고정 헤더 영역
상세 컨텐츠
본문 제목
[CV 논문 리뷰 스터디 / 5주차 / 최경석 ] Attention is All You Need, Transformer (NIPS 2017)
본문
https://arxiv.org/abs/1706.03762
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
1. 개요
많은 딥러닝 모델, 특히 자연어 처리 분야의 모델들은 Transformer의 아키텍쳐를 기반으로 한다
GPT : Transformer의 Decoder 활용
BERT : Transformer의 Encoder 활용
1-1. 기존 모델(RNN 계열)들의 한계
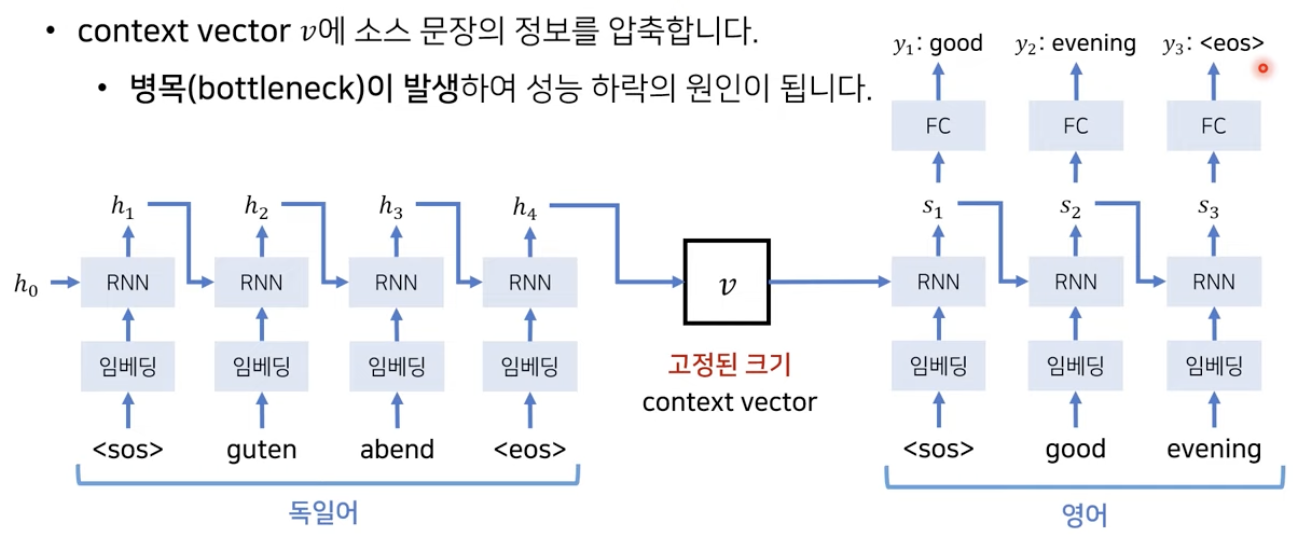
Seq2Seq
- 고정된 크기의 context vector에 소스 문장의 정보 압축
- Bottleneck 현상이 발생하여 성능 하락
- context vector를 Decoder에서 추가해서 사용하더라도 고정된 크기를 사용한다는 한계는 극복X
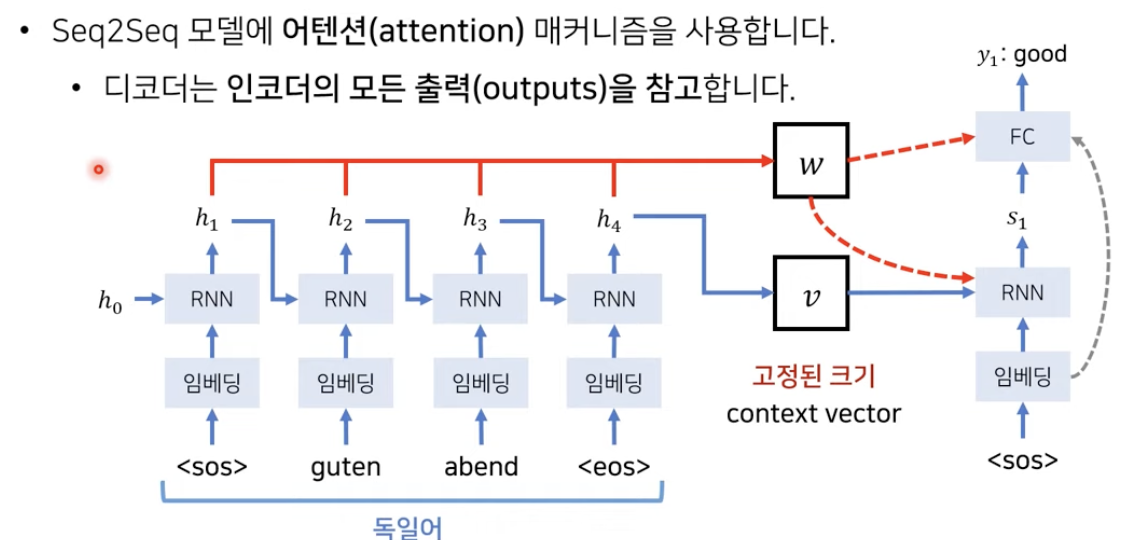
Seq2Seq with Attention
- 기존 Seq2Seq는 하나의 context vector가 문장의 모든 정보를 담기 때문에 성능이 저하
- 문장에서 나오는 각각의 출력을 입력으로 받는다면??
- 매 단어가 들어올떄 생기는 hidden state 값을 별도의 배열에 저장 후 Decoder에서 단어를 생성할 떄에 출력값들을 참조 (단어에 따른 가중치 계산)
