고정 헤더 영역
상세 컨텐츠
본문
작성자 : 김지후
1. Introduction
셀프 트레이닝(self-training) 방법인 ELMo, GPT, BERT, XLM, XLNet은 상당한 성능의 개선을 이루어냈습니다. 그러나 방법의 어떤 측면이 기여했는지에 결정하기 어렵습니다. 학습의 과정은 무거워 제한된 튜닝이 가능합니다. 그리고 private 학습데이터를 사용해 모델링의 영향을 측정하는 것이 제한됩니다.
본 논문은 **BERT의 재현 연구(Replication study)**를 통해 하이퍼파라미터의 영향과 학습데이터 셋의 영향을 보여줍니다. 그리고 BERT가 완벽하지 않고 성능이 개선될 수 있음을 확인했습니다. 그렇게 개선한 모델이 RoBERTa입니다.
수정 사항은 다음과 같습니다.
(1) 모델을 더 길고, 더 큰 배치 사이즈로 학습
(2) next-sentence prediction objective를 삭제
(3) 긴 시퀀스의 데이터로 학습
(4) 학습데이터에 동적 마스킹 패턴을 사용.
그리고 학습 데이터 셋 사이즈의 영향을 잘 컨트롤하기 위해 새로운 큰 데이터셋 CC-News를 수집했습니다.
요약하자면, 본 논문의 기여는 다음과 같습니다.
(1) BERT의 중요한 design 요소와 학습전략을 소개하고 하위 태스크에서 좋은 성능을 보여주는 대안을 제시
(2) 새로운 데이터 셋인CC-News를 사용하고, 사전학습에 더 많은 데이터를 사용하는 것이 하위 태스크의 성능을 향상시킴을 확인
(3) 논문에서 보여준 성능의 향상은 마스킹된 사전학습 언어 모델이 여전히 경쟁력있음을 보여줌
2. Background
이번 섹션에서는 BERT에 대한 간단한 리뷰를 보여줍니다.
2.1 Setup

