고정 헤더 영역
상세 컨텐츠
본문
0. 개요
Transformer는 입력 시퀀스를 받아서 출력 시퀀스를 벡터로서 표현한다. RNN 모델과 입력 및 출력은 동일하나, 내부 구조에서의 차이가 존재한다. 기존의 RNN에서는 context vector를 앞에서부터 순차적으로 생생하고, 그 context vector를 이후 시점에서 활용하는 방식으로 구현하기 때문에 이후 시점의 연산은 앞 시점의 연산에 의존적일 수 밖에 없다. 따라서, 앞 시점의 연산이 끝나지 않을 경우, 그 뒤의 연산을 수행할 수 없으므로 병렬 처리가 불가능하다. 하지만 Transformer의 경우, attention 개념을 도입하여 모든 과정에 병렬처리가 가능하도록 하였다.
1. Transformer 모델 구조

Transformer의 전체구조는 위의 그림과 같다. input embedding, positional encoding, output embedding 등 부수적인 연산과정들이 존재하지만, 크게 인코더와 디코더로 이루어진다.
2. Input Embedding
입력시퀀스를 embedding algorithm을 활용하여 벡터로 변환하는 작업에 해당한다.
첫번째 인코더의 입력으로서만 사용되는 벡터를 생성하고, 그 이후의 인코더들은 모두 앞선 인코더들의 출력을 입력으로 받게 된다. 즉, input embedding은 앞서 말한 것과 같이 한번만 적용될 뿐더러 모든 벡터들의 사이즈는 동일하게 유지된다. 논문에서는 벡터사이즈로서 512차원을 선정한다. (d_model = 512)
3. Positional Encoding
RNN이 sequential data를 처리하기 용이했던 이유는 데이터의 순서에 따라 순차적으로 입력받아서 처리할 수 있었기 때문이다. 즉, 각 데이터의 위치정보(position information)을 보존할 수 있었다. 그러나, 트랜스포머는 sequential data를 순차적으로 처리하는 것이 아닌 병렬처리하기 때문에, 각 데이터의 순서정보를 임베딩 벡터에 함께 입력해줘야할 필요성이 존재한다. 이를 위한 기법이 Positional encoding이다.

실제로, positional encoding 을 하기 위한 방법으로 논문에서는 두개의 함수를 사용한다. positional encoding을 위한 방법론으로서 고려해야할 사항은 두가지 이다. 먼저, 모든 입력데이터가 부여받는 positional encoding vector의 norm(크기)가 동일해야한다. 두번째로, 두 데이터의 position이 다를 수록, 두 벡터의 거리 또한 증가해야 한다. 이를 만족시키기 위한 함수로서, 저자는 sin과 cos함수를 사용한다.
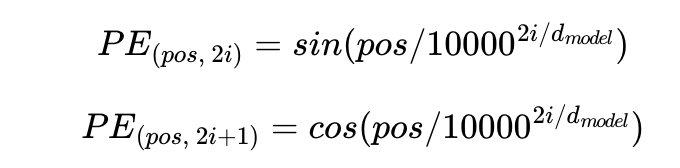
1) 의미정보가 변질되지 않도록 위치 벡터값이 너무 크면 안된다.
-> sin과 cos 함수는 -1 ~ 1 사이를 반복하는 주기함수이기 때문에, 값이 너무 커지지 않는 조건을 만족한다.
2) 같은 위치의 토큰은 항상 같은 위치 벡터값을 가지고 있어야 한다. 하지만, 서로 다른 위치의 토큰은 위치 벡터 값이 서로 달라야 한다.
-> 위치 벡터값이 같아지는 문제를 해결하기 위해, 다양한 주기의 sin과 cos 함수를 동시에 사용한다. 예를 들어, 하나의 위치 벡터가 4개의 차원으로 표현된다면, 각 요소는 서로 다른 4개의 주기를 갖는 함수를 사용하여 표현되기 때문에 겹치지 않는다. 즉,각각의 벡터는 서로 다른 위치 벡터값을 가지게 된다. (아래 그림 참고)

