고정 헤더 영역
상세 컨텐츠
본문
Advanced ML & DL Week2 - Faster R-CNN
작성자: 15기 박지우
0. Abstract
convolutional layer를 통과하여 feature map를 만든다 이것을 가지고 RPN (여길 보라고 제안하는 것) - Fast RCNN
학습 과정에서 conv features를 공유하도록 (RPN /fast RCNN)

1. 배경
<이전 모델의 한계>
Roi pooling 방식을 이용해 proposal을 convolution 간 공유 -> real-time 근접한 network를 만들어 냈다...!
BUT, selective search 독립적으로 존재함에 따라 시간이 추가로 걸린다 (proposal관련)

a. 첫 번째는 image/feature pyramids ,, 이미지를 다양한 스케일로 resize 하고 feature maps을 각각 scale에 맞춰 계산하는 방식 (기존의 방식) - > 많은 시간이 소요된다는 단점이 있다
b. 두 번째 방식은 다양한 필터를 사용하는 방식 pyramids of filter라고 불리는 데 위의 방식과 혼용해서 쓴다
c. 세 번째 방식은 fater R-CNN에서 쓰는 방식으로 anchor-based-method(pyramid of anchors) 물체가 위치에 있는 박스에 대한 classification과 regression을 모두 anchor box에서 진행하기 때문에 single scale의 이미지 feature map을 기반으로 한다. 한 사이즈의 filter를 사용한다
2. Fast-RCNN
<Idea>
1. region based detector의 convolutional feature map이 region proposal에도 쓰일 수 있다
2. 기존 conv layer에 추가적인 layer를 쌓아서 region proposal regression objectness score 계산을 동시에 해보자
-> selective search 대체함으로써 proposal 10 milliseconds / deep한 모델에도 빠름
몇개의 데이터에서 정확도 측면에서 1위이다
<RPN의 동작>

# anchor - 3*3(논문에서 정함) sliding- window 적용할 때 중심에 anchor를 배치 anchor마다 scale*ratio의 k개 anchor box를 생성 (sliding window 방식으로 fully-connected layer는 모든 공간적 위치를 공유할 수 있다)
input 이미지에 투사
anchor box의 총 개수 = scale * ratio * W * H
# anchor box labeling을 한다 -> prediction의 정답지라고 보면 된다
IoU를 기준으로 positive negative invalid를 정한다 (가장높은 IOU& 0.7이상, 0.3이하, 사이 + 이미지 경계를 벗어난 경우)
invalid는 학습에 사용하지 않는다 -> object labeling
bbox offset labeling (2)
anchor box (x,y h,w) 위치적인 offset를 가져온다 positive인것에 한해서 가져온다
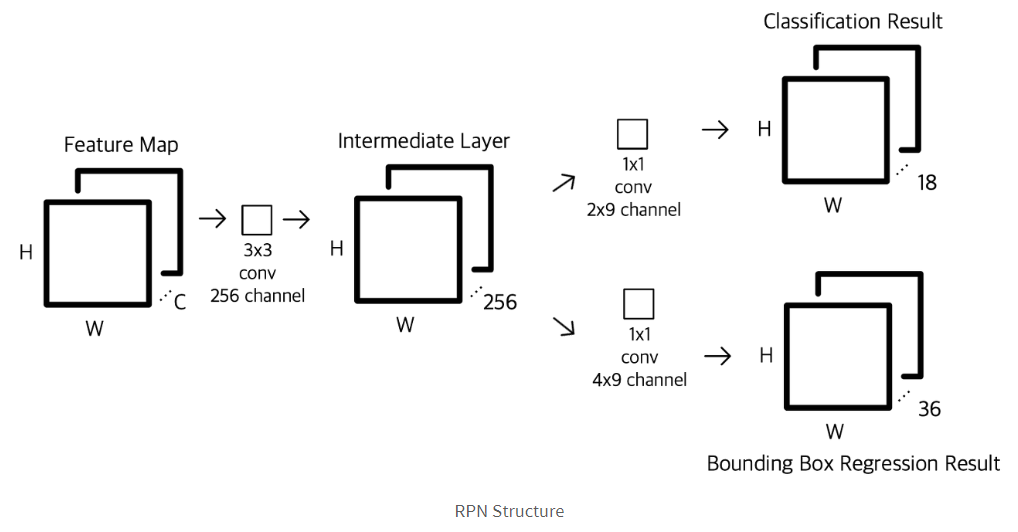
# input 이미지 pretrained 된 conv network(VGG-16)에 forward pass feature map생성
feature map은 3*3(논문에서 정한) sliding window를 적용 패딩(=1) 을 해서 동일한 크기의 feature 생성
# prediction network -결과물을 뱉는 네트워크
feature map 의 1*1 (anchor box 3*3대응) 압축 (objcet 있고 없고) - 9 *2(2-way softmax와 같음)
regression 9*4 (x,y,w,h) 예측
<loss function>
classification : object 있다 없다 - log loss 사용하여 계산
regressor : smooth함수 -> 결국 줄여야 하는 부분 (x-x^*)
anchor 매개체로 사용하여 ground-truth 와 가까운 후보지를 생성
람다값은 하이퍼 파라미터값

