고정 헤더 영역
상세 컨텐츠
본문 제목
[CV 논문 리뷰 스터디 / 2주차 / 엄기영] Fully Convolutional Networks for Semantic Segmentation, 2016
본문
Fully Convolutional Networks for Semantic Segmentation
Paper:
Fully Convolutional Networks for Semantic Segmentation
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build
arxiv.org
Sementic Segmentation

Sementic Segmentation은 Image에 있는 픽셀을 해당되는 Class로 분류하는 것으로, 모든 픽셀에 대해 예측을 진행하므로 dense prediction으로도 불린다. 하지만 Instance Segmentation과는 다르게, 같은 Class 내의 다른 instance들은 구별하지 않는다.
Abstract
Convolutional network는 강력한 시각적 모델로서 feature의 계층 구조(image input에 가까울 수록 local한 영역을 fine하게 보고, output에 가까울 수록 coarse하고 semantic, global한 영역을 본다) 를 생성한다. 논문에서는 convolutional networks들 만으로 end-to-end, pixel-to-pixel 학습을 구현함으로서 당시 SOTA semantic segmentation의 성능을 뛰어 넘었다. 이 방식의 주된 아이디어는 "fully convolutional" 네트워크를 구축함으로서, 다양한 사이즈의 인풋으로부터 상응하는 output을 효과적으로 추론하고 학습하게 만드는 것이었다. 논문에서는 fully convolutional network의 공간적 정보를 정의하고 자세히 설명하며, spatially dense prediction task로의 적용에 대해 설명하고 이전 모델과의 연결을 이루어 냈다. 모델에서는 분류 네트워크인 Alexnet, VGG, GoogLeNet 등을 fully convolutional network로 재구축하고, fine-tuning을 이용해 분류 네트워크의 학습된 값들을 segmentation에 사용될 수 있게 전달했다. 그런 뒤 deep, coarse 레이어의 semantic 정보와 shallow, fine 레이어의 appearance 정보를 결합해 정확하고 세분화된 segmentation을 진행할 수 있는 새로운 아키텍쳐를 정의하였다. 이렇게 탄생한 fully convolutional network는 PASKAL VOC, NYUDv2, SIFT Flow 데이터에 대해 SOTA segmentation을 달성하였고 1/5초보다 적은 시간 만으로 하나의 이미지에 대한 추론을 진행할 수 있었다.
Introduction
Convolutional network는 인식 분야에서의 원동력이 되었다. Convnet은 전체 이미지 분류 뿐만 아니라, local한 테스크에 관해서도 구조화된 output과 함께 성과를 이뤄냈다. 이는 Bounding box object detection, part and key point prediction, local correspondence등의 향상을 포함한다.
Coarse-to-Fine inference에 대한 발전의 다음 단계는 모든 pixel에 대해 prediction을 진행하는 것이다. 기존의 Convnet에서 semantic segmentation 을 위해서 사용한 접근 방식에서는, 각 픽셀이 해당되는 object나 region에 대해 라벨링 되었는데, 이러한 방식에는 한계가 존재하였다.

