고정 헤더 영역
상세 컨텐츠
본문
기존의 seq2seq 모델은 인코더-디코더 구조로 구성되어져 있었다.
여기서 인코더는 입력 시퀀스를 하나의 벡터 표현으로 압축하고, 디코더는 이 벡터 표현을 통해서 출력 시퀀스를 만들어냈다. 하지만 이러한 구조는 인코더가 입력 시퀀스를 하나의 벡터로 압축하는 과정에서 입력 시퀀스의 정보가 일부 손실된다는 단점이 있었고, 이를 보정하기 위해 어텐션이 사용되었다.
어텐션을 RNN의 보정을 위한 용도로서 사용하는 것이 아니라 어텐션만으로 인코더와 디코더를 만들었고 이를 Transformer라 명명했다.
1. Attention Mechanism
RNN에 기반한 seq2seq모델에는 크게 두가지 문제가 있다.
- 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니까 정보 손실이 발생한다.
- RNN의 고질적인 기울기 소실vanishing gradient 문제가 발생한다.
결국 이는 기계 번역 분야에서 입력 문장이 길면 번역 품질이 떨어지는 현상으로 나타났다. 이를 위한 대안으로 input sequence가 길어지면 output sequence의 정확도가 떨어지는 것을 보정하기 위한 기법인 attention이 등장하였다.
1-1 Attention
Decoder에서 출력 단어를 예측하는 매 time-step마다, Encoder에서 전체 입력 문장을 다시 한번 참고한다는 점이다. 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중attention해서 보게 된다.
2-2 Attention Function

Attention function을 함수로 표현하면 다음과 같이 표현된다. ⇒ Attention(Q, K, V) = Attention Value
Attention function은 주어진 Query에 대해서 모든 Key와의 유사도(Score)를 각각 구한다. 그리고 구해낸 이 Score를 Key와 맵핑되어 있는 각각의 ‘Value’에 반영해준다. 그리고 Score가 반영된 Value를 모두 더해서 리턴한다.
여기서는 이 리턴값을 어탠션 값Attention Value라고 한다.
2-3 Dot-Product Attention
Attention은 다양한 종류가 있는데 그 중에서도 가장 수식적으로 이해하기 쉬운 것은 Dot-Product Attention이다.

위 그림은 Decoder의 세번째 LSTM 셀에서 출력 단어를 예측할 때, attention mechanism을 사용하는 모습을 보여준다.
Decoder의 첫번째, 두번째 LSTM 셀은 이미 어텐션 메커니즘을 통해 je와 suis를 예측하는 과정을 거쳤다고 가정하자. Decoder의 세번째 LSTM 셀은 출력 단어를 예측하기 위해서 Encoder의 모든 입력 단어들의 정보를 다시 한번 참고하고자 한다.
1) Attention Score를 구한다.

Encoder의 시점time step을 각각 $1,2,…,N$ 이라고 하였을 때 인코더의 은닉상태hidden state를 각각 $h_1,h_2,...,h_N$라고 하자. Decoder의 현재 time step t에서 디코더의 은닉상태를 $s_t$라고 하자. 또한 디코더와 인코더의 은닉상태의 차원이 같다고 가정하자.
시점 t에서 출력 단어를 예측하기 위해서 디코더의 셀은 두 개의 입력값을 필요로 하는데, 바로 이전 시점인 t-1의 은닉 상태와 이전 시점 t-1에 나온 출력 단어이다. 그런데 Attention Mechanism에서는 출력 단어 예측에 또 다른 값을 필요로 하는데 바로 Attention Value라는 새로운 값이다. t번째 단어를 예측하기 위한 Attention Value를 $a_t$라고 정의하자.
Attention Score란 현재 디코더 시점 t에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 각각이 디코더의 현 시점의 은닉상태$s_t$와 얼마나 유사한지를 판단하는 score값이다.
디코더의 현시점 은닉상태$s_t$ 인코더의 i번째 은닉 상태$h_i$의 어텐션 스코어 함수는 다음과 같다.