2. Transformer 구조
2-1. 개괄
Transformer는 Attention만을 사용해서 encoder과 decoder을 구성한 모델
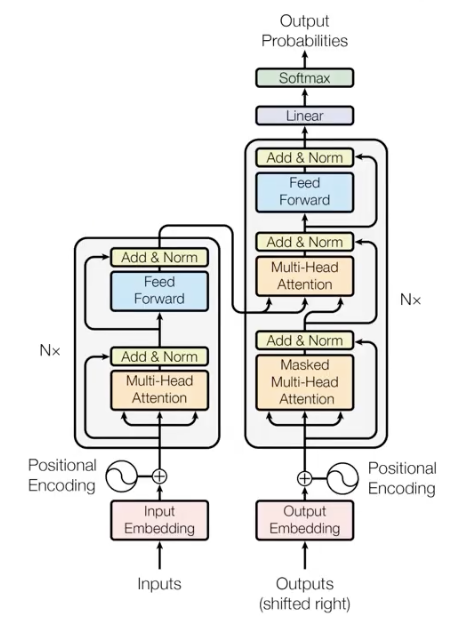
1) Input Embedding & Positional Encoding
2) Encoder block
- 본 논문에서는 6 layer의 Encoder 사용
- 한번에 모든 sequence를 한번에 사용하는 Unmasked 방식
- Encoder의 첫 번째 sub layer : Multi-Head Attention + Residual Block + Norm
- Encoder의 두 번째 sub layer : Feed Forward Network
- 512차원

3) Decoder
- 본 논문에서는 6 layer의 Decoder 사용
- 생성시에는 순차적으로 처리해야하므로 Masking 방식
- Decoder의 첫 번째 sub layer : Masked Multi-Head Attention + Residual Block + Norm
- Decoder의 두 번째 sub layer : Encoder-Decoder Self-Attention + Residual Block + Norm
- Decoder의 세 번째 sub layer : Feed Forward Network
- 512차원

Self Attention Layer의 역할?? : Token의 정보처리를 할 때, 함께 주어진 Input의 다른 token을 얼마나 중요하게 고려할 것인가