BERT는 두 segment와 특별 토큰(special tokens)결합을 입력으로 합니다. 여기서 segment는 하나 이상의 자연어 문장으로 구성됩니다 :
<aside> 💡 [CLS], x_1, .... x_N, [SEP], y_1, ... y_M, [EOS].
</aside>
(M + N < T , T는 최대 시퀀스 길이를 나타내는 모수).
모델은 먼저 라벨링 되지 않은 큰 텍스트 코퍼스에서 사전학습(pretrained)되고 그 후 end-task 라벨링 데이터를 사용해 파인튜닝(finetuned)됩니다.
2.2 Architecture
L개의 layer와 각 block에서 A개의 self-attention head, 그리고 hidden dimension H를 가진 Transformer 아키텍쳐를 사용했습니다.
2.3 Training Objectives
사전학습 과정에서 BERT는 다음의 두가지 objective를 사용합니다.
Masked Language Model(MLM)
- 입력 시퀀스 토큰 중에서 15% 토큰이 랜덤하게 선택되고 [MASK] 토큰으로 대체
- MLM objective는 마스킹된 토큰을 예측하기 위해 cross-entropy loss가 사용
- 15%의 토큰 중에서 80%는 [MASK]로 대체되고 10%는 바뀌지 않으며, 나머지 10%는 랜덤하게 선택된 단어토큰으로 대체
Next Sentence Prediction(NSP)
- NSP는 두 segment가 Next Sentence인지 판별하는 binary classification loss
- Positive example은 연결된 두 문장을 가져와서 만들었고 Negative example은 서로 다른 문서에서 segment를 가져와 만들어 졌음.
- NSP objective는 두쌍의 문장의 관계가 중요한 자연어추론과 같은 하위 태스크에서 성능개선을 하기위해서 디자인되었습니다.
2.4 Optimization
- Adam
- learning rate는 처음 10,000 step부터 최고 1e-4까지 예열되고 선형적으로 줄어든다.
- BERT는 모든 레이어와 어탠션 가중치에 대해 dropout 비율 0.1과
- GELU 활성함수
- 모델은 S = 1,000,000 업데이트
- 미니배치 B= 256,
- 최대길이 T = 512 토큰으로 사전학습
2.5 Data
BERT는 BOOKCORPUS와 English WIKIPEDIA를 결합해 총 16GB의 텍스트를 사용했습니다.
4. Training Procedure Analysis
BERT를 성공적으로 하기 위해 학습하기 위해 중요한 요소에 대해서 수량화합니다. 모델의 아키텍쳐는 BERT base(L =12, H, 768, A =12, 110M params)로 고정하고 진행합니다.
4.1 Static vs Dynamic Masking
BERT는 랜덤하게 마스킹하고 토큰을 예측하는 것에 의존합니다. 기존의 BERT는 데이터 전처리 과정에서 한번 마스킹을 시행합니다. 즉 single static mask입니다. 각 에포크마다 같은 마스크를 사용하는 것을 방지하기 위해서 학습데이터를 10번 복제되고, 40 에포크 동안 각 시퀀스는 10개의 다른 방법으로 마스킹됩니다. 따라서 각 학습 시퀀스는 같은 마스크를 4번 볼 수 있습니다.
이러한 방법을 모델에 각 시퀀스를 입력할 때마다 마스킹 패턴을 생성하는 dynamic mask와 비교합니다. 이 방법은 더 많은 스탭으로 학습하거나 더 큰 데이터셋으로 학습할때 중요합니다.
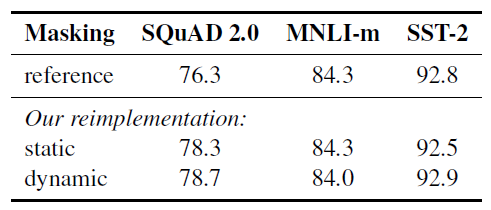
이 표는 BERT Base를 사용해서 비교했을 때의 결과 입니다. 논문에서 재시행한 static은 기존의 BERT 모델과 비슷한 결과를 보여줬습니다. Dynamic Masking은 Static Masking 과 성능이 비슷하거나 조금 더 좋은 성능을 보였습니다.
4.2 Model Input Format and Next Sentence Prediction
기존 BERT의 사전학습 과정에서 모델은 두 합쳐진 문서 segment(이때 두 segment는 같은 문서에서 인접하거나, 떨어진 다른 문서에서 샘플링됩니다)를 사용합니다. 마스킹을 사용한 언어모델 목적함수와 더불어 Next Sentence Prediction loss을 사용해서 segment가 같은 문서에서 왔는지 아니면 다른 문서에서 왔는지 예측하도록 학습됩니다.
NSP Loss는 기존 BERT 모델에서 중요한 요소로 강조되었습니다. 그러나 몇가지 최근 연구들은 NSP의 필요성에 대해서 의문을 제시했습니다. 본 연구에서 NSP의 타당성을 확인하기 위해 다음의 학습데이터를 구성했습니다.
- SEGMENT-PAIR + NSP: 기존 BERT에서 사용한 입력값과 동일한 설정입니다. NSP Loss를 사용합니다. 각 입력의 segment는 multiple natural sentences를 가질수 있지만 합쳐진 총 길이는 512개 이하의 토큰 이여야합니다.
- SENTENCE-PAIR + NSP: NSP Loss를 사용합니다.각 segment는 하나의 문장(sentence)쌍 으로 구성됩니다. 이때 문장쌍은 하나의 문서의 인접한 부분에서 샘플링되거나 분리된 문서에서 샘플링됩니다. 이때 입력값이 대부분 512 토큰 보다 짧기 때문에 배치 사이즈를 늘려, SEGMENT-PAIR 방식과 총 토큰 수가 비슷해지도록 했습니다.
- FULL - SENTENCES: NSP Loss를 사용하지 않습니다. 각 입력은 하나이상의 문서에서 인접하게 샘플링된 full sentence로, 총 길이는 최대 512토큰 입니다. 하나의 문서에 끝에 도달했을 때, 다음 문서에서 문장을 샘플링하기 시작하고 두 문서간의 extra separator token를 추가합니다.
- DOC - SENTENCES: 입력값은 문서간의 경계를 넘어서지 않는다는 점을 제외하고는 FULL-SENTENCES와 비슷하게 구성됩니다. 문서의 끝에 가까운 곳에서 샘플링된 입력은 512 토큰 보다 적을 것이기 때문에 FULL-SENRENCES와 총 토큰 수가 비슷해지도록 하기 위해서 배치 사이즈를 크게 증가시킵니다.