닷-프로덕트 어텐션에서는 $s_t$를 전치(transpose)하고 각 은닉 상태와 내적(dot product)을 수행한다. 즉, 모든 어텐션 스코어 값은 스칼라이다.
2) Softmax 함수를 통해 Attention distribution을 구한다.

Attention score의 모음값($e^t$)에 softmax function을 적용하여, 모든 값을 합하면 1이 되는 확률 분포Attention distribution가 나온다. 이때 각각의 값은 Attention Weight라고 한다. 여기서 어텐션 가중치의 분포를 $\alpha^t$라 한다.

3) 각 인코더에 어텐션 가중치와 은닉 상태를 가중합하여 어텐션 값을 구한다.

각 인코더의 은닉 상태와 어텐션 가중치값들을 곱하고 최종적으로 모두 더하는, 가중합Weighted Sum을 진행한다. 그러면 Attention의 최종 출력값이 나오는데 이는 어텐션 값(Attention Value) a_t라고 불린다. a_t는 종종 인코더 문맥을 포함하고 있다고하여, context vector라고도 불린다.

4) 어틴션 값과 디코더의 t 시점의 은닉 상태를 Concatenate한다.
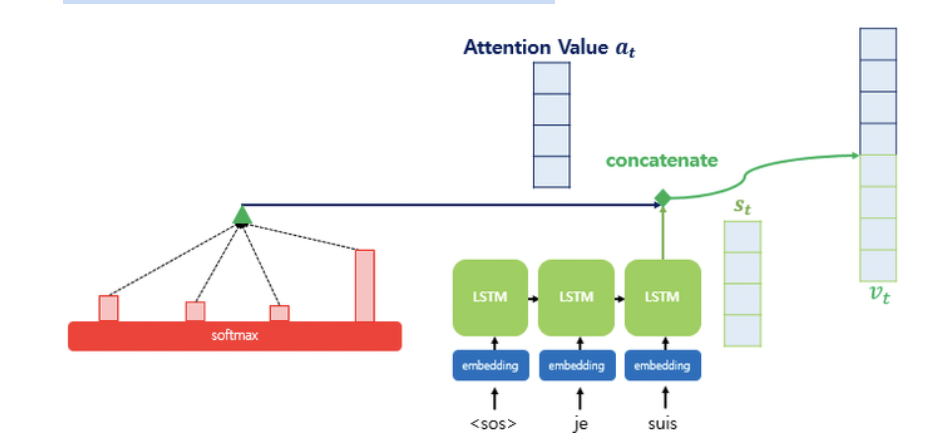
어텐션 값이 구해지면 어텐션 메커니즘은 a_t를 s_t와 결합(concatenate)하여 하나의 벡터로 만드는 작업을 수행한다. 이를 v_t라고 한다. 그리고 이 v_t를 \hat{y} 예측 연산의 입력으로 사용하므로서 인코더로부터 얻은 정보를 활용하여 \hat{y} 를 더 잘 예측할 수 있게 된다.
5) 출력층 연산의 입력이 되는 \tilde{s_t}를 계산한다.

논문에서는 $v_t$를 바로 출력층으로 보내기 전에 신경망 연산을 한 번 더 추가하였다. 가중치 행렬과 곱한 후에 tanh 함수를 지나도록 하여 출력층 연산을 위한 새로운 벡터인 $\tilde{s_t}$를 얻는다. seq2seq에서는 출력층의 입력이 t시점의 은닉상태인 $s_t$였던 반면, Attention mechanism에서는 출력층의 입력이 $\tilde{s_t}$이다.
식으로 표현하면 아음과 같다. $W_c$는 학습 가능한 가중치 행렬, $b_c$는 편향이다.

6) \tilde{s_t}를 출력층의 입력으로 사용한다.
\tilde{s_t}를 출력층의 입력으로 사용하여 예측 벡터를 얻는다.

