고정 헤더 영역
상세 컨텐츠
본문 제목
[CV 논문 리뷰 스터디 / 1주차 / 박민규] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
본문
ABSTRACTION
Object detection 분야에서 당시 SPPnet 과 Fast R-CNN 도입으로 성능 올라왔지만, 여전히 region proposal computation에서 bottleneck이 존재하였다.(CPU의 근본적인 한계로 인해)
본 논문에서 Region Proposal Network(RPN)을 제안하였다. RPN은 GPU에서 돌아갈 수 있었기에 region proposal에서의 시간이 단축되었다.
또한 RPN과 Detection network에서 같은 Convolutional feature map을 공유하여 결과적으로 a region proposal에 필요한 computation은 사실상 없기에 추가적으로 시간이 단축되었다.
RPN은 각각의 position에 대한 object bound와 그 position에 object가 존재하는지 여부까지 동시에 예측한다.
STEP1 RPN은 해당 위치에 object가 존재하는지 여부만 판단한다. 여기서 물체의 class가 무엇인지 유추는 하지 못한다.
STEP2 RPN에서 만들어진 위치에 대한 정보를 가져온다(이 위치에 물체가 있을꺼고 대략 어느정도의 크기를 가질꺼야).
STEP3 RPN은 실제로 그 위치에 있은 object가 어떠한 class를 가지는지는 Fast R-CNN에서 사용되었던 detection
network를 사용하여 판단한다.
End-to-end을 위해 RPN과 Fast R-CNN을 하나의 single network로 merge하였다. 앞서 설명했듯이 기본적으로 둘 다 CNN 형태를 지니고 있다면 이미지의 특징을 추출하는 과정은 공유될 수 있다. (feature extractor로서 Convolution layer를 두어서 feature 추출하는 과정 공유가능)
본 논문에서는 RPN을 일종의 attention 메커니즘에 비유하였다.
RPN을 통해 object의 position를 감지하면, 그 position에 있는 사물이 어떤 class인지 맞추는 방향으로 학습이 이루진다.
즉, RPN은 Network가 어디를 봐야한다(attention 해야한다)를 알려주는 역할을 수행한다.
모든 과정이 5fps(초당 5장의 image를 처리)속도를 지닌다.(computation speed 향상) 속도만 빠른 것이 아니라 다른 object detection과 비교했을 때 성능 또한 개선되었다.(accuracy 향상)
Introduction
region-based CNN은 기본적으로 computationally expensive하다는 단점이 있었다.
R-CNN은 region proposal 중에서 method search 방식을 사용하고, 해당 계산이 CPU상 에서 이루어진다. ( 2sec/unit )
따라서 해당 논문에서는 region proposal을 GPU로 탐색하는 RPN를 구상하였다.
CNN 특성상 image의 feature를 추출한 뒤에는 feature가 다양한 network의 input으로 들어갈 수 있다.
region-based detectors(fast R-CNN)에서도 feature map 사용과 동시에 region proposal network에서도 사용할 수 있다. (이때 추가적인 몇개의 convolution layer만 추가하더라도 RPN 구현이 가능하기에 cost free 한 성격을 지닌다)
RPN은 region proposals 예측할 때 다양한 scale과 ratio 가진 box들을 사용하여 진행한다.
anchor-box 방법 : 다양한 reference box 적용하여 예측 진행, 각의 위치마다 다양한 종류의 anchor box 적용(본 논문에서는 9개의 anchor box 사용하였다. 같은 비율이더라도 여러개의 크기로 다르게 적용 가능하는 장점을 지닌다.
RPN와 Fast R-CNN의 object-detection network를 통합하기 위해서 번갈아가면서 학습 진행하여 fine-tuning 진행한다.
RELATE WORK
1. Object Proposals
Selective Search, CPMC, MCG, sliding windows 등으로 탐색을 진행한다.
2. Deep Network for Objective Detection
초창기 R-CNN Network눈 분류모델로 사용되었다.
bounding-box regressor가 포함되었기에 물체가 있을 법한 위치를 조정하는 technique이 존재했지만, 사실상 어느 position에 존재할지에 대해서는 CPU상에서 selective search를 통해 예측되었다. 따라서 region proposal module에 의해서 정확도가 많이 bounding되는 문제가 있었다.
Fast R-CNN은 기본적으로 convolution layer를 share하는 개념은 들어가 있다. 비록 selective search를 CPU상에서 돌리지만, 기존의 R-CNN과는 달리 이미지를 한번만 CNN 모델에 forwarding하면 된다는 장점을 지닌다.
Faster R-CNN은 selective search를 사용하지 않고, Region Proposal을 GPU로 수행하였다는 장점 지녔다.
Faster R-CNN