위의 표는 4가지 다른 세팅에서의 결과를 보여줍니다. 먼저 SEGMENT -PAIR와 SENTENCES - PAIR를 비교했을 때, 모두 NSP Loss를 사용합니다. 단일 문장을 쌍으로 사용하는 것(SENTENCE-PAIR)은 모델의 성능을 떨어트립니다. 모델이 long-range dependency를 학습할 수 없기 때문입니다.
NSP loss를 사용하지 않는 것과 BERT-base를 비교하면, NSP loss를 사용하지 않았을 때 하위 태스크의 성능이 비슷하거나 조금 개선되었습니다.
마지막으로 **하나의 문서에만 시퀀스를 가져오는 것(DOC - SENTENCES)**이 여러 문서에서 시퀀스를 가져오는 것(FULL - SENTENCES)보다 조금 더 좋은 성능을 보였습니다. 그러나 DOC -SENTENCES는 다양한 배치사이즈를 가지기 때문에 공정성을 위해 앞으로의 실험에서 FULL - SENTENCES를 사용합니다.
4.3 Trainnig with large batches
이전 연구인 Neural Machine Translation에 따르면, learning rate가 적절하게 증가할 때 아주 큰 mini-batches를 사용한 학습은 최적화 속도와 성능 모두를 개선시킬 수 있습니다. 최근의 연구는 BERT가 또한 큰 배치 학습에 긍정적인 영향을 준다는 것을 보여줬습니다.

표에서 BERT base로 배치사이즈를 증가하면서 Perplexity와 성능을 비교결과를 보여줍니다. 큰 배치로 학습하는 것은 Perplexcity를 개선하고 정확도를 올립니다. 또한 큰 배치들은 분산 데이터 병렬 학습을 통해 병렬화하기 더욱 쉽다고 합니다.
4.4 Text Encoding
Byte-Pair Encoding(BPE)는 character 그리고 word-level representaion의 합성입니다. 이는 큰 어휘목록에 대해서도 처리할 수 있도록 합니다. 모든 단어를 사용하는 대신에, BPE는 학습 코퍼스에서 통계적 분석에 따라 추출된 subword unit에 의존합니다. byte를 사용한 BPE는, Unknown 토큰 없이도, 50K units의 서브워드 사전으로 학습을 진행할 수 있습니다.
기존의 BERT는 character level의 BPE를 사용했습니다. RoBERTa는 추가 전처리나 토크나이징 없이 larger byte-level BPE로 학습을 진행합니다.
Byte level BPE는 몇 개의 태스크에서 성능이 떨어진다는 단점이 있지만, 성능 하락폭이 크지 않고 universal 인코딩의 장점이 있다고 판단하여 본 연구에서 Byte level BPE를 적용하였습니다.
5. RoBERTa
이전 섹션에서 성능을 올리기 위한 BERT의 개선에 대해서 소개했습니다. 앞선 개선을 종합한 모델이 Robustly optimized BERT approch인 RoBERTa입니다.
구체적으로, RoBERTa는 동적마스킹(dyamic masking), NSP loss를 사용하지 않는 FULL - SENTENCES, 큰 미니 배치(mini-batches), larger byte-level BPE를 사용합니다.

RoBERTa가 기존에 제시된 BERT에 대해서 큰 개선을 보여줍니다.
5.1 GLUE Results

single-task에서 RoBERTa가 9개의 모든 태스크에 대해서 SOTA를 달성합니다. 결정적으로 RoBERTa는 BERT와 같은 마스킹을 사용한 사전학습 언어모델 목적함수와 구조를 사용하면서도 더 좋은 성능을 보여줍니다. 이는 모델 구조와 목적함수보다 데이터 사이즈나 트레이닝 시간과 같이 본 논문에서 탐구한 모델의 디테일의 중요성을 보여줍니다.
5.2 SQuAD Results

SQuAD v1.1에서 XLNet이 SOTA이지만 SQuAD v2.0에서 RoBERTa가 새로운 SOTA를 달성합니다.
5.3 Race Results
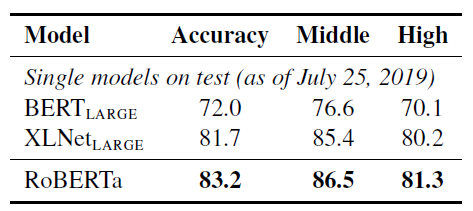
중학교, 고등학교 셋 모두에서 RoBERTa가 SOTA를 달성했습니다.
6. Conclusion
BERT 모델를 사전학습할 때의 design 요소에 대해서 평가했습니다.
(1) 모델을 더 길고, 더 큰 배치 사이즈로 학습시킬 때
(2) next-sentence prediction objective를 삭제할때,
(3) 긴 시퀀스의 데이터로 학습할때,
(4) 학습데이터에 동적 마스킹 패턴을 사용할 때 성능이 크게 향상됨을 확인했습니다.
본 논문에서 제시한 사전학습 절차은 RoBERTa라고 부르며, GLUE, RACE 그리고 SQuAD에서 SOTA를 달성했습니다. 이 결과는 이전에 간과한 design 요소들의 중요성을 강조하고, 개선을 한 BERT 사전학습 모델의 경쟁력을 보여줬습니다.





댓글 영역