논문에서는 추가적인 머신러닝 방법론 없이도, semantic segmentation을 위해 end-to-end, pixel-to-pixel 로 학습된 fully convolutional network(FCN)이 SOTA를 달성할 수 있음을 보여줬다. 논문 발표 당시 supervised pre-training을 이용한 pixel 단위 예측 및 FCN을 end-to-end로 학습하는 방식은 처음 시도된 것인데, 이는 이미 존재하는 network의 fully Convolutional 버전을 이용해 다양한 인풋으로부터 dense 아웃풋을 예측하였고, 학습과 추론은 전체 이미지에 대한 dense feedforward 연산과 backpropagation을 통해 한번에 수행되었다. 네트워크 안에 존재하는 upsampling 레이어를 이용해 pixel 단위 예측과 subsampling 학습을 가능하게 했다.
이러한 방식은 점근적, 그리고 절대적으로 효과적이며 다른 연구에서 처럼 복잡할 필요가 없다. 패치 단위 학습(이미지의 한 부분을 crop하여 patch화)이 일반적이나 이는 fully convolutional 학습의 효율성을 저해시켰다. 따라서 패치 단위 학습에서 일어나는 복잡한 전/후 처리(superpixel, proposals, post-hoc refinement by random fields or local classifiers)를 사용하지 않는 접근 방식이 사용되었다.
모델은 classification에서의 최근의 발전된 성능을 dense prediction에 이용하기 위해, 그들의 학습된 representations를 fine-tuning하는 방법으로 fully convolutional로 만들었고, 이에 대조적으로 이전의 연구들에서는 supervised pre-training을 거치지 않은 small convnet을 사용하였다.
Semantic segmentation은 의미(semantic)와 위치(location)의 두개의 내재적인 텐션이 작용한다고 생각할 수 있다. 전역 정보는 "무엇인지" 를 알아내는 반면, 지역 정보는 "어디인지"를 알아낸다. 깊은 피쳐 계층구조는 location 그리고 의미 정보를 동시에 local-to-global pyramid로 인코딩한다. 모델에서는 "skip"이라는 구조를 통해 깊고 coarse, semantic한 정보와, shallow, fine 한 appearance 정보를 결합하였다.
Fully Convolutional Networks
convnet의 각 레이어의 output은 h x w x d의 사이즈를 갖는 3차원 array이다. h, w는 공간 차원을, d는 피쳐 혹은 채널 차원을 의미한다. 첫 번째 레이어는 이미지로, pixel size h x w 그리고 d 채널을 갖는다. 아래 그림과 같이, upper 레이어의 위치에서 path-connected 된 이미지의 위치를 "receptive field"라고 한다.
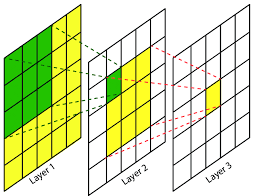
Convnets은 기본 구성요소(Convolution, pooling, activation functions)는 Local input 영역에서 작동하고, 해당되는 공간 좌표에만 영향을 받기 때문에 내재적으로 translation invariant 하다(이미지의 spatial 한 변화에 민감하지 않음).
Xij를 특정 레이어의 (i, j)번째 데이터 벡터라고 하고, yij를 다음 레이어라고 했을 때 아래 함수를 살펴보자.

여기서 k는 커널의 크기, s는 stride 혹은 subsampling, fks는 layer의 타입을 결정한다.(convolution 혹은 pooling연산을 위한 행렬 곱이나 max pooling의 max function, 활성화 함수를 위한 elementwise 비선형 연산 등) 예를 들면 s = 1, k = 3이라고 할 때, 집합 내의 x들은 xi,j, xi+1,j+1, xi+2,j+2, xi+3,j+3과 같은 이전 레이어 노드들의 집합이 되고, f를 convolution이라고 할 때, 합성곱연산 연산을 거쳐 다음 단계의 노드 yij가 되는것이다. (즉 복잡해 보이지만, CNN에서 fc layer이전의 convnet연산을 풀어낸 일반적 함수식이다.)
이러한 함수 f와 g의 composition은 커널 사이즈와 stride가 아래와 같은 transformation rule을 따르면서 계산된다.

일반 deep net은 일반 비선형 함수를 계산하지만, 위 식과 같은 형태의 net은 비선형 필터 연산만을 진행하며, 이를 deep filter 혹은 fully convolutional network(FCN)라고 부른다. FCN은 다양한 사이즈의 input에도 작동하며(Fully connected layer에 들어가는 input size가 고정되므로 이미지 input 크기가 제한되는 반면 FCN은 FC Layer가 없어 제약이 없다.), 상응하는 spatial 차원을 가지는 output을 낸다.
FCN으로 구성된 실수 loss function은 문제를 정의한다. 만약 loss function이 마지막 레이어의 spatial dimension의 합이면,

loss function의 파라미터 gradient는 그들의 spatial components 각각의 파라미터의 gradients를 summation하는 것이 된다. (위 수식 참조)
따라서 전체 이미지에서 구해진 l 에 대한 Stochastic gradient descent는 마지막 레이어의 receptive fields를 minibatch 형태로 받은 l'에 대한 SGD와 같게 된다.
이러한 receptive fields가 많이 overlap 되면, 패치 단위 계산보다 전체 이미지를 layer 단위로 계산을 진행했을 때, feedforward 연산과 back-propagation이 매우 효율적이게 된다.
Dense prediction을 위해 Classifier를 적용하다.

인식모델인 LeNet, AlexNet, 그리고 더 깊은 여러 모델들은 고정된 크기의 인풋을 받아 공간적 정보가 없는 output을 낸다. fully connected layers(FC layers)는 고정된 차원(eg. vgg-16의 경우 4096을 무조건 input으로 받는다.)을 가지고 공간 좌표 정보들을 잃어버린다. 하지만 FC layer도 전체 인풋 범위(H x W)를 포괄하는 커널을 이용한 convolution이라고 볼 수 있다. (예를들면 VGG-16의 경우 FClayer에 들어가는 부분 대신 7x7x4096으로 합성곱 연산을 진행하면 1x1x4096의 결과를 얻을 수 있음)

