고정 헤더 영역
상세 컨텐츠
본문 제목
[Advanced ML & DL Week4] BERT4Rec: Sequential Recommendation with BERT
본문
0 Abstract
추천 시스템에서 사용자(user)의 dynamic preference를 학습하는 것은 어렵고도 중요한 문제이다.
이전에는 이런 문제를 Sequential Neural Network로 다루었다.
왼쪽에서 오른쪽으로 사용자의 과거 상호 작용을 숨겨진 표현으로 인코딩하는 방식이었다.
그러나 이 방식은 두 가지 문제를 가진다.
a) 단방향 구조는 사용자의 행동 시퀀스에서 숨겨진 표현의 효과를 제한한다.
b) 엄격하게 정렬된 순서를 가정하기 때문에 실용적이지 않다.
그래서 저자는 BERT4Rec을 제안한다.
이 모델은 deep bidirectional self-attention을 사용하는 순차적 추천 모델이다.
그리고 정보의 누수 없이 효율적으로 양방향 학습을 하기 위해 Cloze objective 를 도입했다.
Cloze objective는 왼쪽 및 오른쪽 context에서 공동으로 조건화하여, 랜덤하게 가려진 시퀀스의 item을 예측한다.
이로써 사용자user의 과거 행동의 각 item이 왼쪽과 오른쪽의 정보를 융합fuse하도록 허용한다.
그리고 BERT4Rec을 이용해 당시 다양한 추천 시스템 데이터셋에서 S.O.T.A를 달성했다고 한다.

1 INTRODUCTION
sequential dynamics in user behaviors이란?
사용자들은 자신의 과거 행동에 영향을 받고 현재의 관심이 본질적으로 역동적dynamic이고 진화한다는 것.
EX) 닌텐도 Switch가 없을 땐 콘손 컨트롤러 키링 악세서리에 관심 X, 그러나 닌텐도 구매 후 콘솔 액세서리 키링 구매.
: 과거 행동( 과거 구매 내역; nintendo), 관심 변화(콘솔 컨트롤러 키링 악세서리 구매)
이를 구현하기 위해 최근까지도 RNN 등과 같은 sequential NN 으로 user의 과거 상호작용을 벡터로 인코딩해왔다.
이 방식은 효율적이고 많이 사용되지만 unidirectional 모델이기 때문에 이전 항목item에서 얻은 정보만 encoding 할 수 있어서 item에 대한 hidden representation을 충분히 찾아내지 못한다.
또, 어떤 외부 요인으로 인해 반대 방향으로의 영향도 존재할 수 있는 상황에서 무조건 단방향 모델만을 고집하는 것은
적절치 않을 수 있다.
BERT의 성공에 영감을 얻어 양방향의 context를 통합하기 위해 BERT를 사용했고
이 논문에서 BERT4Rec이 우수한 성능을 보였기에 양방향 context의 통합의 효과가 있었다고 말한다.
그러나 이게 단순하지 않다.
deep bidirectional model에서 왼쪽 및 오른쪽 context를 jointly하게 조건화하면 정보의 누출이 발생한다.
왜냐하면 right to left의 경우 target item을 간접적으로 봐버리는 개념이기 때문이다. 이렇게 되면 네트워크를 만드는 의미가 없어지고 예측력이 많이 떨어진다고 한다.
그래서 Cloze task를 도입하여 단방향 모델을 사용해서 양방향 모델을 구축한다고 한다.(???)
HOW?
1. 랜덤으로 몇몇 items를 [MASK] 라는 special token으로 대체한다.
2. [MASK]의 주변 정보들을 이용하여 item의 ids를 예측한다.
위 방식으로 input 시퀀스의 각 item이 좌우의 정보를 융합하도록 허용함으로써 information leakage를 피할 수 있고 양방향 학습이 가능하다고 한다( 이해 안됨)
Cloze objective의 또 다른 장점은 여러 에포크에서 더 강력한 모델을 훈련하기 위해 더 많은 샘플을 생성할 수 있다는 것이다.
HOWEVER
Cloze test의 결과는 sequential recommenter의 최종 결과의 형식과 맞지 않다.
그래서 테스트 중에 입력 시퀀스의 끝에 특수 토큰 [MASK]를 추가하여 예측해야 하는 항목을 표시한 다음 최종 은닉 벡터를 기반으로 추천을 한다고 한다.( 논문 글 순서 왜 이럼~ 킹받게)
그래서 이 논문의 차별점!
- Cloze task를 통해 양방향 self-attention 네트워크로 사용자의 행동 시퀀스를 모델링할 것을 제안한다.
- 깊은 양방향 순차 모델deep bidirectional sequential model과 Cloze task를 추천 시스템 분야에 도입한 첫 번째 연구다.
- BERT4Rec을 SOTA 모델과 비교하고 4개의 벤치마크 데이터 세트에 대한 정량적 분석을 통해
양방향 아키텍처와 Cloze task의 효율성을 입증했다. - 제안된 모델에서 주요 구성 요소의 기여도를 분석하기 위해 포괄적인 절제 연구 ablation study를 수행한다.
2 RELATED WORK
2.1 General Recommendation
기존의 추천 시스템에서는 사용자의 선호도를 모델링하기 위해 협업 필터링(Collaborative Filtering: CF)을 사용해 왔다.
그중 행렬분해(Matrix Factorization: MF)가 가장 널리 사용되었는데
MF는 user와 item을 공유 벡터 공간에 투영하고 벡터 사이의 내적으로 항목에 대한 사용자의 선호도를 추정한다.

