고정 헤더 영역
상세 컨텐츠
본문
작성자 : 15기 김제성
0. 통계적 기계번역 SMT (statictical machine translation)

- 번역 모델 - 두 가지 언어로 된 말뭉치에서 alignment를 추출한다 (단어 혹은 구 단위로)

- 언어 모델 - 조건부 확률을 통해 다음에 올 단어들을 예측한다 (기존에 알고 있는 그 language model) (SMT에선 n-gram 이용하기도 함)
- 논문에서는 이 SMT를 비교가 되는 기준 baseline으로 잡았고 BLEU score는 33.30
▶️NMT (Neural machine translation)이 나오기 전까진 기계번역 역시 통계에 기반한 방법론으로 주로 다루어졌다.
1. Introduction
- DNN
- speech recognition, visual object recognition 같은 복잡한 문제들에서 좋은 성능
- modest number of steps에서 parallel 하게 계산 진행 가능
(뒤에 언급될 만큼의 step은 아니고)
- 즉 시퀀스를 갖는 환경 (speech recognition, machine translation, QA)에선 적용하기 어렵다
- 해결책 → LSTM을 두 개 활용하자
- 하나는 - read input sequence (인코더)
- 하나는 - extract output sequence (LM) 이 때 디코더는 input sequence에 conditioned 되었다
- LSTM의 강점은 긴 범위의 temporal dependence에 강하다는 것 ( = input - output 간 time lag를 충분히 버틸 수 있다)
- context vector : 인코더 LSTM의 최종 출력물로 variable length를 갖는 input sentence를 고정된 벡터로 표현하도록 학습이 진행된다.
- 번역은 source 문장을 다른 언어로 paraphrase하는 것이 목표→ 의미를 내포하고 있는 sentence representation을 찾도록 LSTM을 학습시킨다. (비슷한 의미 갖는 문장들끼리는 비슷한 위치 있을 테니까)
2. Model
- RNN
- 장) Input – output간 alignment 있으면 seq-seq 쉽게 매핑시킬 수 있음
- 단) input output 길이가 다른 상황에선 어려움 심지어 그 두 개가 각자 다른 언어라면
그래서 논문에선 RNN 인코더 디코더도 있긴 하지만 long term dependencies 문제점을 방지하고자 LSTM을 활용한다.
LSTM의 목표(objective)는 아래 조건부 확률을 계산하는 것 (LM)

Input sequence로부터 fixed dimensional representation v를 입력받고 (LSTM의 마지막 은닉층에서 나온 = context vector) 그 v를 초기 은닉층으로 받는 LSTM-LM으로 조건부 확률 계산
항상 시퀀스 마지막에 <EOS> 토큰 넣어준다
- 실제 모델 적용 방식
1. 두 개의 서로 다른 LSTM을 쓴다, one for input one for output
- 대략 계산 비용을 무시할 수 있을 정도면서 모델의 파라미터 수를 높여주고
- LSTM이 다양한 언어를 동시에 학습하는 것을 도와준다
2. Deep LSTM - with four layers
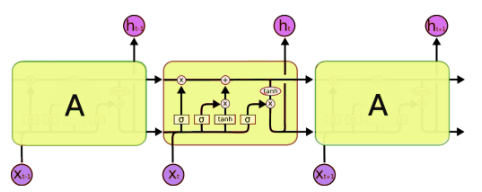
3. 🌟input sentence의 순서를 뒤집어서 넣는다 🌟
- abc -> wyz 가 아닌 cba -> wyz로 집어넣어서 a-w간 위치가 더욱 가까워지게 한다.
- ~ SGD가 인풋과 아웃풋간 communication을 형성할 수 있도록 도와준다 (실제 성능 형성 good) (논문에서 “establish communication”이란 표현이 여럿 나옴)
3. Experiments
- 데이터셋 : WMT’s 14 Eng to Fra ( 12M sentences - 384M french words 304M English words) 그 중 영어 160,000단어 불어 80,000 단어 활용
- 목적함수 ( s - source , t - target)

input sentence가 주어졌을 때 가장 높은 조건부 확률을 갖는 일련의 번역된 문장을 구하는 것이 목표
디코더에서 번역된 단어를 고르는 탐색 기법 : left-to-right beam search
💡 기본적인 seq2seq 디코더에서 사용하는 탐색 방법 : greedy search
- 매 time step마다 softmax해서 나온 가장 높은 값들을 매 time step에서 출력
- 그러면 최종 결과물은 하나로 밖에 귀결이 되지 않음
- 다른 포텐셜한 케이스에 대한 고려는 일절 하지 않게 됨
- Beam search
- size k를 잡아서
- 하나의 노드에서 예측 값의 확률분포가 가장 높은 확률의 노드 k개를 뽑음
- 또 K개에서 각각 높은 확률의 k개 뽑음
- K^2개의 자식 노드 중에서 누적 확률 순으로 상위 K개를 뽑음
- 이게 하나의 step 이고 <EOS> 만날 때까지 step 진행
- size 크게 잡을 수록 성능은 좋아지지만( 더 많은 경우의 수를 고려하니까) 모델이 너무 무거워짐 </aside>
논문에선 size 2가 가장 좋은 효율을 보였다고 하고 있음
- Reverse Source Sentence ~ 논문에서 가장 강조하고 있는 포인트 중 하나
- LSTM의 test perplexity가 5.8 -> 4.7까지 떨어짐. BLEU도 좋은 결과
- 데이터셋에 많은 short term dependencies를 주게 됨 (굳이 긴 메모리를 필요로 하지 않게)
- source 시퀀스 순서를 바꿔줌으로써 input-output 언어간 단어들의 평균 거리가 일정 (unchanged)하게 된다
- 그치만 소스의 앞 단어들과 타켓의 앞 단어들의 위치가 가까워지면서 minimal time lag 문제 해소되고 역전파 학습 과정에서도 더 좋은 성능을 보이게 된다.
- ( minimal time lags : 역전파 학습 과정에서 기울기 소실에 의해서 time lag가 길어지는 상황)
- 긴 문장에서도 잘 적용된 것을 확인할 수 있었다. LSTM의 memory 활용 측면에서도 긍정적 영향 끼침
- Train Detail
- lstm 파라미터 : uniform distribution (-0.08~0.08)로 초기화
- SGD활용, learning rate : 0.7, 7.5 epochs
- 128 batch 활용
- LSTM gradient explode 우려 : gradient norm에 더 강한 threshold
- 대부분 문장 20~30 개의 짧은 문장. 128 배치 잡은 상황에선 낭비 : 미니 배치 안 문장들에 있어서는 다 동일한 길이를 갖도록 조정
- Results

최종 번역 결과물에 대해 2차원 주성분 분석을 한 결과

- 단어의 순서에 있어서는 매우 민감하나
- 문장의 능동-수동 관계에는 덜 민감한 것으로 확인됨
앞으로 논문 리뷰 방향
- 인코더 디코더 / CNN 같이 최신 모델들의 기본 틀이 되는 내용 관련된 논문 읽어보고
- 꼭 논문보면서 직접 layer나 class같은거 짜보는 연습해보기
- 그러고 나서 최신 모델이나 인기있는 모델 논문 살펴보기
- 기회되면 이상치 탐색 or xAI 관련 논문까지도





댓글 영역