2-2. Input Embedding & Positional Encoding
2-2.1. Input Embedding
제일 처음 Encoder의 입력에 단어를 Embedding하여 사용
이후의 Encoder block에는 이전 Encoder의 output을 input으로 받음 (512차원)
2-2.2. Positional Encoding
Input이 한번에 들어오기 때문에 어떤 단어가 어디에 위치해있는지에 대한 정보를 손실
이러한 위치정보를 최대한 보존하기 위해 Positional Encoding vector 사용(512차원)
Input Embedding + Positional Encoding = Input(512차원)
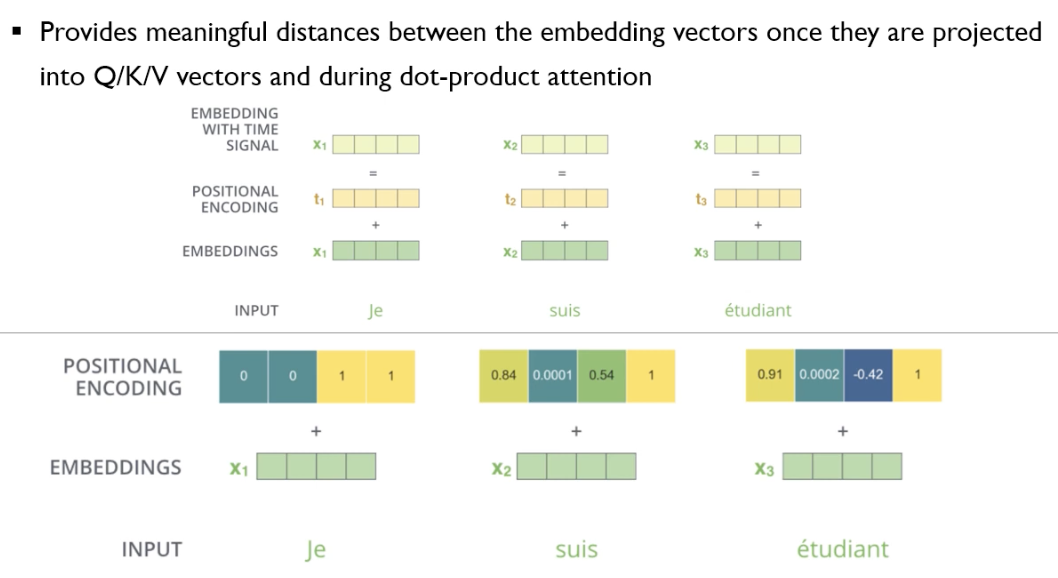
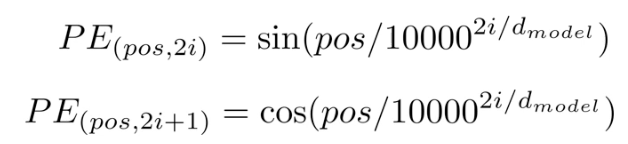
모든 Embedding된 Vector들이 같은 방향, 같은 크기로 변화해야함
멀리 있는 단어들은 positional encoding 사이의 거리도 멀어야함
2-3. Encoder - Multi-Head Attention
Input으로 사용된 단어들(Embedding & Positional Encoding)의 vector들이 Self Attention Layer을 거침
Multi-Head Attention Layer에서는 각 vector들 사이에 연관성(dependencies) 존재 (Feed Forward에는 X)

2-3.0. Self Attention이란??
Self Attention의 역할은??