2.2 Sequential Recommendation
불행히도 2.1에서 언급한 모델들은 users' behaviors의 순서를 무시하기 때문에 sequential recommendation이 아니다.
더보기
순차적 추천을 위한 모델들 나열...
그래서 초기 모델에서는 Markov chains(MCs)로 sequential recommendation을 구현했다.
(e.g. Markov Decision Processes (MDPs); Factorizing Personalized Markov Chains (FPMC);)
최근에는 RNN기반, Gated Recurrent Unit (GRU)와 LSTM이 사용자 행동의 순서를 모델링하는데 더 많이 사용된다.
그 외에도, GRU4Rec, Dynamic REcurrent bAsket Model (DREAM), user-based GRU, NARM 등 수많은 모델들이 존재한다.
신경망을 쌓는 것 외에도 순차적 추천을 위한 다양한 딥러닝 모델이 도입되었다.
예를 들어, Convolutional Sequence Model (Caser)는 수평적 수직적 conv filters를 사용하여 순차적 패턴을 학습했으며 그 외에도 Memory Network를 활용한 모델, STAMP 모델 등이 있다.
Sequential recommendation이 사용자 행동의 순서를 모델링하는 기본 아이디어는 다양한 반복 구조들과 loss functions을 활용해 사용자의 과거 행동들을 벡터로 인코딩하는 것이다.
2.3 Attention Mechanism
Attention mechanism은 기계번역이나 텍스트 분류와 같은 순차적 데이터를 모델링하는데 유망한 가능성을 보여왔다.
최근에 attention mechanism으로 추천 시스템의 성능과 설명 가능성을 높이려는 시도들이 있었다.(논문)
그러나 위 작업은 Attention mechanism을 기존의 모델의 부가적인 요소로 사용한 것이다. 반면 Transformer와 BERT는 오딕 multi-head self-attentiion(설명)에 기반하고 텍스트 순차 모델링에서 당시에 SOTA를 달성했다. 그래서 최근 순수하게 Attention mechanism으로 기반된 NN으로 순차적 데이터를 모델링하려는 붐이 일고 있다고 한다.
3 BERT4REC
용어 정리 Notation settings ; 모델 구조 설명;
3.1 Problem Statement
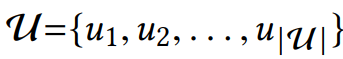
: 사용자의 집합(set of users 1~ |u|명)

: 항목들의 집합(set of items 1~|v|개)

: u라는 사용자의 interaction sequence를 시간 순서대로 표현한 리스트.
v(u) t는 시간 t에서 u라는 사용자가 상호작용(구매, 긍정평가 등)한 항목(item)이고,
n_u는 상호작용 한 item의 개수를 나타낸다.
사용자 u의 과거 상호작용 데이터 Su가 주어졌을 때 우리의 목표는 바로 다음의 미래 (n_u + 1 time)에서 사용자 u가 상호작용할 item v(u)는 무엇일지 예측하는 것이다. 이를 도식화하면 다음과 같다.