이런 방식으로 FC 레이어들을 교체하면, 네트워크들을 모든 사이즈의 input을 받을 수 있고(FC layer의 인풋 크기 제한이 사라짐), 공간적 output map을 만들어 내는 fully convolutional network로 바꿀 수 있다.
더 나아가 결과로 나오는 map은 particular patch를 사용한 original net의 계산결과와 같아지고, 연산량은 이 패치들의 영역에 overlap되면서 매우 줄어든다. 예를들면, AlexNet이 227 x 227 사이즈 이미지의 classification score를 forward(=inference) 하는데 1.2ms가 걸리는 반면, fully convolutional net은 500 x 500 이미지에 대해 10 x 10 그리드의 결과값을 22ms만에 얻어낼 수 있다. 이는 원래 방식에 비해 5배나 빠르다.
이러한 convolutional 모델을 통해 나오는 spatial output maps는 semantic segmentation과 같은 dense problems에 사용하기 용이했다. 모든 ouput cell에 대한 ground truth가 사용이 가능하다면, forward , backward passes가 간단해지고 둘 모두가 추론 연산에서의 효율성을 가진다.
이에 상응하는 AlexNet의 backward(=learning) 시간을 살펴보면, 한 이미지 당 2.4ms, 그리고 fully convolutional 10 x 10 output map에 대해서 37ms 의 시간만이 소요된다. 이는 forward pass 의 시간과 비슷하다. forward, backward 과정은 아래 그림에서 확인할 수 있다.
이러한 classification net의 fully convolutional한 재해석은 모든 size의 인풋에 대해 output maps를 생성할 수 있고, output dimension은 subsampling을 통해 축소된다. classification net은, subsampling을 통해 필터 사이즈를 작게 유지하고, 연산량을 합리적으로 조정한다. 이런 방식은 net의 fully convolution 버전에서 output을 보다 거칠게(coarse) 만들고, output unit에 해당하는 receptive field의 pixel stride 만큼 입력크기에서 감소시킨다.
이렇게 pretrained된 classification net을 변형해 fully convolutional version으로 만드는 것으로 위치정보 유지, 계산량 감소, output map 얻음 등 여러 이점을 얻을 수 있었다. 하지만 semantic segmentation을 진행하려면 pixel 단위로 연산 및 분류를 수행해야하는데, 이렇게 축약된(coarse)한 feature map은 해상도가 너무 작다. 따라서 원본 이미지 크기에 비슷하게 만들기 위해서는 해상도를 높여주는 Upsampling 기법이 적용될 필요가 있다.
Shift-and-stitch(Upsampling 기법-모델에 사용되지 않음)
Dense prediction(픽셀단위 예측)은 input 의 shifted version으로 부터 나온 여러 coarse output을 붙임으로서 얻어질 수 있다(shift-and-stitch). 아래 그림은 shift-and-stitch 과정의 예시인데, input (1~25의 5x5 grid)가 2x2 max-pooling이라는 downsampling 을 거쳐 빨간색 3x3 grid와 같은 coarse output을 얻는다고 가정하자. 그럼 이 input을 x, y 축상으로 이동(shift)하고, 다시 downsampling(정보축약-합성곱연산)을 거쳐 그림 오른쪽 상단의 노랑, 초록, 파랑 등을 얻어낸다. 이렇게 얻어낸 feature들을 붙이는(stitch) 방법 을 통해 input 이미지 해상도와 동일한 오른쪽 하단의 output을 만들어낸다.

조금 더 일반적인 form으로 설명하면, output이 f 만큼 downsampling 되었다고 하자. 먼저 input을 모든 아래 조건을 만족시키는 모든 (x, y)에 대해서 x픽셀만큼 우측으로, y 픽셀만큼 아래로 이동시킨다.

이러한 f^2 (x와 y 각각 f만큼이므로)의 inputs을 processing(연산을 진행) 한 뒤, 그리고 outputs을 interlacing(잘 섞어 붙임)을 해, 각픽셀에 해당하는 prediction이 그들의 receptive fields의 정중앙에 위치하도록 만든다. 이러한 변형은 cost를 f^2만큼 증가시키나, identical 한 result를 효과적으로 만드는 유명한 트릭이다. (다른 여러 모델에서도 이런 기법으로 upsampling을 진행했다.)
input stride = s인 layer(conv or pooling)와, 필터의 가중치를 fi,j로 갖는 다음 단계 레이어를 생각해보자. 이전 단계의 레이어의 input stride를 1로 설정하면, 그것의 output을 s만큼 upsampling할 수 있다. 하지만, 원래 필터를 upsample된 output에 사용해 합성곱 연산을 진행하는 것은 shift-and-stitch와 같은 결과를 얻지 못하는데, 왜냐하면 오리지널 필터는 input의 축소된 부분만 보기 때문이다. 따라서 같은 결과를 얻기 위해서는 filter를 아래와 같은 방식으로 '확장'해줘야 한다.