문장 속의 한 단어와 연관이 있는 단어가 무엇인지 알기 위해서 사용


Self Attention을 위해 각 input vector에 대해 3종류의 vector 생성
- Query : 현재 참조하고 있는 단어
- Key : vector들에 대한 Label, 한 Query에 대해 key 값으로 다른 단어 참조
- Value : 실제 단어에 대한 값, score 값

Step1. Input Embedding에 따라서 Query, Key, Value vector 산출
WQ, WK, WV와 Input Embedding Vector를 연산하여 Query, Key, Value 계산 (1X4)*(4X3) = (1X3)
512차원의 vector에 대해서 Q,K,V vector는 64차원 -> 64 * 8 = 512 (Multi Head Attention)
WQ, WK, WV는 모델 학습을 통해 생성

Step2. Score 계산 (특정 벡터에 대해 다른 부분들에 얼마나 집중해야 하는가)
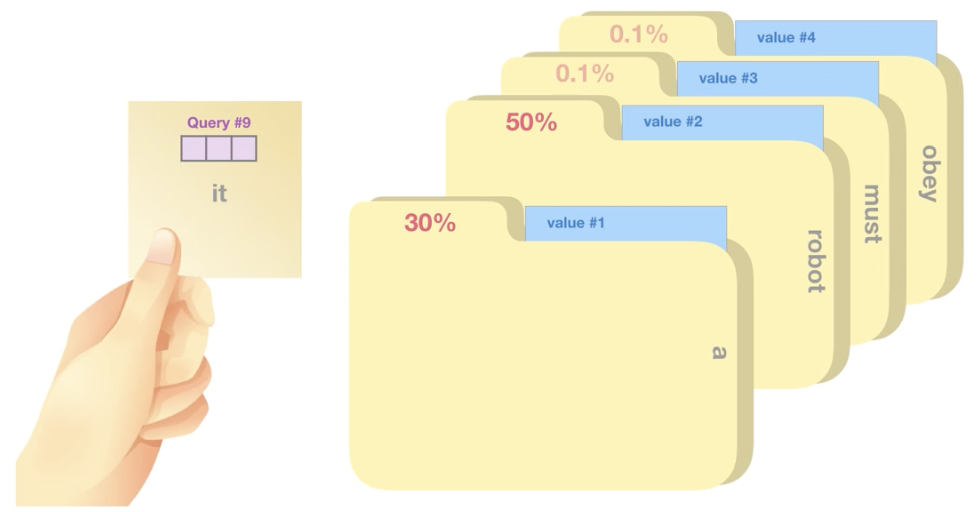
현재 참조하고 있는 <it>이라는 Query(3차원)과 가장 관련성이 높은 것은?? = 30%, 50%, 0.1%,,, 계산하기

Score : 현재 보고 있는 Input의 Query(q1)와 나머지 단어들에 대한 값인 Key(k) 곱 연산
score1_1 = q1*k1 = 112
score1_2 = q1*k2 = 96