3.2 Model Architecture
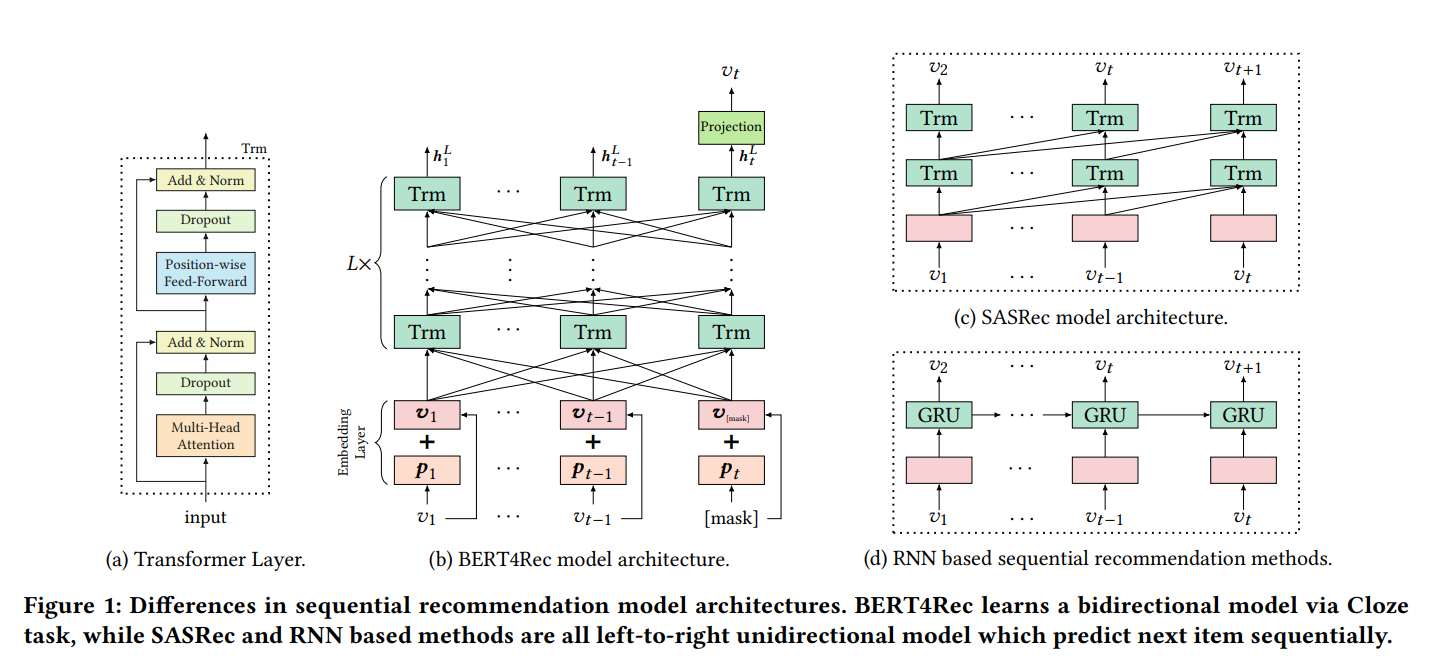
BERT4Rec 모델 구조 소개(Bidirectional Encoder Representations from Transformers for sequential Recommendation)
이 모델은 유명한 self-attention 층인 "Transformer layer"을 기반으로 만들어졌다.
Figure 1.(b) 에서 초록색을 보면 L 개의 양방향 Transformer layer(Trm)들이 쌓여있는 걸 볼 수 있다.
각 Trm은 직전의 t개의 Trms 들 모두와 병렬적으로 정보를 바꾸면서 표현에 수정을 가한다.
Figure 1.(d) 를 보면 RNN은 초록색 노드들이 정보를 주고받으려면, 같은 layer에서 반복적으로 정보를 전달해야 하지만,
BERT4Rec은 이전 layer로부터 직접적으로 정보를 전달받기 때문에 노드의 거리에 상관없이 정보를 전달할 수 있다.
이로써 global receptive field을 도출할 수 있고, 병렬화parallelize하는 것이 간단해진다.
양방향의 self-attention을 사용하는 BERT4Rec을 통해 더 강력한 사용자 행동 시퀀스를 얻을 수 있다.
반면, 1.(c)와 1.(d)는 각각 SASRec 와 RNN의 구조를 나타낸 것인데 왼쪽에서 오른쪽으로만 가는 단방향 구조다.
3.3 Transformer Layer
Figure 1.(b)에서 볼 수 있듯, 길이 t의 입력 시퀀스가 주어졌을 때 l개의 Transformer layer를 적용하여 각 위치 i에 대해 각 레이어 l에서의 은닉 표현 h_l_i를 반복적으로 계산한다.
그리고 모든 위치애서 동시에 attentiont 함수를 적용하기 때문에 t개의 h_l_i를 합쳐서 H_l 라는 matrix를 만든다.