- 왜 concatenate이 아닌 summation 연산을 사용할까?
concat을 할 경우, 단어의 의미 정보는 자체 차원 공간을, 단어의 위치 정보 역시 자체 차원 공간을 갖게 된다. concat의 장점은 정보가 뒤섞이는 혼란을 피할 수 있게 되지만, 단점으로 메모리, 파라미터, 런타임 등과 관련된 비용문제를 피할 수 없다. 트랜스포머 논문이 발표됐을 당시에는 컴퓨팅 파워가 지금만큼 좋지 않아서 concat 대신 summation을 사용했다고 판단된다. 그러나, summation의 경우에도, 모델이 위치 정보를 적절하게 가지면서도 단어 의미 정보 또한 충분히 강력하게 유지하여 벡터 공간에서 단어 간의 표현이 적절할 수 있었을 것이다. 하지만, 위치정보와 의미정보가 섞이는 문제는 본질적으로 피할 수 없다.
트랜스포머 transformer positional encoding
트랜스포머 Transformer Attention is All You Need Postional Encoding
www.blossominkyung.com
4. Encoder
Encoding components는 동일한 encoder block이 하나하나 쌓여 이루어진다. 논문에서는 6개의 block을 쌓았다고 한다. Decoding components 또한 Encoder와 동일하게 6개의 block으로 이루어진다. Encoder block이 어떻게 생겼는지 살펴보면, 앞선 input embedding, positional encoding으로 변환된 vector를 입력으로 받아 self-attention 연산을 취한 뒤, 각각 FFN (Feed Forward Neural Network)를 거쳐 output vector를 출력한다. 이는 또 다시 다음 두번째 encoder vector의 입력으로 들어간다. 먼저, self-attention에 대해서 알아보자.

Self-Attention이란?

위의 문장을 번역하면, '그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다.' 이다. it에 해당하는 것이 길(street) 인지, 동물(animal)인지를 우리 인간은 쉽게 알 수 있지만, 컴퓨터는 이를 알기 어렵다. 셀프 어텐션은 입력 문장 내의 단어들끼리 유사도를 구하여 it이 동물(animal)과 연관되었을 확률이 높다는 것을 찾아낸다.
4-1. Self-Attention mechanism
1단계) Create three vectors from each of encoder's input vectors (Q,K,V)

Query : 현재 시점의 토큰을 의미 ( 대상 token과의 연관성을 찾기 위한 기준 토큰 )
Key : attention을 구하고자 하는 대상 token의 label
Value : 대상 token이 의미하는 실제 데이터 representations
Query, Key, Value는 embedding vector를 각각의 matrix W_Q,K,V를 곱해주어 얻어진다. 각 matrix는 모델을 학습하는 과정에서 가중치가 조정된다. 논문에서는 Q,K,V vector가 64의 dim을 가지게 된다. input vector와 output vector의 크기가 d_model = 512인 점을 고려해보면, 8을 나눈 값에 해당한다는 것을 알 수 있다. 여기서 8을 잘 기억하자. 이는 차후 알아볼 multi_head의 개수에서도 확인할 수 있는 숫자이다.
*note)
일반적으로 input embedding의 dimension 보다는 Query, Key, Value matrix의 dimension을 적게 잡는다. 이는, multihead attention 단계를 통과한 vector들을 concat하여 최종 output으로 쓰기 때문에 차원수를 적게 잡고 다시 합치는 과정으로 이해할 수 있다.
2단계) Calculate a score, how much focus to place on other parts of the input sentences as we encode a word at a certain position
내가 현재 보고 있는 token인 Query와 Query에 중요한 영향을 미치는 token을 판별하기 위한 각 token의 영향 score를 계산한다. 해당 socre는 자기 자신을 포함한 모든 key vector와 현재 Query vector를 dot product하여 구할 수 있다.

3단계) Divide the score by root d_k (=8 in the original papaer since d_k = 64)
Transformer Networks: A mathematical explanation why scaling the dot products leads to more stable…
How a small detail can make a huge difference
towardsdatascience.com
4단계) Pass the result through a softmax operation
5단계) Multiply each value vector by the softmax score
6단계) Sum up the weighted value vector which produces the output of the self-attention layer at this position

최종적으로 현재 보고있는 Query 'Thinking'에 어떤 단어들이 높은 관련성을 가지는지에 대한 정보를 담은 vector값을 위와 같은 6단계를 통해 산출할 수 있다.
4-2. Multi-headed Attention
Multi-headed Attention에서는 4-1에서 보았던 self attention mechanism을 하나의 관점이 아닌 여러개의 관점에서 허용한다는 것을의미한다. 논문에서는 multi-head를 8개 선정하여 attention score를 8개의 다른 attention head에서 seperately하게 산출한다.