<mini batch>
anchor box다 쓰면 네커티브가 많다 그래서 샘플링하여 비율이 1:1되도록 한다
잘 학습이 된 RPN은 GT IoU가 높은 region proposal 만들어 내는 것
<4 step alternating training>
1. RPN을 ImageNet-pre-trained되고 region proposal task를 위해 fine-tuned된 모델을 이용해 initializing을 한다
2. Fast R-CNN에 imageNet-pre-trained된 모델로 초기화를 진행하고 RPN에서 생성된 proposal를 바탕으로
학습시킨다. ** 이 시점까지는 conv layer를 공유하지 않는다
3. detector network를 이용해 RPN training을 초기화하고 공유되는 conv layer는 고정하고 RPN에만 존재하는 layer에 대해서만 fine tuning을 진행한다
4. 마지막으로 공유되는 conv layer를 고정시키고 fast-RCNN에 존재하는 layer만 fine tuning 진행한다
<Faster R-CNN의 이점>
object의 다양한 scale ratio에 대응할 수 있다 - anchor box의 중요성
물체의 translation에 invariant 성질
적은 파라미터 + 오버피팅 확률도 낮춤 multibox에 비해
다양한 스케일 예측을 위해 각각 다른 이미지 필터 scale에 의존
faster RCNN은 동일한 크기 스케일
<More details>
out of boundary boxes 테스트시에는 사용한다 경계를 벗어난것은 clip사용하여 사용
NMS 중복된 후보지를 만들기 때문에 classificationscore값 크고 IOU큰것들 중복된 것들은 제거하는 것
테스트시에는 유동적으로 개수를 정해서 사용할 수 있음
3. Experiments

1.SS(selective search) EB(edgeboxes) 보다 성능 좋게 나옴
2. conv layer 공유가 일어나는 것이 효과가 있는 것인가 - 2단계에서 멈춘 경우 공유가 일어나지 않는데 지표가 하락
-> detection network에 파인 튜닝된 feature가 RPN 또한 파인 튜닝할 때 proposal 정확도가 향상된다는 의미
+ 후보지 개수에 따라 정확도에 차이가 많이 나지 않는다 (100, 6000) -> NMS가 mAP 훼손하지 않는다
3. cls 없앴을 때 NMS 하지 못하고 단순 샘플로 결과를 비교 cls가 정확도 향상에 중요한 역할
reg없앴을 때 또한 감소 - 앵커박스를 예측에 바로 쓴다는 것을 말함
4. ZF net보다 VGG16 성능이 향상
5. VGG16이 낫냐 더 나은 네트워크가 있으면 더 좋은 성능을 가질 수 있다 RPN


6. 하이퍼 파라미터 k값 window 3*3 (다양한 scale ratio로 사용하는 것이 다양한 모습에 반응할 수 있다)
람다 값 reg앞에다가 곱하는 것 reg의 가중치라고 보면 된다

7. one stage - twostage
dense sliding window 로 사용하여
two stage 가 정확도 높긴하지만 욜로 등장하면서 바뀌게 되었다
4. 참고문헌
https://www.youtube.com/watch?v=ZhvU7D_qKO8
[Faster R-CNN]논문 리뷰 (tistory.com)
[Faster R-CNN]논문 리뷰
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Reference https://arxiv.org/abs/1506.01497 Faster R-CNN은 R-CNN, 그리고 Fast R-CNN에 이어 2015년에 발표된 object detect..
uky-note.tistory.com





댓글 영역