,,,
Step3. Divide by 8
계산한 Score를 차원에 대한 root 값 (논문에서는 64차원이므로 8)로 나눔 -> Gradient 안정화 효과
차원(dk)가 커지면 Q*K 값이 너무 커질 수도 있기 때문에 이를 방지하고자 나눠줌
score1_1/8 = 14
score1_2/8 = 12
,,,
Step4. Softmax
0~1 사이의 확률값으로 변환 = 얼마나 중요한 역할을 하는가
softmax1_1 = 0.88
softmax1_2 = 0.12
,,,
Step5. Softmax score X Value vector
각 value vector과 Step4에서 구한 Softmax 값 곱연산
weighted_v1 = v1 * softmax1_1
weighted_v2= v2 * softmax1_2
Step6. Sum the weighted Value vector
z1 = weighted_v1 + weighted_v2 + ,,,,
<Matrix 연산 요약>


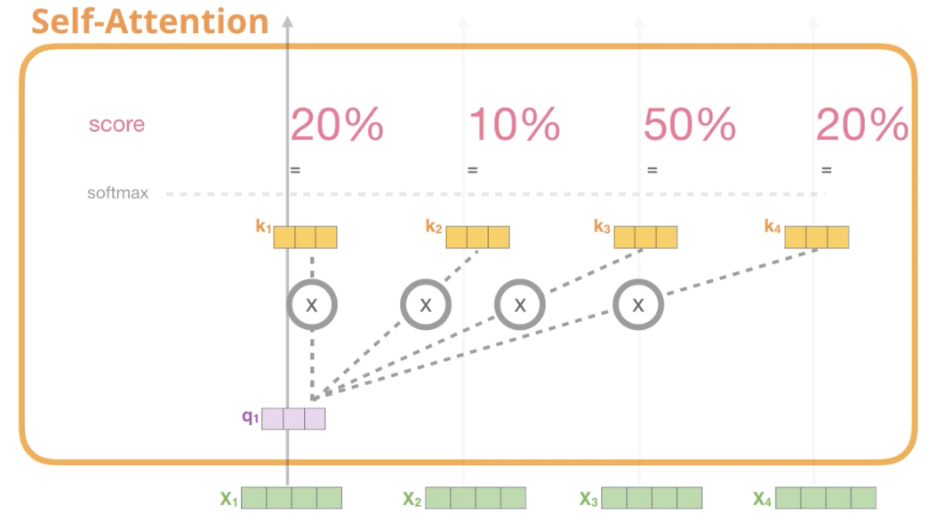
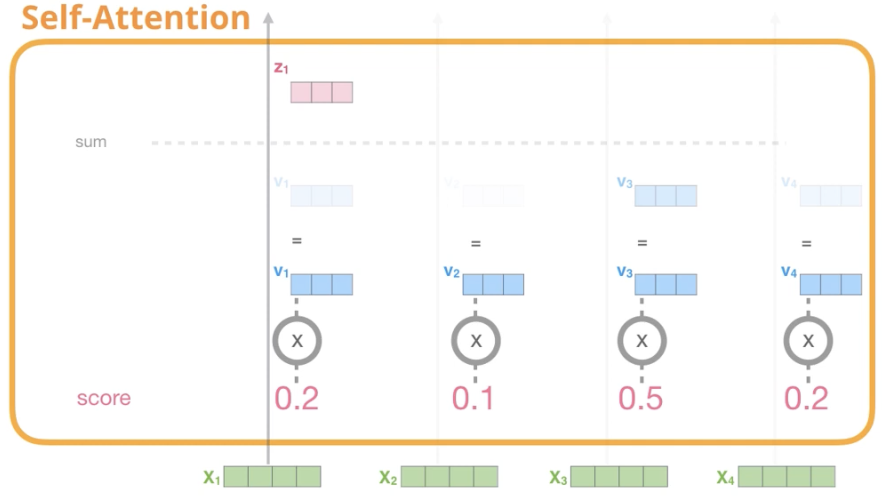
지금까지는 Single Attention에 대한 연산
Transformer의 Multi-Head Attention은 다른 방식으로 여러번 반복
2-3.1 Mulit-Head Attention
산출된 Attention의 값들을 Concat (Z0 ~ Z7) -> Z_concat
