MF방식은 행렬을 분해하는 것이기 때문에 user 정보와 item 정보가 interaction된 합쳐진 행렬이 필수적으로 요구된다.
그러나 이 경우 두 가지 단점이 있다.
난관 0: 기존 MF의 문제들
1) 전체적인 행렬을 분해하여 정보를 얻어내는 것이기에 feature-level or aspect-level의 fine-grained 한 사용자 특성을 알아내기 힘들다. (이해한 바로는 행렬분해방식이 마치 Top-down 방식이라면 우리가 원하는 fine-grained 정보는 bottom-up방식에서의 bottom에 해당하는 듯하다.)
"추천 결과가 왜 이렇게 나오는지에 관한 interpretability를 요구하는 시나리오, user-item 추천이 아닌 친구 추천 또는 데이터 앱 매칭 등 social recommendation, 광고 예산 등 제약 조건을 준수해야 하는 online advertising과 같은 다른 시나리오에서는 앞서 논의한 CF의 기본 가정이 잘 들어맞지 않는 경우가 많다." (블로그 링크)
상호작용 데이터가 충분치 않아서사용자와 아이템의 latent factor를 잘 학습할 수 없는 경우를 Cold-Start Problem이라한다. 즉, 수집된 상호작용 데이터가 매우 적거나 존재하지 않는 사용자 또는 아이템에 관해 올바른 추천을 제공하기 어려운 상황을 뜻한다. 그래서 새로운 사용자에 관해서는 가장 인기 있는 아이템이 추천 결과로 나올 수 있다.(블로그 링크)
난관 1: diverse preference 미구현 문제
이 1) 2)의 문제를 해결하기 위해 과거 Side information 방식 등이 사용되었는데...
논문에서는 Side information 방식을 사용한 건 잘했지만 과거의 연구들에 또 다른 문제가 있다고 설명한다.
Althogh great progress has been achieved thus far, most existing recommender systems have not well considered to characterize user varying preferences for different items.
즉, 저자는 기존의 방식들이 사용자가 A영화와 B영화를 바라보는 방식이 다른데 둘을 같은 벡터로 해석하고 있으며 이를 다르게 해석해야 한다고 주장한다.
EX) 같은 사용자user라 할 지라도 방문한 음식점들에 대해 "음식점"이라는 동일한 카테고리라도 상황이나 목적에 따라
식당분위기ambience의 측면aspect를 중시한 item과 음식가격price의 측면aspect을 보고 선정한 item 등이 있을 수 있다.
이런 diverse preference 를 고려한 ALFM, A3NCF, and ANR 모델이 등장했었다. 그러나 이들 역시 dot product를 이용해 유사도를 구하는 MF(행렬 분해) 방식을 고수하고 있어서 MF의 탈피와 diverse preference 구현 두 마리 토끼를 모두 잡고 싶은 저자의 마음에는 들지 않는 것 같다.
"항목 i에 대한 사용자 u의 선호도를 예측할 때, 사용자u가 가장 관심을 갖는 항목 i의 측면aspect이 항목 i에 대한 사용자u의 선호도를 지배해야 합니다." 라고 한다.
EX)
모델로 user A가 공조2를 좋아하는 선호도를 예측할 때, user A가 공조2에 대해 배우 측면, 감독 측면, 장르 측면을 고려했고 배우 측면을 가장 많이 고려했다면,배우 측면이 user A의 공조2에 대한 선호도를 지배dominate해야 한다. (당연한 말인 거 같긴 한데 item에 대한 선호도에서 세부 aspects가 다르다는 것을 강조하는 문장인 것 같다.)
난관 2: dot product의 문제점
사실 MF의 문제가 2개 더 있는데 이들은 dot product에서 찾을 수 있다.
1) NOT satisfying the triangle inequality problem
추천시스템에서 MF방식(dot product)의 문제점
논문에 따르면 MF의 dot product가 삼각 부등식 triangle inequality을 만족하지 않기 때문에 그 모델은 사용자의 fine-grained 한 특성을 잡아내지 못한다고 한다. (metric based learning을 위해서는 distance가 삼각부등식을 만족해야 한다.)