Figure 1.(a)를 보면 하나의 Trm (Transformer layer)은
Multi-Head Self-Attention sub-layer 와 Position-wise Feed-Forward Network라는 두 개의 sub-layer들로 구성된다.
Multi-Head Self-Attention 이란?
attention mechanism은 순차적 모델링에서 중요한 일부분이 되었다.
시퀀스의 거리에 관계없이(병렬적으로) 표현 쌍 간의 종속성을 잡아낼 수 있게 되었다.
이전 연구에서 서로 다른 위치에 있는 서로 다른 표현 부분 공간의 정보에 공동으로jointly 주의를 기울이는 것이 좋다는 것이 밝혀졌다.(여러 Trm을 jointly하게 고려한다는 뜻인 듯)
그래서 single attention function 대신 Multi-Head Self-Attention을 사용한다.
Multi-head attention은 먼저 학습 가능한 서로 다른 선형 투영을 사용하여 H_l을 h 개의 부분 공간으로 선형 투영한다. 그리고 h개의 attention function을 병렬적으로 적용함으로써 합쳐졌다가 다시 한 번 투영되는 출력 표현을 생성한다.
이는 동일한 sequence를 h개의 heads(attention functions)들이 각각의 관점에서 보고 추후에 합치는 과정이라고도 볼 수 있다.





이때 query Q, key K, value V는 다음처럼 해석할 수 있다.
Query의 Attention Value는 Query와 {Key: Value} 쌍이 주어졌을 때 Q와 K사이의 유사도를 가중치로 해서 각 K에 해당하는 v를 가중치 평균한 값이다.
중요한 것은 attention mechanism으로 input dimension을 h로 나눈 만큼 줄여서 attention function을 적용한 다음 h개를 concat하는 Multi-head self-attention이 하나의 input sequence를 h개의 여러 관점으로 바라보게 한다는 것이다.
Position-wise Feed-Forward Network(PFFN) 이란?
위에서도 봐왔듯 self-attention의 sub-layer은 주로 선형 투영을 기반으로 하기 때문에 모델에 서로 다른 차원 간의 비선형성 및 상호 작용을 부여하기 위해 각 위치에서 Position-wise Feed-Forward Network를 적용시킨 것이다.
구체적으로는 두 번의 아핀 변환affine transformation을 포함한다(아핀 변환은 변환 후에도 선이 평행한 상태로 유지된다).

