고정 헤더 영역
상세 컨텐츠
본문 제목
[논문 리뷰 스터디] BART : Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
본문

작성자: 김지후
1. Introduction
본 논문에서 제시한 BART는 Bidirectional 그리고 Auto-Regressive Transformer의 결합입니다. BART는 denosing autoencoder로 sequence - to -sequence 모델로 만들어져 다양한 태스크에 적용될 수 있습니다.
사전학습에는 두가지 과정이 있습니다.
(1) 텍스트에 임의의 noise로 손상을 줌
(2) sequence-to-sequence 모델을 학습해 원래 텍스트 데이터를 재구성
Transformer 기반의 뉴럴 기계번역 구조를 사용합니다. 이는 bidirectional encoder를 가진 BERT와 left-to-right decoder를 가진 GPT 그리고 다른 최신의 사전학습 구조를 일반화한 것으로 볼 수 있습니다.

이 구조의 핵심 장점은 noising flexibilty입니다. 즉 어떠한 noising 방법도 적용될 수 있다는 것입니다. 다양한 noising 접근법을 검증했을 때, 원래 문장의 순서를 섞는 방법 그리고 특정 구간의 텍스트를 마스크 토큰으로 대체하는 새로운 in-filling 방법이 최고의 성능을 가졌습니다.
BART는 특히 문장 생성과 문장 이해(comprehension task)에 효과적입니다. GLUE와 SQuAD에서 RoBERT와 비교했을 때, abstractive dialogue, question answering, 그리고 summarization task에서 새로운 SOTA를 달성했습니다.
2. Model
BART는 손상된 텍스트를 원래의 텍스트로 매핑해주는 denoising autoencoder입니다. 이 모델은 손상된 텍스트에 대해서 양방향 인코더와 left-to-right 자기회귀 디코더를 사용한 sequence-to-sequence 모델로 시행됩니다. 사전학습을 위해서 원본 텍스트에 대해서 negative log likelihood를 최적화합니다.
2.1 Architecture
- BART는 활성화 함수를 ReLU대신 GeLUs를 사용한 것을 제외하고 기본적인 sequence-to-sequence Transformer 구조를 사용
- base 모델은 인코더와 디코더에 각각 6개의 레이어를 사용
- large 모델은 각각 12개의 레이어를 사용합니다.
이 구조는 BERT에서 사용된 구조와 유사하지만 다른 점은
(1) 디코더의 각 레이어는 추가로 마지막 인코더의 hidden layer에 대해서cross-attention을 수행합니다.
(2) BERT는 단어를 예측하기 전에 추가로 feed-forward network을 사용하지만 BART는 사용하지 않습니다. BART는 BERT보다 약 10% 더 많은 파라미터를 가지고 있습니다.
2.2 Pre-training BART
BART는 손상된 텍스트로 학습되고 reconstruction loss를 디코더의 결과와 원본 텍스트간의 cross-entropy를 사용해 최적화합니다. 이전의 denoising autoencoders와 다르게 BART는 모든 document corruption을 적용할 수 있습니다. 사용한 **변환(transformation)**은 다음과 같습니다.
Token Masking : 랜덤하게 토큰이 선택해 [MASK]로 대체하는 방식. BERT에서 사용함.
Token Deletion : 입력에서 랜덤하게 토큰이 삭제됨. Token masking 방법과 다르게 모델은 어떤 위치가 missing input인지도 맞춰야함.
Text Infilling : 포아송 분포에서 얻은 길이의 text span을 선택해 각 span은 하나의 [MASK]로 대체. Token masking 에서는 하나의 단어만 마스킹 하지만, text infilling 방식은 여러 개의 토큰을 한번에 <MASK> 토큰으로 대체해 얼마나 많은 토큰이 span에서 사라졌는지 학습.
Sentence Permutation : 문서를 문장 단위로 나누고, 랜덤 순서로 문장이 섞임.
Document Rotation : 토큰이 균일하게 랜덤으로 선택되고 문서는 그 토큰으로 시작하도록 회전됨. 이 태스크는 모델이 문서의 시작을 구분하도록 학습.
3. Fine-tuning BART
BART는 하위 태스크에 다양하게 적용되어 사용될 수 있습니다.
3.1 Sequence Classification Tasks
Sequence Classification에서 같은 입력값이 인코더와 디코더에 입력됩니다. 그리고 마지막 디코더 토큰의 hidden state는 새로운 multi classifier에 입력됩니다. 이러한 접근방법은 BERT의 CLS와 관련이 있습니다. 그러나 BART에서는 추가적으로 End 토큰을 사용했습니다.
3.2 Token Classification Task