즉 s가 i,j 의 공약수가 되면 filter의 가중치를 살리고, 그렇지 않은 경우에는 0으로 만든다. 모든 i, j에 대해서 실행하게 되면, i,j 가 모두 s로 나눠지는 경우는 원래 fi,j의 값을 갖게 되고, 그렇지 않은 경우는 0이되며 필터의 크기가 굉장히 커지게 된다.
shift-and-stitch의 full net output을 재생산하려면 이러한 필터 확장을 모든 subsampling이 제거될 때 까지 반복해야 한다.
단순히 net에서 subsampling을 줄이는 것은 trade-off가 존재하는데, filter들은 finer한 정보를 보는 반면, 더 작은 receptive field를 갖게 되고, 계산하는 시간 또한 오래걸린다. 이러한 팽창 방식은 다른 종류의 trade-off인데, output이 필터의 receptive field사이즈를 줄이지 않고 dense해 지지만, filter들은 원래 디자인에 비해서 finer 한 scale의 정보에 접근할 수 없게 된다.
비록 이렇게 dilation에 대한 실험을 진행해 보았으나(논문에서) 모델에서는 사용하지 않았다. 다음 섹션에서 소개할 upsampling을 이용한 학습이 skip layer와 함께 사용된다면 효과적이고 효율적임을 알게 되었다.
Upsampling is (fractionally strided) convolution
coarse한 output을 dense pixel로 연결하는 다른 방법은 바로 interpolation(보간법)이다. 예를 들면, bilinear interpolation은 각각의 output인 yij를 계산하기 위해, input과 output cell의 상대적인 위치에 의존하는 linear map에서의 4개의 input을 사용한다.

f는 upsampling factor, {}는 fractional part({x} = x - |x|)
어떤 의미에서 f factor를 이용한 upsampling은 1/f의 input stride 를 갖는 convolution 연산이라고 할 수 있다. 조금 더 자세하게 알아보기 위해 그림을 확인해보자. 아래 그림은 일반적인 convolution 연산과정을 나타낸 것이다. filter와 input간의 dot product로 연산을 수행하는 방법으로 stride 수에 따라 output의 크기를 다르게 만들 수 있다.

이 과정을 반대로 생각해 보면 아래 그림과 같다. 논문에서는 이를 Deconvolution이라고 정의하는데, 현재는 transpose convolution이라고 불리는 과정으로, 2x2의 인풋이 주어지면, 인풋의 한 node를 이용해 3x3 filter(필터 내 가중치는 학습되는 파라미터)에 weight를 시켜준다. 예를 들면 input 2x2의 왼쪽 위의 빨간 부분이 2이고 3x3 에 모두 weight가 2로 되어있는 필터를 적용하면, output은 3x3의 4들로 구성되게 된다. 이러한 결과를 padding 된 output map에, stride만큼 이동하면서 삽입하고, 겹치는 부분의 경우 두 결과값을 더하는 방식으로 transpose convolution을 진행한다. 이름에 transpose convolution이라는 명칭이 붙는 이유는 아이디어 구현 과정에서 행렬의 Transpose를 사용하기 때문이다.