ReLU 대신 GELU가 성능이 더 좋아서 대신 사용했다고 한다.
선형 투영 -> GELU -> 선형 투영을 거친 후 concatenate 한다.
Stacking Transformer Layer
위에서 설명한 것처럼 self-attention mecahnism을 사용하여 전체 사용자 행동 시퀀스에서 item-item 상호 작용을 쉽게 추출할 수 있다. 그럼에도 불구하고 self-attention 레이어를 쌓아서 더 복잡하게 item이 변환되는 패턴을 배우는 것이 일반적으로 더 좋다. 그런데 또 깊이를 깊게 하자니 train과정이 어려워진다.
그래서 ResNet에서도 사용하는 방식인데
Figure 1.(a) 에서와 같이 두 하위 계층의 input output에 추가 화살표로 연결해서 계층 정규화를 수행한다.
그리고 계층 정규화 직전에 Dropout을 사용해 줌으로써 네트워크 학습을 안정화시키고 빠르게 만든다.
요약해서 도식화하자면... 이전 layer 결과->MH -> dropout-> LN -> PFFN -> dropout -> LN -> 새로운 layer 결과

3.4 Embedding Layer
위에서 설명한 것처럼 반복이 없거나 convolution 모듈이 없으면 Trm은 입력 시퀀스의 순서를 인식하지 못한다.
input의 순차적 정보를 사용하기 위해 Trm 스택의 맨 아래에 있는 입력 항목 임베딩에 위치 임베딩을 주입합니다.


더 나은 성능을 위해 고정되어서 학습이 불가능한 정현파 임베딩(sin이나 cos 임베딩) 대신에 학습이 가능한 위치 임베딩pi를 사용한다.
이 방식이 sequence의 위치를 직접 반영하는 장점이 있지만, 모델이 처리할 수 있는 최대 문장 길이 N에 대한 제한을 가하기도 한다.
그래서 input sequence를 직전의 N개만큼만 가져와야 한다고 한다.(모델이 점점 오른쪽으로 갈수록 왼쪽 것까지 모두 수용하기는 역부족이어서 최근 N개의 sequence만 반영하는구나)

3.5 Output Layer
이전 레이어의 모든 위치에 걸쳐 계층적으로(병렬적으로) 정보를 교환하는 L 개의 레이어를 지난 후 입력 시퀀스의 모든 항목에 대한 최종 출력 H_L을 얻을 수 있다.
만약 시간 t에서의 item v_t를 [MASK]로 대체했다고 가정하면, h_L_t를 기반으로 v_t를 예측해야 한다.
Figure 1.(b)에서 연두색 함수가 output layer로 feed-forward Network를 2개의 layer로 쌓아서 만든다.

이때 과적합을 줄이고 모델 크기를 줄이기 위해 입력 및 출력 레이어에 shared item embedding matrix를 사용한다.
3.6 Model Learning
Training.
전통적인 단방향 순차적 추천 모델은 Figure 1.(c) , (d)처럼 다음 item을 하나씩 예측해왔다.
그러나 Fig 1(b)처럼 양방향 모델에서 좌우 context를 공동으로 조건화jointly conditioning하면 각 item의 최종 출력 표현에 target item의 정보가 포함된다.
이렇게 학습하면 예측의 의미가 없어지고 네트워크가 아무것도 배우지 못한다.(target item을 엿보는 현상)
해결책은...
t - 1 개의 샘플들(subsequences)을 만드는 것이다. EX) ([v1], v2) , ([v1,v2], v3), ...
이로써 양방향 모델로 target item을 예측할 수 있다.
그러나...
이 접근은 시간과 리소스 차원에서 매우 소모적이다. (t-1개의 sub-sequences를 만들고 각각에 대해 예측하는 건 힘들다.)
Cloze task
이런 효율성 문제를 해결하기 위해 Cloze task(Masked Language Model이라고 불림)를 순차적 추천 시스템에 도입한다.

사람에게는 빈칸을 채우라고 요구하는 문제이지만, 모델 훈련 과정에 Cloze test를 적용할 때는 일정 비율만큼의 items들을 [MASK] 특수 토큰으로 masking 한 후, 오직 좌우의 context 만으로 item을 예측하게 한다.

