고정 헤더 영역
상세 컨텐츠
본문 제목
[Advanced ML & DL Week4] Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing Deep Models
본문

https://arxiv.org/pdf/2208.06677.pdf
(Arxiv preprint)
제목 : Adan: Adaptive Nesterov Momentum Algorithm for Faster Optimizing Deep Models
저자 : Xingyu Xie1,2, Pan Zhou1, Huan Li3, Zhouchen Lin2, Shuicheng Yan1
(1 Sea AI Lab 2 Peking University 3 Nankai University)
업로드일 : [Submitted on 13 Aug 2022 (v1), last revised 18 Oct 2022 (this version, v3)]
논문 소개
딥러닝 모델 최적화를 위한 Optimizer는 많은 발전을 거듭해왔습니다. SGD부터 시작해서 AdamW까지 Momentum, Adaptive method, weight decay 등의 방법이 적용되어 딥러닝의 발전을 이끌어왔다고 볼 수 있죠. 다만 그 발전상의 중간에 위치한 Nesterov(혹은 Nesterov's Accelerated gradient decent, AGM or NAG)는 별다른 주목을 받지 못했습니다. Nadam 등의 optimizer로 적용되긴 했지만 SOTA optimizer라고 불리기엔 한계가 있었습니다.
이번 논문은 그런 Nesterov를 재조명하여 개선방안을 도출하고 나아진 성능을 이론적으로 증명합니다. 또한 현재 많이 쓰이고 있는 ViT모델 등에 직접 실험해보고 여러 SOTA optimizer와 비교하는 과정이 포함되어 있습니다. (다만, 해당 논문은 지난 8월에 처음 Arxiv에 투고되었고 최근 수정일자도 한 달 전(2022년 11월 2일 기준)일 정도로 최신 논문이기 때문에 아직 광범위하게 검증되지 않은 점을 유의해주세요.)
1 Introduction
먼저 Nesetrov를 포함한 optimizer 전반에 관한 사전 지식이 필요합니다. 해당 내용은 이전에 작성했던 블로그 글을 참고해주세요.
https://kubig-2022-2.tistory.com/44
[Advanced ML & DL Week1] ADAM: A Method For Stochastic Optimization
kubig-2022-2.tistory.com
해당 논문은 Adan optimizer를 새로 제시했습니다. 아래 표는 다른 optimizer와 비교한 표입니다.

여기서 Adam-type에는 Adam, Adamomentum, AdaGrad, AMSGrad가 포함되어 있습니다.
표에서 'Separated Reg.'라는 항목은 목적함수에서 l2 regularizer가 분리될 수 있는지 여부입니다. Adan이 AdamW과 함께 이 부분에서 우위를 가지고 있습니다.
위 표는 다른 모델에서의 optimizer 성능 차이를 보여주지 않습니다. 예를 들어, CNN에서는 SGD가 제일 성능이 높으나, ViT에서는 SGD는 학습에 자주 실패하고 AdamW가 성능과 안정성 면에서 더 나은 결과를 보여줍니다. 하지만 어떤 optimizer라도 분산학습에 기본 옵션으로 쓰이고 있는 큰 batch에서의 학습에서는 실패하는 경향을 보입니다. 학습 시간을 줄이려면 계산 시간을 줄이고 메모리 복잡성도 개선해야 하는데 저자들은 NAG를 기반으로 한 새로운 optimizer를 제시합니다.
Contribution
먼저 Nesterov의 방법을 소개하면 다음과 같습니다.

Gradient를 다음과 같은 식으로 구하는데 momentum optimizer와 다르게 현재 point가 아닌 extrapolation point에서의 gradient를 구합니다. extraploation point는 다음과 같습니다.
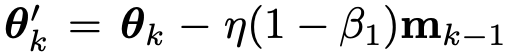
현재 momentum 성분을 반영한 1 step 뒤에서의 point를 extrapoint로 정의합니다. 이렇게 구한 extrapolation point의 gradient를 통해 momentum을 계산합니다.

그 후, momentum 성분을 이용해 다음 state를 계산합니다.

이 과정을 기존 momentum 과정과 비교하면 다음과 같습니다.

이 과정에서 extrapolation point에서 gradient를 계산하는 것은 기존 방법과 비교해서 추가적인 계산과 메모리를 잡아먹게 됩니다. 이를 해결하기 위해 새롭게 제시된 Nesterov Momentum Estimation(NME)라는 방법을 사용합니다.
먼저 기존 방법대로 gradient를 계산합니다.

그리고 Nesterov 방법과 마찬가지로 이동평균이 적용된 momentum을 계산하는데 여기서 g_k'를 사용하는 것이 다릅니다.

g_k'는 다음과 같은 식으로 표현될 수 있습니다.

수식을 잘 들여다보면 g_k'는 현재 state의 gradient에 현재 state와 바로 전 state에서의 gradient 차이를 이동평균으로 누적한 값으로 볼 수 있습니다. 단순히 보면 Vanilla Nesterov와 차이점이 없는 것처럼 보이지만 Nesterov에서 진행된 extrapolation point 구하기, 그 지점에서의 gradient 구하기 같은 계산을 생략하면서도 비슷한 매커니즘으로 동작하기에 계산력 면에서 이득을 얻으면서 Nesterov의 이점을 취할 수 있습니다. 이 NME 방법으로 예상한 g_k'를 g_k, 즉 현재의 gradient로 간주한다면 이를 확장하여 Adam 방법과 같이 표현할 수 있는데 이를 Adan이라고 명명하고 있습니다.
그렇다면 NAG와 Adam을 결합했다고 알려진 Nadam과 Adan은 어떤 차이점이 있을까요? Nadam은 extrapolation point를 참조하지 않으며 lookahead처럼 동작하지 않습니다. 간단히 말하면 미래를 반영하여 학습하지 않습니다. 또한, 1차 모멘트만을 사용하는 것이 Adan과 다른 점입니다.
논문에서는 Adan의 장점을 다음과 같이 소개합니다.
1) Smooth Hessian condition이 아닐 때

의 stochastic gradient complexity를 가지고

의 하계 조건을 가집니다. 이는 Adan이 AdaBelief와 LAMB optimizer를 일반적으로 앞선다고 볼 수 있습니다. 또한, Adam 계열 optimizer와 달리 l2 regularizer를 분리할 수 있습니다. 다른 논문에서 이런 일반화 과정은 성능에 도움이 된다고 알려져 있습니다.
2) Smooth Hessian condition에서

의 stochastic gradient complexity를 가지고

의 하계 조건을 가집니다. 이는 A-NIGT와 Adam+보다 앞서는 수치입니다.
3) 마지막으로 Adan은 CNN과 Transformer 모델에서 다른 SOTA optimizer들을 앞섰고 ResNet, ConvNext, ViT, Swin, MAE, LSTM, TransformerXL 같은 다른 모델과 세팅에서도 새로운 SOTA를 달성했습니다. 그리고 절반에 해당하는 epoch로도 ResNet, ViT, Swin 모델에서 목표한 성능을 달성했으며 ViT에서는 large-batch에서도 잘 동작했습니다.
3 Methodology
g_k'를 통해 Vanilla Adan을 다음과 같이 정의할 수 있습니다.

여러 가정과 단순화를 통해 아래와 같은 최종 알고리즘을 만들 수 있습니다.

5 Experimental Results

Vision Tasks

ViTs

LSTM, Transformer-XL, BERT-base model

Reinforcement Learning Tasks

Robustness

작성자 : 16기 이은찬





댓글 영역