1) 하나의 image가 주어졌을 때 convolution layer를 거쳐서 feature maps를 뽑아낸다.
2) feature map이 RPN(proposals)과 Fast R-CNN detector(classifier)에 share된다. RPN은 어떤 위치에 물체가 존재 여부를 예측하고, 만약 있다면 어떤 b-box안에 존재하는지까지 예측한다.
3) RPN의 output이 classifier의 input으로 들어가서 각각의 위치에 존재하는 objective가 어떤 class인지 분류한다.
RPN 모듈을 일종의 attention에 비유. classifier에게 bounding된 부분을 더 중점적으로 보라고 알려주는 역할을 수행한다.
1. Region Proposal Network
한 장의 image를 input으로 받아서 bounding-box(rectangular) 형태로 output를 도출해낸다. 각각의 b-box는 그 위치에 물체의 존재여부(objectness score)를 담는다.
RPN은 Fast R-CNN과 feature map을 공유할 수 있다. feature map은 ZF-net , VGG-16 등 다양한 CNN architecture를 사용할 수 있다. (ZF는 VGG-16이전에 흔히 사용하였던 back bone network의 일종이다.)
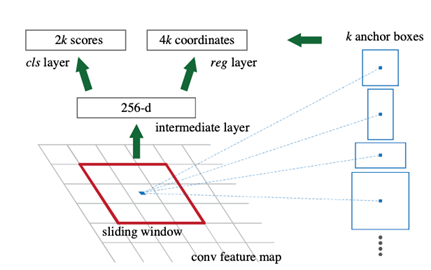
Region proposal 진행 할 때 Convolution layer에 넣어 먼저 convolutional feature map를 뽑는다.
이때 feature map을 n by n 크기의 window로 쭉 sliding하면서 feature map에 각각의 위치에 대해서 prediction 진행한다.
각각의 sliding window는 보다 작은 차원의 feature 형태로 mapping 된다. (feature map은 다양한 크기와 비율을 가지는 anchor box를 지닌다.)
그리고 Feature는 각각 두 종류(box-regression layer, box-classification layer)의 FCN로 forwarding된다.
a. Anchor
각각의 sliding-window의 위치에 따라서, 동시에 다양한 region proposal들을 예측한다. 각각의 위치마다 가능한 k개의 anchor box를 통해서 예측을 진행한다.
1. classification layer : 2k score
b-box에 물체가 존재하는지 여부를 나타낸다. 있을 확률(p) 없을 확률(1-p)에 대한 정보를 softmax 형태로 나타낸다.
2. regression layer : 4k coordinates
만약 물체가 존재한다면 정확히 어떤 위치에 존재하는지를 나타낸다. 물체의 높이, 너비 그리고 중심좌표의 x, y 값에 대한 정보로 물체의 위치를 예측한다.
Translation-Invariant Anchors
faster R-CNN의 특성 : translation invariant하다(translation가 가해지더라도 image가 변하지 않는다.)
Multi-Scale Anchors as Regression References

a) “based on image/feature pyramids”
이미지의 크기를 변경하면서 각각의 scale에 대해서 feature map를 계산해야 하므로 time-consuming하다.
b) “use sliding windows of multiple scales”
다양한 scale에 대해서 sliding window를 적용한다. 해당 방법은 첫번째 방법과 함께 적용된다.
c) Anchor-based method
anchor의 pyramid와 같은 형태로 동작한다. image나 feature map은 한번만 CNN을 통해서 뽑아낸다. 뽑은 뒤 다양한 anchor를 사용하여 처리하기 때문에 매우 효율적이다. 본 논문에서 해당 방법을 채택하였다.
b. Loss Function
RPN을 학습 시킬 때 : 각각의 anchor에 대해서 binary classification을 진행한다.
IoU(Intersection-over-union) :두개의 bounding box가 있을 때 교집합/합집합 의미, 두개의 bounding box가 얼마나 겹쳐있는지 판단하는 지표이다.
IoU가 0.7 이상일때 positive label로 labeling 한다.
하나의 ground-truth box는 여러개의 anchor에 대해서 positive label을 할당 받는 문제와, positive sample 자체가 존재하지 않는 문제가 발생할 수도 있다.
따라서 IoU가 0.3이하일땐 negative label로 labeling하고, 0.3<IoU<0.7의 경우에는 실제 objective function에 영향을 미치지 않도록 처리함으로써 이를 해결한다.