2. Transformer
Transformer는 RNN을 사용하지 않지만 기존의 seq2seq처럼 인코더에서 입력 시퀀스를 입력받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조를 유지하고 있다. 이전 seq2seq 구조에서는 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점time step을 가지는 구조였다면 이번에는 인코더와 디코더라는 단위가 N개로 구성되는 구조이다.

2-1 Transformer의 주요 Hyperparameter
- $d_{model}$=512
Tranformer의 인코더와 디코더에서의 정해진 입력과 출력의 크기를 의미한다. 임베딩 벡터의 차원 또한 $d_{model}$이며, 각 인코더와 디코더가 다음 층으로 인코더와 디코더로 값을 보낼 때에도 이 차원을 유지한다.
- num_layers=6
Transformer에서 하나의 인코더와 디코더를 층으로 생각하였을 때, 트랜스포머 모델에서 인코더와 디코더가 총 몇 층으로 구성되어 있는지를 의미한다.
- num_heads = 8
Transformer에서 Attention을 사용할 때, 한 번 하는 것보다 여러 개로 분할해서 병렬로 Attention을 수행하고 결과값을 다시 하나로 합치는 방식을 택했다. 이때 병렬의 개수를 의미한다.
- $d_{ff}$=2048
Transformer 내부에는 Feed-Forward Network가 존재하며 해당 신경망의 hidden layer 크기를 의미한다. FFN의 입력증과 출력층의 크기는 $d_{model}$이다.
2-2 Transformer에 쓰이는 Attention

Self-Attention은 인코더에서 이뤄지고, Masked Self-Attention과 Encoder-Decoder Attention은 디코더에서 이뤄진다.
Self-Attention은 본질적으로 Query, Key, Value가 동일한 경우를 말한다. 반면, encoder-decoder attention에서는 Query가 디코더의 벡터인 반면에 Key와 Value가 인코더의 벡터이므로 self-attention이라 부르지 않는다.
3. Transformer 구조
3-1 Input
트랜스포머의 내부 구조를 조금씩 확대해가는 방식으로 트랜스포머를 이해해보자. 우선 인코더와 디코더의 구조를 이해하기 전에 트랜스포머의 입력에 대해서 이해해본다. 트랜스포머의 인코더와 디코더는 단순히 각 단어의 embedding vector를 입력받는 것이 아니라 임베딩 벡터에서 조정된 값을 입력받는데 이에 대해서 알아보기 위해 Input part부터 살펴보겠다.
1) Input Embedding
본격적으로 진행하기 앞서 각각의 input word를 embedding algorithm를 이용하여 vector로 만들어 준다. 이때 embedding vector는 512차원으로 한다.
RNN이 자연어 처리에 유용했던 이유는 단어의 위치에 따라 단어를 순차적으로 입력받아서 처리하는 RNN의 특성으로 인해 각 단어의 위치정보position information을 가질 수 있었기 때문이다.
2) Positional Encoding
하지만 Transformer는 단어 입력을 순차적으로 받는 방식이 아니므로 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있다. 트랜스포머는 단어의 위치 정보를 얻기 위해서 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용하는데, 이를 positional encoding이라고 한다.
Postitional encoding도 단어가 가지고 있는 위치 정보를 완벽히 encoding하지 못함에도 사용하는 이유가 크게 2가지가 있다.
- 해당하는 encoding vector들의 크기들을 동일하게 해준다.
- 두 단어의 거리가 실제 input sequence에서 멀어지게 되면 positional encoding 사이의 거리도 멀어지게 해준다.

임베딩 벡터 내의 각 차원의 인덱스가 짝수인 경우에는 사인 함수를 사용하고 홀수인 경우에는 코사인 함수의 값을 사용한다. 임베딩 벡터 또한 d_{model}의 차원을 가지는데 위의 그림에서는 마치 4로 표현되었지만 실제 논문에서는 512의 값을 가진다.