[MASK]에 해당하는 최종 은닉 벡터는 기존의 순차 추천에서와 마찬가지로 item 세트에 대한 출력 소프트맥스에 공급된다.


Cloze의 또 다른 장점으로 학습 데이터 sample을 더 만들어준다는 것이 있다. 만약 input sequence의 크기가 n이고 k개의 masked items가 있다면 nCk 개의 sampels들을 얻을 수 있고 이는 더 강력한 양방향 모델을 만들 수 있도록 한다.
Test
위에서 설명한 것처럼 Cloze objective는 현재 마스킹된 item을 예측하는 반면, 순차 추천은 미래를 예측하는 것이기 때문에 훈련과 최종 순차적 추천 사이에 불일치mismatch를 만든다.
이를 해결하기 위해 특수 토큰 [mask]를 사용자의 행동 시퀀스 끝에 추가한 다음 이 토큰의 숨겨진 최종 표현을 기반으로 다음 item을 예측한다.
순차적 추천 작업(즉, 마지막 item 예측)과 더 잘 일치하도록 하기 위해 훈련 중에 입력 시퀀스의 마지막 item만 마스킹하는 샘플도 생성한다.( v1 , ..., v_t-1, [MASK]) 그리고 이것이 미세한 조정을 가능하게 해서 성능을 높인다.
3.7 Discussion
다른 비슷한 모델들과의 비교
SASRec.
이 모델은 BERT4Rec의 단방향 버전으로 하나의 attention을 사용하고 causal attention mask를 사용한다.
반면 BERT4Rec은 Cloze를 써서 랜덤 하게 masking했기에 좌우 context를 모두 활용해서 예측할 수 있다.

CBOW & SG.
:continuous Bag-of-Words (CBOW) and Skip-Gram (SG)
CBOW는 콘텍스트에 있는 모든 단어 벡터의 평균을 사용하여 양방향으로 타깃 단어(item)를 예측한다.
이는 BERT4Rec에서 하나의 self-attention layer를 item에 대해 균일한 attention 가중치로 사용하고, item 임베딩을 공유하지 않고, 위치 임베딩을 제거하고, 중앙 item만 마스킹하면 BERT4Rec의 단순화된 경우로 볼 수 있다.
CBOW와 비슷하게 SG는 유사한 축소 작업을 수행한 BERT4Rec의 단순화된 경우로 볼 수도 있다(하나를 제외한 모든 item을 마스킹).
이런 관점에서 보면 Cloze는 CBOW와 SG 마스킹의 일반적인 형태라고도 볼 수 있다.
게다가 CBOW는 sentence가 아니라 word representation이 목표이기 때문에 단순한 aggregator를 사용한다.
반면, 우리가 원하는 것은 item 하나의 representaion이 아니라 이어지는 sequences를 모델링하기를 원한다.
BERT.
물론 BERT4Rec이 NLP 분야의 BERT에서 영감을 받았지만 분명 다른 점들이 있다.
a) 가장 큰 차이는 BERT는 sentence representation을 사전학습 모델인 반면, BERT4Rec은 순차 학습을 위한 end-to-end 모델이라는 점이다.(BERT는 언어가 동일한 배경지식을 공유한다고 가정하지만 이 논문에서는 그 가정이 성립하지 않아서 end-to-end로 해줘야함.)
b) BERT4Rec는 순차적 추천 작업에서 사용자의 과거 행동을 하나의 시퀀스로만 모델링하므로 그다음 문장의 loss 및 segment embedding을 제거한다는 차이가 있다.
(segment embedding: 단어가 첫 번째 문장에 속하는지 두 번째 문장에 속하는지 알려줌.)
4 EXPERIMENTS
4.1 Datasets
도메인과 밀도가 다양한 데이터셋 사용.
- Amazon Beauty : 뷰티 카테고리의 아마존 top 상품을 리뷰 데이터
- Steam: 온라인 게임 리뷰 데이터셋
- MovieLens: 영화 추천 알고리즘을 위한 유명한 벤치마크 데이터셋.
전처리
1. Explicit feedback{0, 1, 2, 3, 4, 5} -> implicit feedback {0, 1}
2. Feedback이 5개 이하인 user의 데이터는 제거
4.2 Task Settings & Evaluation Metrics
Task Settings