자세한 내용은 아래 블로그에서 확인할 수 있다.
여러가지 Upsampling 방식들
dacon.io
이러한 upsampling 기법은 네트워크 상에서 픽셀단위 loss값으로 back-propagation을 통해 end-to-end 학습으로 진행된다. 또한 위에서 설명했듯이, filter에 해당하는 weight 파라미터들이 학습이 가능하므로, deconvolution layer들과 activation function을 쌓으면 nonlinear upsampling에 대해도 학습이 가능하다.
논문에서는 이러한 upsampling기법이 dense prediction에 대해 빠르고 효과적이었다고 한다.
Patchwise training is loss sampling (모델에 사용되지 않음)
Patchwise training(패치단위 학습)이란, 이미지에서 object 위치를 crop 하고(patch화) 이를 모델의 학습에 사용하는 방식이다.
Stochastic optimization에서, gradient 연산은 training distribution에 의해 구동된다. 계산의 효율성은 패치화 과정의 overlap이나 미니 배치 크기에 따라 상대적으로 달라지지만, 패치단위 학습과 fully convolution 학습 모두 input의 분포를 만들어 낼 수 있다.
전체 이미지에 대한 fully convolutional 학습은 패치단위 학습에서 모든 batch가 이미지에 대한 output 유닛의 receptive fields를 포함하고 있다면 동일하다고 볼 수 있다. (즉 패치를 만들 때, 이미지를 중복되지 않고, 모두 포함하게 자르면)
fully convolution 방법이 가능한 batches 사이즈를 감소시키기 때문에 패치 단위에 비해 효과적이라고 할 수 있다. 하지만, 이미지로부터 패치를 random sampling한 경우, 쉽게 복원이 가능하다. Loss를 공간적으로 subsampling 된 부분군에 한정시키면 gradient로 부터 patch를 제외할 수 있다.
유지된 patch에서 여전히 중복이 발생하더라도, fully convolutional 연산은 학습을 계속 진행해 낼 수 있다. 만약 gradient가 여러 backward passes에서 축적된다면, batch들은 여러 이미지로부터의 patch를 포함할 수 있다. 만약 input이 output stride 값만큼 shifted 되면, 모든 가능한 patches들의 랜덤 선택은 output 유닛이 고정된 grid 상에 존재하더라도 가능하다.
패치단위 샘플링 학습은 class imbalance를 해결할 수 있고, dense patches들에 대한 spatial 상관관계를 완화시킬 수 있다. fully convolutional 학습에서는 class balance의 경우 loss 에 weight를 주는 방법으로, 공간적 상관관계는 loss sampling 을 통해 해결될 수 있다.
논문에서는 이러한 sampling 기법을 활용한 학습에서 dense prediction에 이점을 찾을 수 없었다고 한다. Whole image 학습 방식이 훨씬 효과적이고 효율적이었다고 한다.
Segmentation Architecture
ILSVRC (ImageNet Large Scale Visual Recognition Challenge)의 classifier를 FCN에 적용하고, pixel 단위 loss와 in-network upsampling을 활용한 dense prediction을 진행했다. segmentation은 fine-tuning으로 학습하였다. 다음으로 layer 사이의 "Skip" 구조를 추가하는 방법으로, coarse semantic 정보와 local appearance 정보를 융합하였다. 이러한 "Skip Architecture"는 end-to-end로 학습되어 output의 semantic, spatial 정확도를 개선 할 수 있게 한다.
이러한 방법이 효과적인지 확인하기 위해, 논문에서는 PASCAL VOC 2011 데이터로 학습과 validation을 진행했다. 픽셀단위 softmax loss값으로 학습하고, mean IoU를 이용해 validation을 진행했다. 평균은 background class를 포함한 모든 class에 대해 계산되었다. 학습과정에서 ground-truth에서 햇갈리거나 어려운 픽셀들은 무시되었다.
From classifier to dense FCN
이전 내용에서 언급한 유명한 classification architecture를 convolutionalizing하면서 시작했다. 먼저 ILSVRC12에서 우승을 거둔 AlexNet 구조나, ILSVRT14에서 우수했던, VGG, GoogLeNet 등을 고려하였고, VGGnet의 경우 이 테스크에 대해서는 VGG-16이나 19나 비슷했으므로 VGG-16을 선택했다.
GoogleNet에서는 마지막 loss layer만 사용하였고, 마지막 Average pooling layer를 제외함으로서 퍼포먼스를 향상시켰다. 나머지의 경우 각 넷의 마지막 분류 레이어를 버리고, FC 레이어를 convolution으로 변환하였다.
이 과정에서 최종 layer로 1x1 convolution (channel = 21)을 사용해 각 PASCAL classes를 분류하는데 사용했고, 각 coarse output 위치에서 deconvolution layer를 이어붙여, upsampling을 통해 pixel단위 output을 만들었다.
아래 테이블은 각 net의 특징들과 함께, validation 결과를 보여준다. (validation결과는 fixed learning late에서 converge된 각각의 최고 result를 사용하였다.)