다음 그림처럼 종종 거리역전이 발생하여 완벽하게 순서를 보존할 순 없지만 두 token 사이의 거리가 얼마만큼 멀리 떨어져 있는가?를 어느정도 반영한다.
3-2 Encoder

Transforemer는 num_layers 개수의 인코더 층을 쌓는다. 논문에서는 총 6개의 인코더 층을 사용하였다. 인코더를 하나의 층이라는 개념으로 생각한다면, 하나의 인코더 층은 크게 총 2개의 sublayer으로 나누어진다.
sublayer는 크게 Multi-head self-attention layer와 Position-wise feed forward neural network layer로 구성되어 있다. Self-Attention은 dependency가 있어 다른 임베딩 벡터에 영향을 받지만, Feed Forward는 dependency가 없어 다른 임베딩 벡터에 영향을 받지 않는다.
3-2-1 Self-Attention
Mutli-head Self-Attention은 Self-Attentino을 병렬적으로 사용하였다는 의미이다.
어텐션이란 어텐션 함수는 주어진 Query에 대해서 모든 Key와의 유사도를 각각 구한다. 그리고 구해낸 이 유사도를 가중치로 하여 Key와 맵핑되어 있는 각각의 Value에 반영해준다. 그리고 유사도가 반영된 Value를 모두 가중합하여 리턴하는 과정을 거친다.
Self-Attention이란 어텐션을 자기 자신에게 수행한다는 의미이다.

it이 무엇을 지칭하는지를 알아내기 위해, 다음과 같이 input sequence의 다른 단어들도 다 훑어가면서 ‘it’과 연관이 있는 단어는 무엇인가?에 대한 답을 구하고자 하는 과정이다. Self-attention은 입력 문장 내의 단어들끼리 유사도를 구하므로서 it이 animal과 연관 되었을 확률이 높다는 것을 찾아내게 해준다.
1) Create Three vectors Q,K,V
Self-attention은 입력 문장의 단어 벡터들을 가지고 수행한다고 하였는데, 사실 self attention은 인코더 초기 입력인 d_{model}의 차원을 가지는 단어 벡터들을 사용하여 셀프 어텐션을 수행하는 것이 아니라 우선 각 단어 벡터들로부터 Q벡터, K벡터, V벡터를 얻는 작업을 거친다.
- Query : Representation of the current word used to score aginst all the other words (다른 단어 scoring하는 기준) - Key : like labels for all the words in the segment
- Value : actual word representations
이때 이 Q,K,V들은 초기 입력인 $d_{model}$의 차원을 가지는 단어 벡터들보다 더 작은 차원을 가지는데, 논문에서는 $d_{model}$=512차원을 가졌던 각 단어 벡터들을 64의 차원을 가지는 Q,K,V 벡터로 변환하였다.
64라는 값은 트랜스포머의 또 다른 하이퍼파라미터인 num_heads로 인해 결정되는데, 트랜스포머는 $d_{model}$=512를 num_heads=8로 나눈 값을 각 Q벡터, K벡터, V벡터의 차원으로 결정하였다.
Student라는 단어 벡터를 Q,K,V의 벡터로 변환하는 과정은 다음과 같다.

2) Calculate a score
Q, K, V 벡터를 얻었다면 지금부터는 기존에 배운 어텐션 메커니즘과 동일하다. 각 Q벡터는 모든 K벡터에 대해서 어텐션 스코어를 구하고, 어텐션 분포를 구한 뒤에 이를 사용하여 모든 V벡터를 가중합하여 어텐션 값 또는 컨텍스트 벡터를 구하게 됩니다. 그리고 이를 모든 Q벡터에 대해서 반복한다.