SQuAD와 같은 Token Classification 에서 완전한 문서를 인코더와 디코더에 입력합니다. 그리고 마지막 디코더의 hidden state를 각 단어의 representation으로 사용합니다. 이 representation은 토큰 분류에 사용됩니다.
3.3 Sequence Generation Tasks
BART는 자기회귀 디코더(autoregressive decoder)를 가지고 있기 때문에, abstractive question answering 그리고 summarization와 같은 sequence generation 태스크에 사용될 수 있습니다. 두 태스크 모두 정보가 입력값으로부터 복제되고 조정되어 denoising pre-training objective와 관련이 있습니다. 인코더의 입력은 입력 시퀀스이고 디코더는 자기회귀적을 결과를 생성합니다.
3.4 Machine Translation
영어로 번역하는 기계번역 디코더에 BART를 사용해 개선을 했습니다. 이전 연구에서는 모델이 사전학습된 인코더와 결합하여 성능이 향상될 수 있음을 보여줬습니다. 본 연구에서 전체 BART 모델(encoder와 decoder 모두)를 기계 번역을 위한 사전 학습된 decoder로 사용합니다. BART의 인코더 임베딩 레이어를 새로운 랜덤하게 초기화된 인코더로 대체합니다. 새로운 인코더는 외국어를 de-noise 가능한 영어로 대체해 학습합니다.
인코더는 2 step에 거쳐 학습합니다. (1) 첫번째 단계에서 대부분의 BART 모수를 고정시키고 오직 랜덤하게 초기화된 source 인코더와 BART positional embedding 그리고 인코더의 첫번째 레이어의 self-attention input projection 행렬을 업데이트 합니다. (2) 두번째 단계에서 모든 모델의 모수를 학습합니다. 두 단계 모두 BART 결과의 cross-entropy loss를 역전파하면서 학습합니다.
4. Comparing Pre-training Objectives
BART는 이전 연구보다 사전학습 과정에서 더 넓은 범위의 noising 구조를 사용할 수 있습니다. base-size model(6개의 인코더, 6개의 디코더, hidden size 768)를 사용해 여러 태스크에 대해서 비교했습니다.
4.1 Comparison Objectives
본 모델을 BERT(books와 Wikipedia data 합친 데이터를 1M step만큼 학습)기반의 다음 모델들와 비교했습니다.
Language Model : GPT와 비슷, left-to-right 트랜스포머 언어모델을 학습. 이 모델은 cross-attention을 하지 않은BART의 디코더와 같다.
Permuted Language Model : XLNet에 기반하고 있다. 토큰의 1/6을 샘플링하고 랜덤한 순서로 자기회귀적으로 생성한다.
Masked Language Model : BERT를 따라, 15%의 토큰을 [MASK]로 대체해 원래 토큰을 예측하도록 모델을 학습한다.
Multitask Masked Language Model : Masked Language 모델을 추가적인 self-attention masks와 함께 학습한다.
Masked Seq-to-Seq : MASS의 영향을 받아 토큰의 50%를 가진 span을 마스크한다. 그리고 sequence to sequence model을 사용해 마스크된 토큰을 예측한다.
4.2 Tasks
SQuAD : extractive question answering
MNLI : bitext classification
ELI5 : long-form abstractive question answering
XSum : news summarization
ConvAI2 : dialogue response generation task
CNN/DM : news summarization
4.3 Results
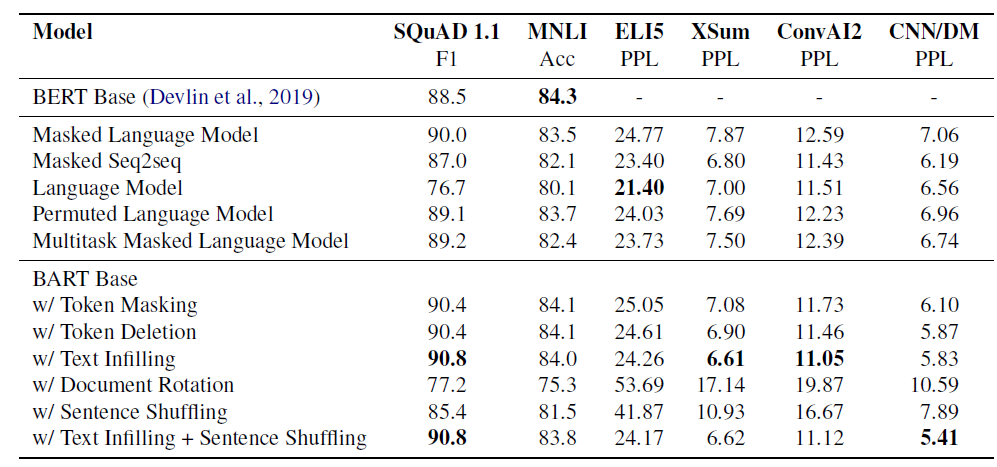
사전학습 방법의 성능이 태스크에 따라 크게 다릅니다. 예를 들어 simple language 모델이 ELI5에서 가장 좋은 성능을 보이지만 SQuAD에서 가장 나쁜 성능을 보입니다. Token masking은 중요했습니다. rotating document나 permuting setences는 상대적으로 성능이 떨어졌습니다. 또한 left-to-right 사전학습은 생성에 성능 향상을 이끌었습니다.
SQuAD에서 양방향 인코더가 중요했습니다. Permuted Language Model은 XLNet보다 낮은 성능을 보여줬는데 이는 relative-position embedding이나 segment level recurrence와 같은 다른 구조적 개선을 포함하지 않아 나타난 것으로 사전학습 objective만이 중요한 것은 아님을 보여줍니다. ELI5 데이터셋은 outlier로 Pure language model일 때 좋은 성능을 보임니다. text-infilling을 사용한 BART가 ELI5를 제외하고 가장 좋은 성능을 보여줘 가장 일관된게 높은 성능을 가진다는 것을 알 수 있습니다.





댓글 영역