이러한 학습에 대한 비교는 classification networks에 사용되는 관행을 따라 SGD, momentum을 이용해 훈련하였다.
line search를 이용해 FCN-(AlexNet, VGG16, GoogLeNet)에 대해 learning rate를 선정하였다.
momentum = 0.9로, weight decay를 각각 지정하고, biases에 대한 learning rate는 두배로 설정하였다.
class score를 계산하는 layer에 0 initializing을 진행하였고, 이런 방식이 무작위 초기화등의 다른 방식보다 빠르고 효율적이었다. 원래의 classifier 에서 사용된 dropout은 그대로 포함시켰지만 유무가 큰 차이는 존재하지 않았다.
classification 에서 segmentation으로의 fine-tuning은 각 net에 대해 괜찮은 예측값을 내게 하였다. 가장 성능이 안좋은 모델의 경우에도 best performance의 75%가량을 달성하였다. FCN-VGG16이 56.0 mean IU로 가장 좋은 성과를 냈고, 이러한 FCN-VGG16을 베이스 네트워크로 사용하였다.
Image-to-Image learning
이미지-이미지 학습은 input에 잘 맞는 효과적인 batch size 세팅이 필요하다. 즉, FCN을 적절하게 tuning하는데 신경을 쏟아야 한다.
Loss : loss 에 대한 정규화를 진행하지 않았기 때문에 모든 pixel은 batch나 image의 차원과 상관 없이, 같은 weight를 가지게 되었고, 모든 pixel에 대해 loss가 summed 되어야 하기 때문에 작은 학습률을 사용하였다.
Batch size : 두 가지 방식 중 하나는, gradient가 20개의 이미지에 누적되는 방식(Accumulation)이다. 이런 방식은 필요한 memory 량을 감소시키고, network를 reshaping하는 방식으로 다른 차원의 input을 바라볼 수 있게 한다. 이런 방식으로 배치 크기를 설정(20)하면 합리적인 convergence를 이뤄낼 수 있다. 이런 방식의 학습은 일반적인 분류 학습과 유사한데, 각 미니배치가 여러 개의 이미지를 포함하게 되고, class labels들에 대한 다양한 분포를 가지게 된다. Net을 비교한 위 표에서는 이러한 방식으로 최적화가 진행되었다.
두 번째 방법으로, online learning(연속적으로 데이터를 받고 한번 학습에 사용된 데이터는 버리는 학습법)을 위해 batch size를 1로 사용한다. 적절한 튜닝을 거치면 online learning이 더 빠른 수렴과, 높은 정확도를 얻어낼 수 있다.
추가적으로 더 높은 모멘텀인 0.99를 사용했는데, 이는 최근의 gradient에 더 가중치를 두는 방식으로 batching의 방식과 유사하다. 아래 테이블을 보면 accumulation, online, hight momentum 방식의 비교를 확인할 수 있다.

Combining what and where
논문에서는 새로운 fully convolutional net for segmentation이라는 것을 정의하여, feature의 위계에 따른 레이어를 통합하고, output의 공간적 정확도를 개선하였다. 아래 그림을 살펴보자.

Fully convolution화된 classifier가 semantic segmentation(인식 및 지역화)을 위해 fine-tuned 되면서, 이러한 네트워크들은 더 shallow하고 local한 feature들에도 바로 사용이 가능하게 개선되었다. 비록 이러한 base network들이 standard metrics(IoU등의 평가지표)에 대해 높은 성과를 보이지만, output의 경우 매우 거칠다(coarse). network prediction에서 stride를 사용하는 것이 upsampled된 output에 제약을 가하는 것이다. 아래 그림을 보면 upsampling 과정에서 stride 크기를 32로 설정한 일반 FCN-32s(FCN-VGG16)의 경우 segmentation 단위가 둥글고 크다(coarse하다)는걸 확인할 수 있다.

이런 문제를 해결하기 위해, layer의 output에 더 finer 한 stride를 예측에 사용한 shallow 레이어의 정보를 융합하기 위해 'skip'이라는 구조를 추가하였다. 이런 방식은 shallow layer에서의 정보를 skip해 보내는 방식으로 deeper한 레이어에 전달한다. local 한 prediction에는 shallow 레이어의 정보를 사용하는 것이 유용한데, 왜냐하면 더 적은 receptive field, 더 적은 pixel을 내포하고 있기 때문이다. 이러한 skip구조를 이용해 augmented되면, 네트워크는 여러 stream(high~low layer)에서부터의 prediction을 융합하며, 이러한 학습은 동시에, 그리고 end-to-end방식으로 이루어진다.
fine layer와 coarse layer를 결합하는 것은 layer가 local prediction을 만들 때, global structure을 동시에 고려하게 만든다. 이렇게 layer 와 resolution을 교차하는 것은. Laplacian pyramid의 다양한 scale 결과물에 대응된다. 이러한 feature 위계구조를 deep jet이라고 한다.