순차적 추천 모델을 평가하기 위해서 leave-one-out evaluation을 사용함.( sequence의 맨 마지막 한 개의 item 만을 test로 사용하고, 나머지를 전부 train set으로 취급, 그리고 test item 직전의 item을 validation item으로 취급.)
쉽고 공정한 평가를 위해 test set의 각 truth item을 사용자가 상호 작용하지 않고 랜덤 하게 샘플링된 100개의 negative item과 짝짓는다.(???)
표본추출을 신뢰할 수 있고 대표성 있게 만들기 위해 100개의 negative items은 인기도에 따라 표본 추출된다. 따라서 negative item을 각 사용자에 대한 truth item으로 순위를 매겨야 한다.
Evalutaion Metrics
모델이 만든 ranking list를 평가하는 지표로
HR NDCG MRR
등이 있음

4.3 Baselines & Implementation Details
4.4 Overall Performance Comparison

BERT4Rec이 평균적으로 7.24% HR@10, 11.03% NDCG@10, and 11.46% MRR의 향상을 보였다.
Question1.성능 향상이 bidirectional model 덕분일까, Cloze task도입 덕분일까?

SASRec에서 양방향 상호작용만 추가한 결과가 1번 -> 2번으로의 변화이고
Cloze 도입의 영향을 알기 위해 2번에서 3번으로의 변화를 주었다.
1번에서 2번으로 갈 때도 점수들이 전부 증가하므로 양방향 모델의 효과가 있음을 알 수 있고
2번에서 3번으로 갈 때도 점수들이 전부 증가하므로 Cloze task 도입의 영향도 긍정적인 것으로 알 수 있다.
Question 2. 왜 양방향 모델이 단방향 모델보다 성능이 좋을까?
10개 item 중 마지막 item이 mask된 상황. 색이 진할수록 모델이 그 item을 더 많이 고려한다는 뜻.

a) head 1은 왼쪽에, head 2는 오른쪽 item에 집중하는 경향이 있다.
b) layer1은 masked item에 집중하는 경향이 있다. 반면 layer 2는 최근의 item에 집중하는 경향이 있다.( layer 2가 output layer와 직접 연결되어 있기 때문.)
c) 양방향 모델은 좌우의 context를 모두 고려한다.
이제 여러 초모수에 대해 조사해보자
4.5 Impact of Hidden Dimensionality d

a) dimension이 커질수록 성능이 좋아지고
b) BERT4Rec , SASRec 모델의 경우 d가 너무 커지면 성능이 악화된다.
4.6 Impact of Mask Proportion ρ