그래서 metric collaborative filtering (CML) method 라는 방식으로 users와 items의 각 쌍들을 하나의 저차원에 몰아 넣으려 시도했다고 한다. 그런데 이 CML 때문에 두 번째 문제가 발생한다.
2) Geometrically restrictive problem
users와 items의 paired 데이터 쌍들을 하나의 저차원 공간에 mapping 하는 것이 CML 방식이다. 그러나 이 방식은 한 user가 선택한 여러 items 의 경우와 하나의 items를 선택한 사용자들의 경우. 이 두 경우 모두 고려해야 하는 diverse preference를 구현하기가 쉽지 않다.
이 문제를 해결하기 위해 드디어 MAML(Multimodal Attentive Metric Learning) 모델이 등장하게 된다. 이 모델에서는 Attentive neural network를 사용해 Weight vector를 사용함으로써 위에서 계속 언급했던 단점을 극복한다.
이해가 잘 안 될 수 있어서 아래 모델 설명 마무리 단계에서 설명하겠다.
즉, MAML은
1) dot product 대신 metric based learning을 사용하므로 triangle ineqality를 만족한다
2) users가 다양한 items에 대해 다른 선호도를 가지는 diverse preference를 구현할 수 있다
는 장점을 가진다.
2. MAML 모델 과정
일단 아래 사진에는 한명의 User가 있고 Positive item_i , Negative item_k가 있다. user와 i, user와 k의 distance를 구해 loss를 구하는 과정인 것이다.
* negative는 user_u가 고르지 않았던 item을 의미합니다.
그래서 우리가 attentive model로 얻고자하는 값은 무엇일까
Positive Item(i) 와 User(u)를 통해 distance_u,i를 구하고 Negative Item(k) 와 User(u)를 통해 distance_u,k를 구하는 것.
그 다음은 Loss function에 적용만 하면 된다.
그럼 문제를 쪼개서 대표적으로 Positive Item(i) 와 User(u)를 통해 distance_u,i를 구하는 과정을 그림 상 위에서 아래로 내려가면서 살펴보자.
1. DISTANCE of users and items
Figure 2: Figure 1의 왼쪽 위를 살펴보자
distance 공식은 user와 item의 Euclidean 거리를 기본으로 한다. 다만 user(p_u) 와 item(q_i)의 각 항에 측면aspect를 고려하기 위해 attention module을 거친 가중치를 곱해야 한다.
그리고 각 항에 가중치를 적용할 때 element-wise product ⊙를 사용한다. (matrix size는 연산 후 바뀌지 않는다.)
아주 간단한 element-wise product ⊙ 예시 사진
그래서, Figure 2의 노란 형광펜 부분 3개가 input으로써 필요하다. p_i와 q_u는 이미 주어진 것을 그대로 사용하므로
이 weight vector 만 구하면 된다.
2. Weight Vector by attentive module
Figure3: Attentive module을 통해 구해지는 weight vector(a_u,i)
attentive module을 설명하기 전에 input을 본격적으로 살펴보자. 저자가 기존에 언급했던 해결책 중에 side-information 을 추가하는 방법이 있음을 기억한다면, user의 ID, item의 ID 는 paired 된 데이터이고 Text, Image 데이터가 외부 정보side-information인 것을 눈치챌 수 있을 것이다.
이 side-informaiton들을 multimodal model을 이용하여 융합하면 성능이 더 좋아진다고 한다. 논문에서는 각각의 Text와 Image를 가공하는 방식은 References로만 언급했다.
Nitish Srivastava and Ruslan R Salakhutdinov. 2012. Multimodal learning with deep boltzmann machines. In NIPS. MIT press, 2222–2230
Hanwang Zhang, Yang Yang, Huanbo Luan, Shuicheng Yang, and Tat-Seng Chua. 2014. Start from Scratch: Towards Automatically Identifying, Modeling, and Naming Visual Attributes. In MM. ACM, 187–196.
어쨋든 visual feature (F_v,i)와 text feature(F_t,i)를 융합하여 Z_L == F_tv,i를 만든다.