레이어의 융합은 element 단위 연산으로 이루어진다. Layer들을 통해서 이러한 요소별 연산을 진행하는 것은 resampling과 padding에 의해 굉장히 복잡해지기 때문에, 따라서 일반적으로 scaling 과 cropping을 이용해 공간적 정보를 먼저 일치 시키고 layer들이 합쳐져야한다.
여기서는 두 개의 layer를 가져와 lower-resolution 레이어를 upsampling하는 방식으로 scale을 맞추었다. Cropping을 통해 padding으로 인해 다른 레이어를 지나고 확장되는 업셈플링 된 레이어의 모든 부분을 제거하여 동일한 치수의 레이어가 정렬된다. 잘린 영역의 offset들은 모든 중간 레이어의 resampling과 패딩 파라미터에 의해 달라지고, 정확히 일치시키는 crop을 결정하는 것은 복잡할 수 있으나, 자동적으로 network의 정의에서 결정된다.(Caffe에 code를 넣었다고 한다.)
레이어를 정렬한 뒤에는 어떻게 fusion을 할지를 선택해야한다. 논문에서는 feature들을 concatenate하는 방식을 사용했고, 바로 1x1 convolution으로 구성된 "score layer"를 사용해 즉시 분류를 진행한다.
concatenate된 feature들을 메모리에 저장하는 대신에, 바로 이를 이어지는 classification에 연결하는 것인데. 따라서 skip은 먼저 각 레이어에 대해 1x1 convolution으로 score를 얻어내고, 필요한 interpolation이나 정렬을 진행한 뒤, score을 합산하는 방식으로 이용한다. 또한 max fusion(최댓값으로 융합하는 방식)을 고려하였으나, gradient switching에 의해 학습이 어려워 진다는 것을 발견했다. score layer의 파라미터들은 0으로 초기화 되었고, skip 구조를 사용했기 때문에 다른 stream에서의 존재하는 예측값들을 방해하지 않았다. 한번 모든 레이어가 fused 되면 마지막 예측은 다시 image resolution으로 upsampled 된다.
Skip Architectures for Segmentation
이 그림에서 보이듯이 skip architecture를 이용해, FCN-VGG16을 8 pixel stride의 3개의 흐름을 가지는 net으로 확장시켰다. pool4에서의 skip 구조 추가는 16 stride 레이어에서 scoring을 진행해 stride를 절반으로 줄일 수 있다. skip 에서의 2x의 interpolation layer는 bilinear interpolation으로 초기화 되지만, 위에서 설명했듯 고정되는 것이아니라 이는 학습이 가능하다. 이를 FCN-16s의 two stream net이라고 부르며, 마찬가지로 stride = 8의 prediction을 만들기 위해 pool3에서 skip을 추가하여 FCN-8을 정의한다.
논문에서는 단계별 학습과 한번에 진행하는 학습을 모두 실험해 보았는데, 단계별 학습에서는 FCN-32를 학습한 뒤, two stream FCN-16으로 업그레이드하여 계속 학습, 마지막으로 3 stream FCN-8로 업그레이드한 뒤 학습을 마친다. 각 단계에서 네트워크는 end-to-end로 학습이 되며, 이전 네트워크의 파라미터로 초기화된다. 하지만 learning rate가 FCN-32 에서 FCN-16으로 100배 떨어지고, 다시 FCN-8에서 100배 더 떨어져 지속적 개선이 필요해 보였다.
한꺼번에 학습하는 방법은 거의 동일한 결과를 얻을 수 있고, 학습이 더 빠르다. 하지만 서로 다른 피쳐의 크기는 학습이 divergence하기 쉽게 만든다. 이를 해결하기 위해 fixed된 상수를 이용해 각 stream의 크기를 조정한다. 이러한 상수는 stream 전체의 average feature norms를 균등화 하기위해 선택된다.(다른 정규화 방법 또한 비슷한 효과를 내야 한다.)
FCN-16의 validation score이 mean IU 65.0으로 향상되고 FCN-8s는 아주 작은 65.5의 향상을 이루어냈다. 따라서 효과의 감소시점을 만났기 때문에 추가적인 shallower layer에대한 fusing은 진행하지 않았다.
이러한 skipping의 기여도를 확인하기 위해 중간레이어를 따로 따로 scoring하여 비교하였다. skip을 추가하지 않았을 때 낮은 퍼포먼스나, 학습률을 떨어뜨리는 결과를 낳았으며, output에 대한 refine을 진행하지 않으면 별로 향상되지 않았다. 모든 skip에 대한 비교는 아래 테이블을 참조하자.