트랜스포머에서는 어텐션 챕터에 사용했던 내적만을 사용하는 어텐션 함수 $score(q,k)=q⋅k$가 아니라 여기에 특정값으로 나눠준 어텐션 함수인 $score(q,k)=q⋅k/\sqrt{n}$를 사용한다.
이러한 함수를 사용하는 어텐션을 어텐션 챕터에서 배운 닷-프로덕트 어텐션(dot-product attention)에서 값을 스케일링하는 것을 추가하였다고 하여 스케일드 닷-프로덕트 어텐션(Scaled dot-product Attention)이라고 한다.

어텐션 스코어에 소프트맥스 함수를 사용하여 어텐션 분포Attention distribution를 구하고, 각각의 Value(V벡터) 어텐션 값Attention Value를 구했다. 이는 단어 I에 대한 어텐션 값 또는 context vector라고도 할 수 있다.
I뿐만 아니라 am, a, student에 대한 Q벡터에 대해서도 모두 동일한 과정을 반복하여 각각에 대한 어텐션 값을 구한다.

위의 과정을 다음과 같이 벡터 연산이 아니라 행렬 연산을 사용하면 일관 계산이 가능하다.
실제로는 이와같이 행렬 연산으로 구현된다. 각각의 단어의 Q벡터와 K위 그림의 결과 행렬 값에 전체적으로 $\sqrt{d_k}$를 나누어주면 이는 각 행과 열이 어텐션 스코어 값을 가지는 행렬이 된다. 해당 어텐션 스코어 행렬에 softmax 함수를 적용하고, V행렬을 곱하면 각 단어의 어텐션 값을 모두 가지는 어텐션 값 행렬이 결과로 나온다.
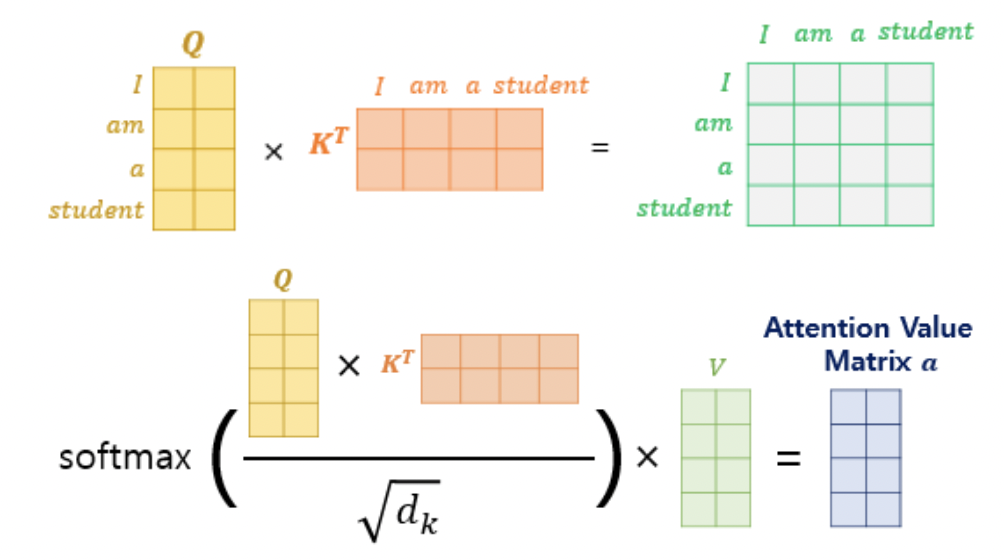

를 적용하여 나오는 어텐션 값 행렬 a의 크기는 (seq\_len,d_v) 가 된다.
3-2-2 Multi-head Self-Attention Layer
논문 기준으로는 512차원의 각 단어 벡터를 8로 나누어 64차원의 Q,K,V 벡터로 바꾸어서 어텐션을 수행하였다. 이제 num_heads의 의미와 왜 d_{model}의 차원을 가진 단어 벡터를 가지고, 어텐션을 하지 않고 차원을 축소시킨 벡터로 어텐션을 수행하였는지를 이해해보겠다.