masking 비율 ρ 을 적당히 조절해야 하는데,
dense한 dataset은 ρ =0.2 정도, sparse 한 dataset은 ρ = 0.4~0.6정도 가 적당하다.
sparse한 dataset의 경우 그 자체로 이미 일반화될 가능성이 커서 꽤 많이 masking을 진행해도 예측력이 유지되는 것 같다. 그러나 dense한 경우 그 비율이 높아지면 놓치는 정보의 양이 급격히 커지기 때문에 masking 비율이 낮게 최적화된다.
4.7 Impact of Maximum Sequence Length N
모델이 수용할 수 있는 최대 길이 N이 길면 길수록 과거의 sequence를 고려할 수 있는 장점이 있다. 그러면 N이 크면 무조건 좋은 것일까?
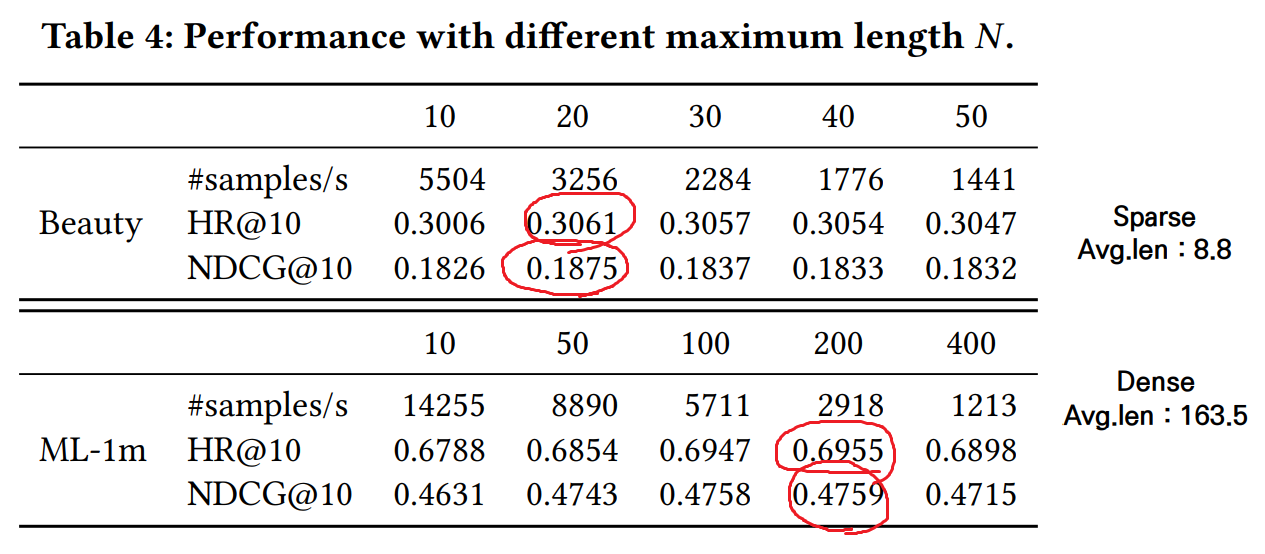
Beauty data는 sparse 하고 최적의 N =20이었다.
ML-1m data 는 dense하고 최적의 N = 200이었다.
dense하다는 것은 sequence의 길이가 길다는 것이고 따라서 N도 늘어나는 것이 당연하지만 커질수록 좋다는 것은 아니라는 것을 알 수 있다. N이 너무 크면 BERT4Rec의 계산 복잡도가 quadratic하게 증가하게 되는데 이 또한 고려해서 N을 선택해야 한다.

4.8 Ablation Study
ablation study는 초모수를 최적화하기 위해 하나씩 제거해보거나 하나씩 추가해보는 방식이다.

기본 상태default는 L =5, h =2, d=64, ρ 는 각자 optimal한 값이다.
(1) PE( position embedding)이 없으면 성능이 많이 감소했다.(특히 dense한 경우 더)
(2) PFFN layer 가 없으면 dense한 경우 더 성능이 많이 감소했다.
(3) LN, RC, and Dropout. 은 모델의 overfitting을 막아준다. sparse할 경우 overfitting에 취약하기 때문에 sparsse data에서의 성능을 크게 좌우한다.
(4) Number of layers L. 일반적으로 layer가 깊을수록 더 좋지만 beauty L=3 -> L=4를 보면 성응이 약간 감소한 것을 볼 수 있는데 이는 overfitting이 발생했음을 알 수 있다.
(5) Head number h. Beauty data처럼 sparse한 경우를 제외하고 어느 정도의 h 가 존재해야 multi-head self-attention이 제대로 작동하기 때문에 대부분 h=4 또는 h=8에서 최적의 성능을 보인 것을 볼 수 있다.
5 CONCLUSION
여러 층의 양방향 self-attention 구조는 언어이해에 큰 기여를 했다. 이 논문에서는 BERT4Rec이라는 다층 양방향 순차 모델을 순차 추천에 적용했다.
모델 학습에서는 Cloze task로 왼쪽 오른쪽의 context를 이용해서 masked item을 예측하도록 했다.
그리고 4개의 데이터셋에 적용한 결과 SOTA를 넘어서는 성능을 낼 수 있었다.





댓글 영역