이때 W_1, W_2 and b_1, b_2 denote the weight matrix and bias vector for the 1st, 2nd layer.
이미지와 텍스트를 융합하는 과정.
이제 Attentive Module에 넣을 Input 3개( item 데이터, 융합된 side-information, user 데이터)가 준비되었다.
아래의 Attentive Module에 Input 3개와 W, b를 넣어 weight vector를 구했다.
Attentive Module: weight vector 를 추정하는 과정.
이다. 이는 사용자 u가 아이템 i 에서 가장 많이 본 측면aspect 의 중요도를 나타낸다.
4. 기타
MAML이 Geometrically restrictive problem을 해결할 수 있었던 이유
이제 아까 이해가 어렵다고 했던 2) Geometrically restrictive problem 의 해결에 대해 다시 설명한다.
user-item pair라는 말이 애매하다. 여기서의 pair는 나(user)와 내가 좋아하는 영화(Positive items_i) 두 벡터들의 조합을 발하는 것이다.
EX) (user_1, 공조2), (user_1, 한산), (user_1, 탑건)
이때 CML의 문제는 user_i의 영화 선호도를 분석할 때 하나의 저차원으로 mapping 했다는 점이다.
이와 달리 MAML은 각 영화별로 mapping을 진행하기 때문에 diverse preference를 구현했다고 하는 것이다.
(본인은 "각 영화별로 다르게 mapping 했다"를 각 영화마다 다른 측면들aspect[배우, 감독, 제목 등]이 존재하기에 attention weight를 다르게 설정했다고 이해했다)
cf) unique user-item pair, different aspect, weight vector 관계 설명
우리의 MAML 모델은 각 사용자 항목 쌍에 가중치 벡터를 도입하여 CML 방법을 향상시킵니다. 이가중치 벡터는 대상 항목의 다양한 측면에 대한 사용자의 관심을 나타내므로 각 사용자-항목 쌍에 대해 고유unique합니다. 이것은 이 항목의 텍스트 및 시각적 기능을 활용하여 대상 항목에 대한사용자 주의attention를 분석하는 설계된 attention 신경망에 의해 달성됩니다.
자세한 설명은 위 블로그에게 맡기고 간단히 정리하자면 Paired Loss를 위해 ranking loss weight(w_u,i)가 필요하고 이는 연산문제 때문에 WARP를 이용해 근사한다. 그리고 Regularizaiton을 거쳐 SGD 혹은 Adam Optimization을 통해 최종 모델을 완성한다.
1) 모델을 효과적으로 비교하고 평가하기 위해 Side-information을 적절히 사용했다.
제일 처음에는 Only paired data 만 사용(NO side-information)
두번째는 paired data & text data
세번째는 paired data & image data
네번째는 paired data & all Side-information
으로 구현했다고 하며 성능은 Side-information을 모두 사용한 모델이 가장 좋았다.
2) Weight Vector의 여부
이 논문의 차별점은 역시 diverse preference를 구현하려고 attentive module로 weight vector(attention vector)를 사용했다는 점이다. 그 관점에서 weight vector가 정말 유용했는지 성능을 평가했는데 위에 보다시피 가중 벡터가 있을 때 성능이 항상 더 좋았다는 것을 확인할 수 있다.
7. Visualization
attention vector가중 벡터 시각화
위 사진이 중요한 이유는 Geometrically restrictive problem을 해결하기 위해 다양한 가중치가 생성된 모습이 시각화 되었기 때문이다.
두 데이터 셋에 대한 최종 선호도 시각화
8. Conclusion
MAML은 top-n recommender로써 특히, item의 aspects에 대한 user의 다양한 선호도를 구현한 것이 큰 특징이며
이를 위해 Attentive neural network가 사용되었다.
기존 MF(행렬 분해)에서는 fine-grained user preference을 잡아내지 못했지만 Metric based learning을 통해 가능케 했다






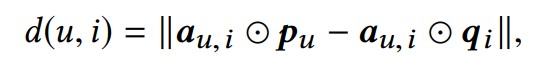





















댓글 영역