4-3. Position-wise Feed-Forward Networks

Encoder와 Decoder 동일하게 multi-head attention layer를 거친 후에는 FFNN 층을 지난다. FFNN은 Fully connected layer로서, 각각의 vector에 따로따로 적용한다. 기본적으로 ReLU fucntion의 형태를 가지며, 파라미터는 위의 식과 같다. 여기서 x는 앞서 멀티 헤드 어텐션의 결과로 나온 (seq_len, d_model)의 크기를 가지는 행렬을 의미한다. 가중치 행렬 W1은 (d_model, d_ff)의 크기를 가지고, 가중치 행렬 W2은 (d_ff, d_model)의 크기를 가진다. 논문에서 은닉층의 크기인 d_ff는 2,048의 크기를 가진다.
여기서 매개변수 W1, b1, W2, b2는 하나의 encoder block 내에서는 동일한 값을 가지지만, 다른 sublayer의 인코더 층마다는 다른 값을 가진다.

5. Decoder
5-1. Teacher Forcing

Teacher Forcing은 실제 labeled data(Ground Truth)를 RNN cell의 input으로 사용하는 것이다. 정확히는 Ground Truth의 [:-1]로 slicing을 한 것이다 (마지막 token인 EOS token을 제외). 이를 통해서 model이 잘못된 token을 생성해내더라도 이후 제대로 된 token을 생성해내도록 유도할 수 있다. 하지만 이는 model 학습 과정에서 Ground Truth를 포함한 dataset을 갖고 있을 때에나 가능한 것이기에 Test나 실제로 Real-World에 Product될 때에는 model이 생성해낸 이전 token을 사용하게 된다. 이처럼 학습 과정과 실제 사용에서의 괴리가 발생하기는 하지만, model의 학습 성능을 비약적으로 향상시킬 수 있다는 점에서 많은 Encoder-Decoder 구조 model에서 사용하는 기법이다.
https://cpm0722.github.io/pytorch-implementation/transformer
[NLP 논문 구현] pytorch로 구현하는 Transformer (Attention is All You Need)
Paper Link
cpm0722.github.io
5-2. Masked Multi-head Attention
병렬 연산을 위해 ground truth의 embedding을 matrix로 만들어 input으로 그대로 사용하게 되면, Decoder에서 Self-Attention 연산을 수행하게 될 때 현재 출력해내야 하는 token의 정답까지 알고 있는 상황이 발생한다. 따라서 masking을 적용해야 한다.

5-3. The Final Linear and Softmax Layer
- Linear layer : fully connected neural network로서 앞선 decoder에 의해 산출된 벡터를 하나의 긴 logits vector를 출력
- Softmax layer : 각각의 input vector 값이 가지는 확률 값 계산 (argmax를 거쳐서 the highest probability를 가지는 cell이 선택된다 : the word associated with it is produced as the output of this time step)
6. 코드 구현
개인적으로는 NLP에 관심이 없어서 Transformer를 활용한 시계열 모델을 만들어보았다. (한국가스공사에서 진행중인 가스수요예측 공모전을 진행하면서, 구현한 코드이긴 하지만) 이번에 리뷰한 논문 <Attention is all you need,2017> 과 <Deep Transformer Models for Time Series Forecasting : The Influenza Prevalence Case, 2020> 의 코드를 구현한 아래 글을 참고하였다.
How to make a PyTorch Transformer for time series forecasting
This post will show you how to transform a time series Transformer architecture diagram into PyTorch code step by step.
towardsdatascience.com
https://github.com/KasperGroesLudvigsen/influenza_transformer
GitHub - KasperGroesLudvigsen/influenza_transformer: PyTorch implementation of Transformer model used in "Deep Transformer Model
PyTorch implementation of Transformer model used in "Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case" - GitHub - KasperGroesLudvigsen/influenza_transfor...
github.com
Additional Reference)
https://www.youtube.com/watch?v=Yk1tV_cXMMU&t=1492s





댓글 영역