Z_concat의 column 개수와 동일한 row 개수를 가지며 기존의 input embedding과 같은 차원을 가지는 matrix W0
matrix W0를 통해서 vector size 조절
W0은 모델 학습을 통해 생성
Z_concat X W0 = Z (input embedding의 dimension과 동일한 크기)


Multi Head Attention의 전체 과정
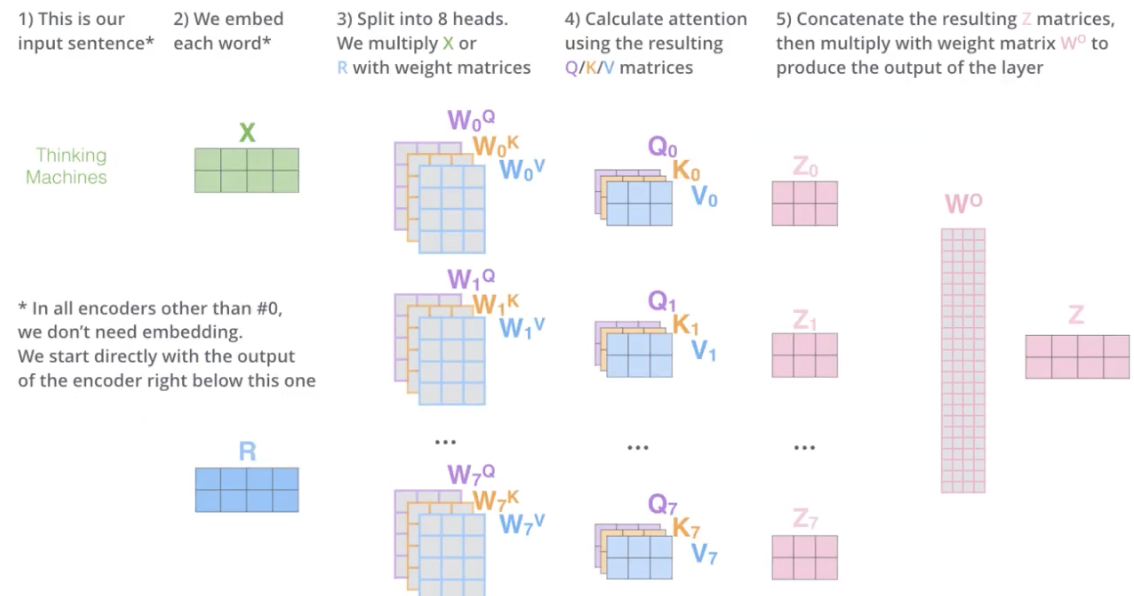
X는 최초 input, 제일 처음 Encoder에서 사용
R은 이전 Encoder의 Ouput
X와 R은 같은 크기
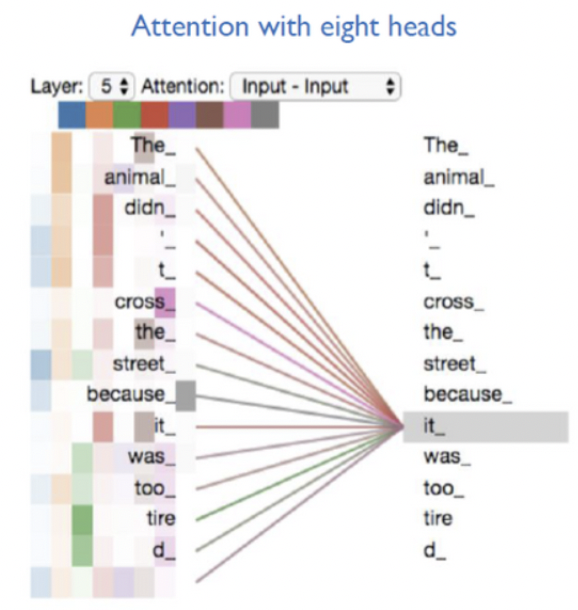
8개의 head를 사용한 Multi-Head Attention 결과, 각 head 마다 다른 방식으로 Attention을 주고 있음
2-4. Encoder - Residual Block & Norm
함수의 output + Input Vector(Positional Encoding 거친 후)
gradient를 구했을 때 너무 작아지지 않도록 유지 가능
Residual Block & Norm은 Encoder, Decoder의 모든 sublayer에서 사용
2-5. Encoder - Feed Forward Network
Feed Forward Network는 Fully Connected Network이고, 각 Z에 대해서 독립적으로 적용됨