연구진은 한 번의 어텐션을 하는 것보다 여러번의 어텐션을 병렬로 사용하는 것이 더 효과적이라고 판단하였다. 논문에서는 num_heads의 값을 8로 지정하였고, 8개의 병렬 어텐션이 이루어지게 된다. 다시말해 어텐션이 8개로 병렬로 이뤄지게 되는데, 이때 각각의 어텐션 값 행렬을 Attention head라고 부른다.
(앞선 예제에서 it이 어떤 단어를 볼지 하나의 경우의 수만 허락하는게 아니라 여러개의 경우의 수를 허락해서 다른 시각으로 정보를 수집하겠다 ⇒ Attention head를 여러개 두겠다.)
병렬 어텐션을 모두 수행하였다면 모든 어텐션 헤드를 연결(concatenate)한다. 모두 연결된 attention head 행렬의 크기는 (seq\_len, d_{model})가 된다. 어텐션 헤드를 모두 연결한 행렬은 또 다른 가중치 행렬 W^o을 곱하게 되는데, 이렇게 나온 결과 행렬이 멀티-헤드 어텐션의 최종 결과물이다.

num_heads=8인 mutli-head attention결과는 다음과 같다.

3-2-3 Add & Norm Layer
모든 sub-layer를 통과한 뒤에 Add&Norm Layer를 통과하고, Residual connection과 Normalization을 차례로 진행한다. 아래의 그림과 같이 각각의 positional encoding을 마친 embedding vector X에 대한 self-Attention output 과 통과하기직전 X를 더해준 후(Residual Block), LayerNorm이라는 정규화를 진행한다.

3-2-4 Residual Connection
잔차연결은 서브층의 입력과 출력을 더하는 것을 말한다. Transforemr에서 sublayer의 입력과 출력은 동일한 차원을 갖고 있으므로, 두 벡터는 서로 덧셈 연산이 가능하다.
Residual Connection 연산은 다음과 같다.

3-2-5 Position-wise Feed Forward Neural Network
Position-wise FFNN은 Fully-connected FFNN라고 해석할 수 있다. 다음 그림과 같이 Fully-connect layer, ReLU function, Fully-connected layer 순으로 통과한다. Position-wise FFNN을 수직으로 표현하면 다음과 같다.

여기서 FFNN 내에 있는 W1과 W2의 가중치는 다르지만, z1과 z2에서의 W1끼리 W끼리의 가중치는 같다. 그리고 두번째 FFNN을 거친 후에 최종 출력은 여전히 인코더의 입력 크기였던 (seq\_len,d_{model})의 크기가 보존되고 있다. 하나의 인코더 층을 지난 이 행렬은 다음 인코더 층으로 전달되고, 다음 층에서도 동일한 인코더 연산이 반복된다.
3-3 Decoder
이렇게 구현된 인코더는 총 num_layers만큼의 층 연산을 순차적으로 한 후에 마지막 층의 인코더의 출력을 디코더에게 전달한다. 인코더 연산이 끝났으면 디코더 연산이 시작되어 디코더 또한 num_layers만큼의 연산을 하는데, 이때마다 인코더가 보낸 출력을 각 디코더 층 연산에 사용한다.