RPN은 기본적으로 분류(cls)와 회귀(reg)를 동시에 가지고 있다. L은 각각의 loss, 학습할 때 cls와 reg를 함께 고려해서 하기에 각각의 L에 대한 가중치가 곱해져 있는 형태로 나타난다.
p*: anchor가 positive일 땐 1, negative일 땐 0 부여 à negative일 때는 reg 파트 무시 (존재할 때만 위치를 regression하는 과정을 진행해야 하므로)
t*: 4가지의 정보(중점의x/y좌표, 높이, 너비)가 tuple형태로)
k개의 anchor는 bounding-box regression을 진행할 때 서로의 가중치를 고려하지 않는다. k개의 anchor가 형태가 다르기 때문에 당연하다.
c. Training RPNs
RPN은 end-to-end 방식으로 학습시킨다. 이때 모든 anchor에 대해서 모두 loss를 반영하지 않고, random하게 256 anchors에 대해서만 loss를 반영한다. positive anchor와 negative anchor의 비율이 1:1이 될 수 있도록 한다. (이상적인 경우 128:128 가 된다.)
CNN 학습할 때 일반적으로 많이 사용하는 hyperparameter setting을 한다. + Faster R-CNN에 맞게
2. Sharing Feature for RPN and Fast R-CNN
Fast R-CNN의 detection network와 RPN에서 feature map을 share하는 방법은 다음과 같다.
Alternating Training
RPN 학습 후 Fast R-CNN detector를 학습한다. 그 후 Fast R-CNN으로 fine-tuning 이루어진 network를 다시 RPN을 학습하기 위해 사용한다. 위의 과정을 반복하며 번갈아가면서 학습 진행한다. 논문에서는 해당 방법을 채택하였다.
Approximate joint training
RPN과 Fast R-CNN network를 완전히 한개의 network로 학습을 진행할 동안 묶어서 사용한다. 구현하기가 쉽지만, 어느정도 approximation된 결과를 얻는다. 정확도는 부족하지만, 학습시간은 빠르다는 장점이 있다.
4-Step Alternating Training
1 step : RPN만 학습을 진행 à end-to-end 방식으로 전체 network에 대해 학습 진행할 수 있도록 한다.
2 step : RPN에서 만들어진 proposal을 이용해서 fast R-CNN detector 학습, 2 STEP까지는 conv layer가 온전히 공유되지 않는다.
3 step : RPN에 포함되지 않는 앞쪽 conv layer는 완전히 고정한 상태에서, RPN에 포함되어 있는 추가적인 conv layer에 대해서만 fine-tuning을 진행
4 step : 앞쪽 conv layer를 완전히 고정한 상태에서 fast R-CNN에만 포함된 layer에 대해서 학습 진행.
이러한 과정을 통해 앞쪽의 conv layer는 RPN과 fast R-CNN이 완전히 공유하게 된다. 4번만 iteration 하더라도 충분하는 결과가 나왔다.
3. Implementation Details
본 논문에서 image 자체의 scale을 바꾸지 않고, single scale에 image에 대해서 region proposal과 objective detection을 사용한다.
box는 각각 128^2, 256^2, 512^2 이렇게 3가지 scale을 가지고, 각각의 scale은 다시 1:1, 1:2, 2:1의 비율을 가진다. 따라서 총 3*3=9개의 anchor box가 생긴다.
image boundary를 cross하는 anchor box에 대해서는 조심스럽게 handling 한다. (cross-boundary anchor를 학습시 제거)
MPS
RPN proposal한 bounding box는 다른 box들과 상당히 많이 overlap될 수 있다. 중복 줄이기 위해(class가 같은 bounding box를 제거하기 위해) non-maximum suppression(NMS)을 사용한다.
NMS를 위한 IoU는 0.7로 설정했다.
Experiments
1. Experiments on PASCAL VOC
PASCAL VOC 2007 dataset : train, valid, test 각각 5,000개의 image를 가지고 있다. (총 15,000개의 image set)
기본적으로 ZF net과 VGG-16 model 각각에 대해서 평가 진행한다.
Ablation Study
특정한 method의 component를 하나씩 제거해보면 해당 component가 얼마나 중요한 역할을 수행하는지 확인

- RPN+ZF, conv layer unsharedà 58.7%이므로 shared 했을때 성능이 더 좋다.
- proposal region의 개수를 바꿔가면서 성능 확인 300>1000>100 순으로 성능 높다. 100개만 사용하더라도 나름 의미 있는 결과가 나왔다.
- cls과 reg layer를 test Time때 각각 빼고 평가 진행. 빼니까 성능이 떨어지는 거슬 볼 수 있다.
- VGG network 사용했을 때가 ZF 사용했을 때보다 더 성능 좋다.
- 07만 사용했을 때보다 07+12를 합쳐 사용한 것이 dataset의 개수가 많기에 mAP(mean Average Precision)이 개선된다.

- Faster R-CNN이 압도적인 속도를 낸다. ZF보다 VGG가 더 깊은 model이므로 속도자체는 더 느리다. CPU기반 SS은 속도가 매우 느리다.
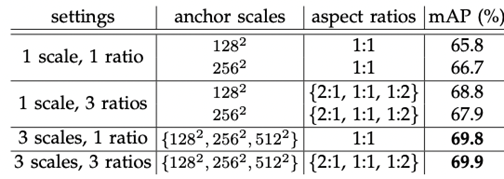
- anchor box을 어떻게 구성하느냐에 따라서 성능이 달라진다. 9개의 anchor 사용시 가장 정확도 증가한다. 다양한 scale, 다양한 ratio를 가지는 anchor box사용시 성능 올라간다.

- 람다값(RPN의 가중치)은 10으로 설정했을 때 충분히 좋은 성능 낸다. 하지만 람다값에 대해서 기본적으로 insensitive하다.

- IoU도 Faster R-CNN이 보다 좋은 성능이 나온다.

- One-stage(location와 class정보를 한번에 예측) 방식보다 Two-stage(물체가 있을 법한 위치를 search 후 class정보 예측) 방식이 더 성능이 좋다.





댓글 영역