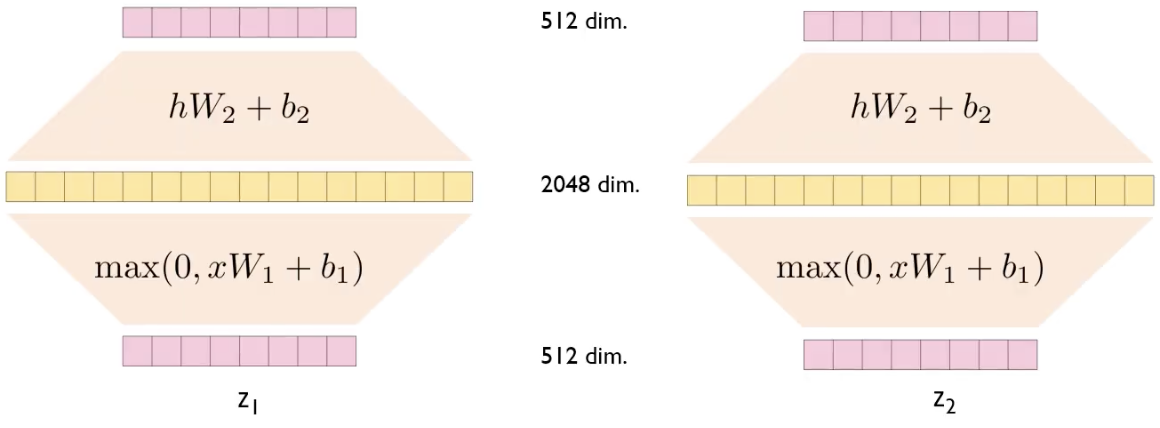
같은 Encoder Block 내에 있는 Feed Forwad Network는 같은 parameter를 공유(같은 구조)
-> 위의 그림에서 W1, b1, W2, b2는 동일한 값
max(0,xW1+b1) : kernel size=1, channel=2048인 convolution layer를 통과시키는 과정과 동일
hW2 + b2 : kernel size=1, channel=512인 convolution layer를 통과시키는 과정과 동일
즉, 과정은 독립적이지만 convolution 연산을 통해 빠르게 연산할 수 있음
2-6. Decoder - Masker Multi-Head Attention
Decoder의 Attention은 Masked
즉, 참조하는 단어의 앞에서 이미 존재하는 단어들에 대해서만 Attention Score 확인 가능(Sequential)

왼쪽 이미지는 Encoder에서의 Attention 과정
-> Thinking이라는 단어에 대해서 Score를 구할때, 뒤에 있는 Machines라는 단어를 참조 가능
우측 이미지는 Decoder에서의 Attention 과정
-> Thinking이라는 단어에 대해서 Score를 구할때, 뒤에 있는 Machines라는 단어를 참조 불가능
-> 뒤에 나오는 단어들에 대해서 Score를 "-inf"로 설정 (Masking)