Experimental framework
Fine-tuning : 모든 레이어에 대해 backpropagation을 진행하면서 fine-tuning을 진행했다. output classifer 하나만을 fine-tuning하는 것은 full 로 진행하는 것 대비, 약 73%의 퍼포먼스만을 보였다. stage들에 대한 fine-tuning은 하나의 GPU에 대해서 36시간만이 소요되었다. FCN-8s를 한번에 학습하는 것은 비슷한 accuracy를 내기 위해 반정도의 시간이 소요되었다. scratch로부터의 training은 훨씬 적은 accuracy를 보였다.
More training data: 파스칼voc 2011은 1,112개의 이미지에 대한 라벨을 설정한다. Hariharan 외 다수는 PASCAL training 이미지에 대한 더 많은 8,498개의 이미지 셋을 collect했고, 이를 이용한 학습은 FCN-32s의 validation score를 57.7 에서 63.6으로 상승시켰고, FCN-AlexNet을 39.8 에서 48.0 mean IU로 향상시켰다.
Loss: 픽셀단위 normalizing을 진행하지 않은 softmax loss는 서로 다른 class에 대한 다양한 사이즈의 이미지를 segmenting하는데에 자연스러운 선택이 되었고, 따라서 이를 이용해 net을 train시켰다. Softmax 는 class간의 비교를 통해 가장 그럴듯한 예측을 얻어내지만 이것이 꼭 필요하거나 도움이 되는지는 명확하지 않다. 이에 대한 비교를 위해 sigmoid corss entropy loss로 학습하고 class 예측을 독립적으로 정규화하였음에도 유사한 결과가 나오는 것을 확인할 수 있었다.
Patch sampling: 전체 이미지에대한 학습은 각 이미지를 같은 크기의, 겹치는 patch들로 batch화 시킨다. 하지만 최근의 연구에서는 모든 데이터에 대한 random patch sampling을 진행하여, 더 높은 분산의 batch들을 이용해 수렴을 가속화한다. 논문에서는 각각의 마지막 레이어의 cell을 1-p의 확률로 무시하는 선택을 하게 만드는 방법으로 loss 를 spatially sampling하는 방법을 통해 이러한 trade-off가 존재하는지 확인해 보았다.
effective batch size를 바꾸는 것을 피하기 위해, 배치당 이미지의 개수를 1/p만큼 동시에 늘려준다. convolution의 효율성으로 인해 이러한 형태의 sampling은 p를 충분히 크게 잡는다면(최고 p>0.2) patchwise 학습에 비해 아직도 빠르다.
아래 그림은 이러한 형태의 sampling이 convergence와 어떤 관계가 있는지를 보여준다.

이러한 실험을 통해 sampling이 convergence rate에 큰 차이를 가지지는 않는다는 것을 알 수 있었으나, 배치당 더 많은 개수의 이미지를 담당하게 되기 때문에, 시간이 훨씬 많이 걸린다. 따라서 unsampled, whole image training을 사용한다.
Class balancing: Fully convolutional 학습은 loss를 sampling하거나 weighting을 주는 방법으로 class간 balance를 맞춰 줄 수 있다. 비록 사용된 라벨이 unbalanced였음에도(3/4는 background class였음), class balancing이 불필요함을 확인했다.
Dense Prediction : score는 deconvolution 과정을 통해 입력차원으로 upsampling된다. 마지막 레이어의 deconvolution 가중치는 bilinear interpolation으로 고정되고, 중간 upsampling 레이어는 bilinear interpolation으로 초기화된 후 학습된다. 이런 간단한 end-to-end 방법은 정확하고 빠르다.
Augmentation: 각 방향에서 최대 32pixel(예측의 가장 coarse한 스케일)로 이미지를 변환해, 무작위로 mirroring하고, jittering하여 훈련데이터를 보강하려고 시도하였으나 눈에 띄는 개선을 가져오지 못했다.
Implementation: Nvidia Titan X를 사용해 Caffe에서 학습되고 테스트되었다.
Result






Reference:
[CNN] VGG16
소개 VGG16은 16개 층으로 이루어진 VGGNet을 의미합니다. VGGNet(VGG19)는 2014년도 ILSVRC(ImageNet Large Sclae Visual Recognition Challenge)에서 준우승한 CNN 네크워크입니다. VGGNet(VGG19)는 사용..
hnsuk.tistory.com
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=samsjang&logNo=220508552078
[16편] 이미지 피라미드
이미지 프로세싱 & 컴퓨터 비전 OpenCV-Python 강좌 16편 : 이미지 피라미드를 활용한 이미지 프로...
blog.naver.com
https://paperswithcode.com/method/laplacian-pyramid
Papers with Code - Laplacian Pyramid Explained
A Laplacian Pyramid is a linear invertible image representation consisting of a set of band-pass images, spaced an octave apart, plus a low-frequency residual. Formally, let $d\left(.\right)$ be a downsampling operation which blurs and decimates a $j \time
paperswithcode.com
FCN 논문 리뷰 — Fully Convolutional Networks for Semantic Segmentation
딥러닝 기반 OCR 스터디 — FCN 논문 리뷰
medium.com
https://everyday-image-processing.tistory.com/32
논문 함께 읽기[3].Fully Convolutional Networks for Semantic Segmentation
안녕하세요. 오늘은 2015년에 나온 FCN이라는 약어로 유명한 Fully Convolutional Networks for Semantic Segmentation을 보도록 하겠습니다. 논문 출처 : https://people.eecs.berkeley.edu/~jonlong/long_shelha..
everyday-image-processing.tistory.com





댓글 영역