 속도 개선을 이뤄냈다.
Conclusion
저자들은 효율적이고 정확한 region proposal generation을 위해 RPN이라는 새로운 네트워크를 도입하였다. detection network와 convolution features를 공유함으로써, RP단계에서 비용이 거의 들지 않았다. 결국 실시간에 가까운 탐지가 가능하고(run at near real-time), 통합된, 딥러닝 베이스의 object detecion system을 구축할 수 있었다(Faster R-CNN). 학습된 RPN은 region proposal quality를 향상시켰으며, 전체적인 object detection accuracy를 높이는 데 기여하였다.
Reference
논문 리뷰 - Faster R-CNN 톺아보기
Faster R-CNN은 기존 Fast R-CNN에 영역 추정 네트워크(RPN)를 더해 속도와 성능을 끌어올린 모델입니다. Faster R-CNN에 와서야 비로소 모든 객체 탐지 구조를 딥러닝으로 훈련할 수 있었습니다. 본 글에서
bkshin.tistory.com





댓글 영역