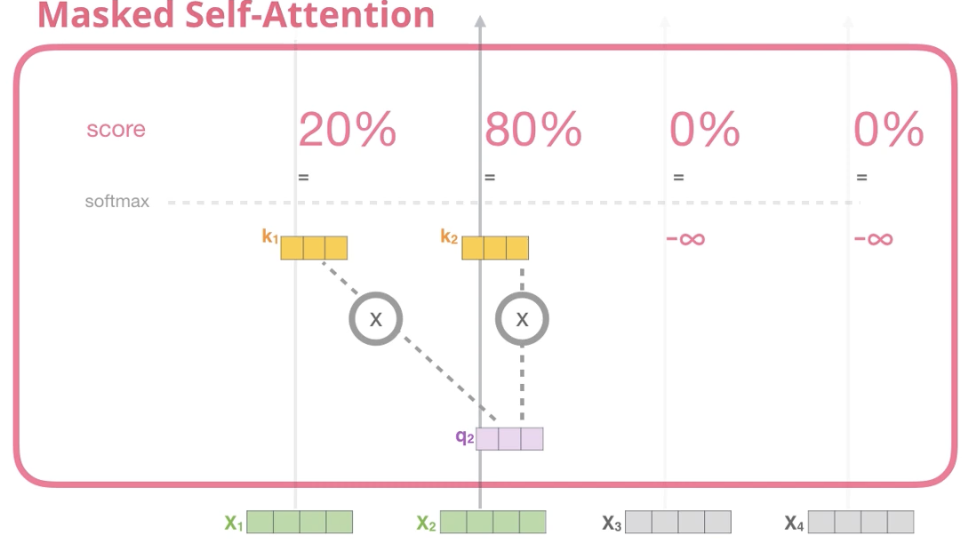
X2에 대해서 뒤에 나오는 X3, X4의 Score는 계산 X
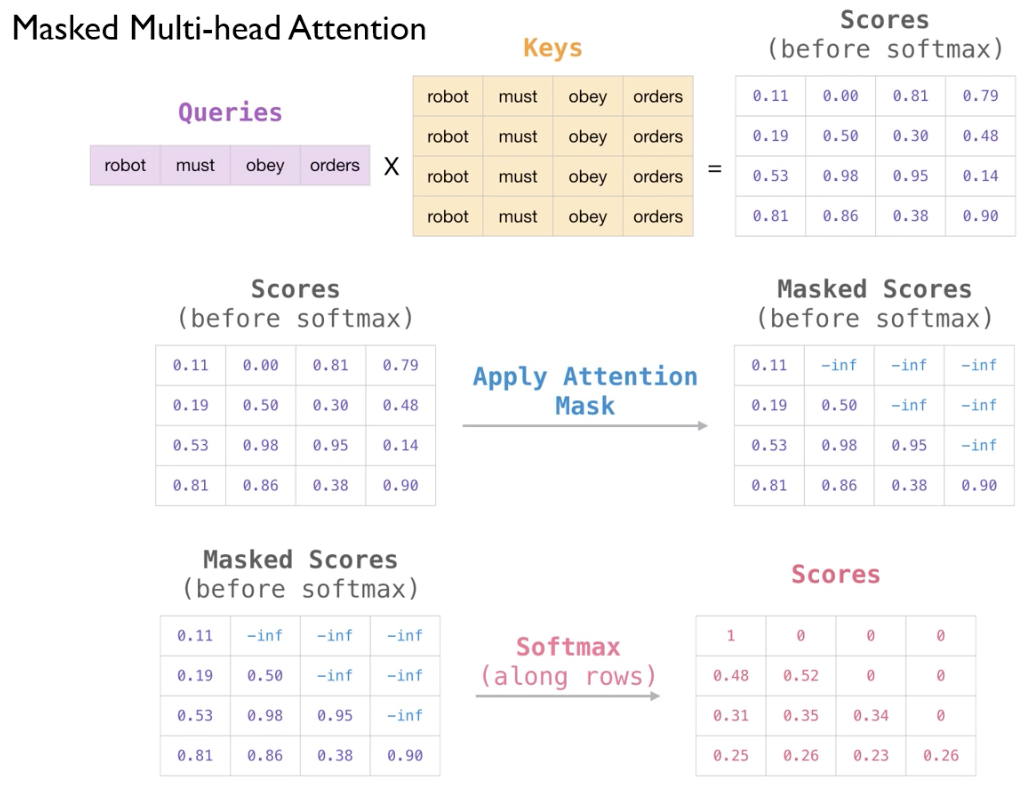
일단 Score를 모두 계산한 이후에, Masking 진행 (-inf) -> Softmax를 거치면 0이 됨
2-7. Decoder - Encoder-Decoder Multi-Head Attention
Encoder의 결과와 Decoder의 Multi-Head Attention 결과에 대해 Attention 진행
Decoder에서 나온 Query(참조하는 단어)에 대해서 Encoder에 있는 Key와 Value를 사용
Decoder의 출력 단어들이 Encoder의 입력 단어들 중에서 어떤 단어에 많은 가중치를 두는지 계산
<Residual & Norm, Feed Forward는 Encoder과 동일하므로 생략>
2-8. Decoder - Final Linear & Softmax Layer
Linear Layer(Fully Connected) + Softmax Layer를 거치면서 probability 계산 => 어떤 단어가 나와야하는지 예측
Reference
https://www.youtube.com/watch?v=AA621UofTUA&t=348s
https://www.youtube.com/watch?v=Yk1tV_cXMMU





댓글 영역