3-3-1 Masked multi-head Self-Attention
디코더도 인코더와 동일하게 embedding layer와 positional encoding을 거친 후 문장 행렬이 input으로 들어온다. 하지만, 디코더는 이 문장 행렬로부터 각 시섬의 단어를 예측하도록 훈련된다.
즉, seq2seq의 디코더에 사용되는 RNN 계열의 신경망은 입력 단어를 매 시점마다 순차적으로 입력받으므로 다음 단어 예측에 현재 시점을 포함한 이전 시점에 입력된 단어들만 참고할 수 있다. 반면, 트랜스포머는 문장 행렬로 입력을 한 번에 받으므로 현재 시점의 단어를 예측하고자 할 때, 입력 문장 행렬로부터 미래 시점의 단어까지도 참고할 수 있는 현상이 발생한다. 가령, suis를 예측해야 하는 시점이라고 하면, RNN 계열의 seq2seq의 디코더라면 현재까지 디코더에 입력된 단어는 <sos>와 je뿐이다. 반면, 트랜스포머는 이미 문장 행렬로 <sos> je suis étudiant를 입력받았다.
이를 위해 Transformer의 디코더에서는 현재 시점의 예측에서 현재 시점보다 미래에 있는 단어들을 참고하지 못하도록 look-ahead mask를 도입했다.
룩-어헤드 마스크(look-ahead mask)는 디코더의 첫번째 서브층에서 이루어진다. 디코더의 첫번째 서브층인 multi-head self-attention 층은 인코더의 첫번째 서브층인 multi-head self-attention 층과 동일한 연산을 수행한다. 오직 다른 점은 어텐션 스코어 행렬에서 마스킹을 적용한다는 점만 다르다. 우선 다음과 같이 셀프 어텐션을 통해 어텐션 스코어 행렬을 얻는다.

그 후 자신보다 미래에 있는 단어들을 참고하지 못하도록 다음과 같이 마스킹한다.

마스킹 된 후의 어텐션 스코어 행렬의 가 행을 보면 자기 자신과 그 이전 단어들만을 참고할 수 있음을 볼 수 있다. 그 외에는 인코더부분의 multi-head attention과 근본적으로 동일하다.
3-3-2 Encoder-Decoder Attention
디코더의 두번째 서브층은 멀티 헤드 어텐션을 수행한다는 점에서는 이전의 어텐션들(인코더와 디코더의 첫번째 서브층)과는 공통점이 있으나 이번에는 셀프 어텐션이 아니다.
Self-Attention은 Query, Key, Value가 같은 경우를 말하는데, Encoder-Decoder Attention에서는 Query가 decoder 행렬인 반면, Key와 Value는 인코더 행렬이다.
Query가 디코더 행렬, Key가 인코더 행렬일 때, 어텐션 스코어 행렬을 구하는 과정은 다음과 같다.
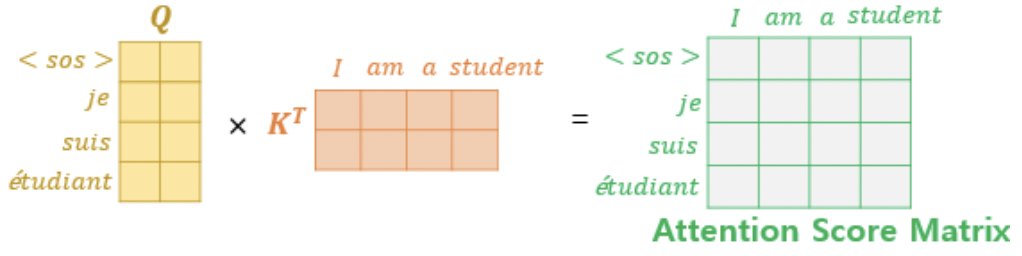
그 외에는 멀티 헤드 어텐션을 수행하는 과정과 근본적으로 같다.
3-4 Output

Decoder stack의 최종 output가 simple fully-connected neural network(Linear Layer)를 통과하게 되면 logit vector가 된다. 이때 vocabulary size만큼의 실수값을 가지게 된다.
logit vector를 확률 스코어로 변환해주는 softmax layer 를 통화하게 되면 각각의 단어마다 확률이 나오게 되는데, 그중 확률값이 가장 큰(argmax)값에 해당하는 단어가 최종 output이 된다.
4 참고 문헌
1) 트랜스포머(Transformer)
* 이번 챕터는 앞서 설명한 어텐션 메커니즘 챕터에 대한 사전 이해가 필요합니다. 트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 Attention i…
wikidocs.net
https://www.youtube.com/watch?v=Yk1tV_cXMMU&feature=youtu.be
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org





댓글 영역