고정 헤더 영역
상세 컨텐츠
본문 제목
[Advanced ML & DL Week4] LightGBM: A Highly Efficient Gradient Boosting Decision Tree
본문
작성자: 15기 우명진
1. Introduction
Gradient boosting decision tree(GDBT)은 효율성, 정확성, 해석력으로 인해서 많이 사용된다.
- 다항 클라스 분류, 클릭 예측, 순위 매기기 등의 task에서 사용된다
그러나 최근 들어서는 정확성과 효율성의 tradeoff에서 challenging하고 있다
기존의 GBDT는 모든 데이터를 이용하여 정보를 얻었다. 그렇기 때문에 피쳐의 개수와 데이터의 개수에 비례해서 시간이 오래걸렸다
따라서 해당 논문에서는 두가지 방법을 이용하여 task의 개수를 줄이는 방법을 제시한다
데이터의 개수와 피쳐의 개수를 줄이는 방법을 제안한다.
1. Gradient-based One-Side Sampling(GOSS)
Gradient가 큰 instance들은 중요도가 더 높기 때문에 중요도가 높은 instance는 유지하고, 낮은 instance는 randomly drop하는 방식이다. 이는 필요 없을 가능성이 높은 instance들을 배제하는 과정이다.
2. Exclusive Feature Bundling(EFB)
Sparse Feature Space에서는 feature들이 exclusive할 가능성이 높다.
Exclusive하다는 것은 어떤 instance에 대해서 두 가지 이상의 feature 값이 0이 아닌 값을 가질 확률이 드물다는 것이다.
비슷한 예시로는 one-hot encoding이 있다. 즉 동시에 0이 아닌 숫자를 가질 확률이 적다.
이런 feature들은 서로 bundle화할 수 있다.
2. Prelimiaries
-Gradient Boosting Decision Tree(GBDT)
GBDT는 각 iteration에서 negative gradient를 fitting하여 decision tree를 학습한다.
가장 시간이 오래 걸리는 부분은 best split point를 찾아내는 것이다.
Split Point를 찾아내는 모델은 1) pre-sorted algorithm과 2) histogram-based algorithm이 있다.
1) Pre-sorted algorithm은 pre-sorted feature values에 모든 split point를 찾아서 반복하는 것인데, 이는 매우 간단하고 최적의 split point를 찾을 수 있다는 장점은 있지만, 시간과 메모리 측면에서 비효율적이다.
2) Histogram-Based algorithm인데, 연속적인 feature values를 discrete bins으로 bucket화한다. 그리고 이 bin을 이용하여 feature histograms을 만들게 된다.
두 모델 중에서는 XG-Boost가 메모리와 시간 측면에서 효율적이기 때문에 이 XG-Boost를 basis로 이용을 했다.
3. Gradient-based One-Side Sampling
-Reducing the Data Instances


Gradient-based One-Side Sampling(GOSS)는 Large Gradient를 가진 instance를 보존하고, Small Gradient를 가진 instance를 random sampling하여 일부만 보존한다.
특히나, 기울기가 높은 a%의 feature의 정보는 그대로 나누고, 나머지 b% feature 중 random하게 선택을 한다.
이때 a는 더 작게 할수록, 그리고 b는 더 작게 할 수록 더 좋은 성능을 낸다.
데이터를 단순하게 제거하는 것은 데이터의 분포를 바꾸어서 데이터 손실이 발생할 수 있지만, small gradient를 가진 instances들에 constant multiplier를 곱하여서 데이터 손실을 막는다.
+) instacne의 gradient가 작을수록 training error가 작고 이미 well-trained된 상태라고 볼 수 있다. 그러나 우리는 이미 well-trained된 데이터가 필요한 것이 아니라 학습시킬 데이터 즉 large gradient를 가진 Instances이 필요하기 때문에 최대한 large gradient를 보존하고자 하는 것이다.
4. Exclusive Feature Bundling
-Reduce the Number of Features

1. Greedy Bundling: 현재 존재하는 feature들에 대해서 어떤 feature를 bundle로 묶을 것인가
2. Merge Exclusive Features: bundle로 묶은 변수들을 이용해서 하나의 새로운 변수로 표현하는 것
1. 어떤 변수들끼리 Bundle로 묶을 것인가
: Graph Coloring Problem

각각의 그래프를 그린다. 노드들은 feature, edge는 두 feature 간의 conflict를 의미한다. (conflict가 많을수록 bundling이 되면 안된다. 중복이 되면 안되기 때문이다)
conflict가 없는것끼리 bundle할 수 있다.
맨 왼쪽의 경우에는 8개를 번들1(파란색)/ 번들2(초록색)/ 번들3(주황색)/ 번들4(빨간색)으로 4가지 bundle을 만들 수 있다.
이때 Minimum Vertex Coloring은 NP-hard 문제이기 때문에 Greedy Bundling을 통해 approximation을 진행할 수 있다.
<Greedy Bundling Example>

edge: 동시에 0이 아닌 수로 객체 정의 -> 강도 설정
degree를 각각의 node에 대해서 계산한다. 왜냐하면 greedy bundlig이기 때문에 처음에 greedy를 시작하는 시작점이 존재해야한다.
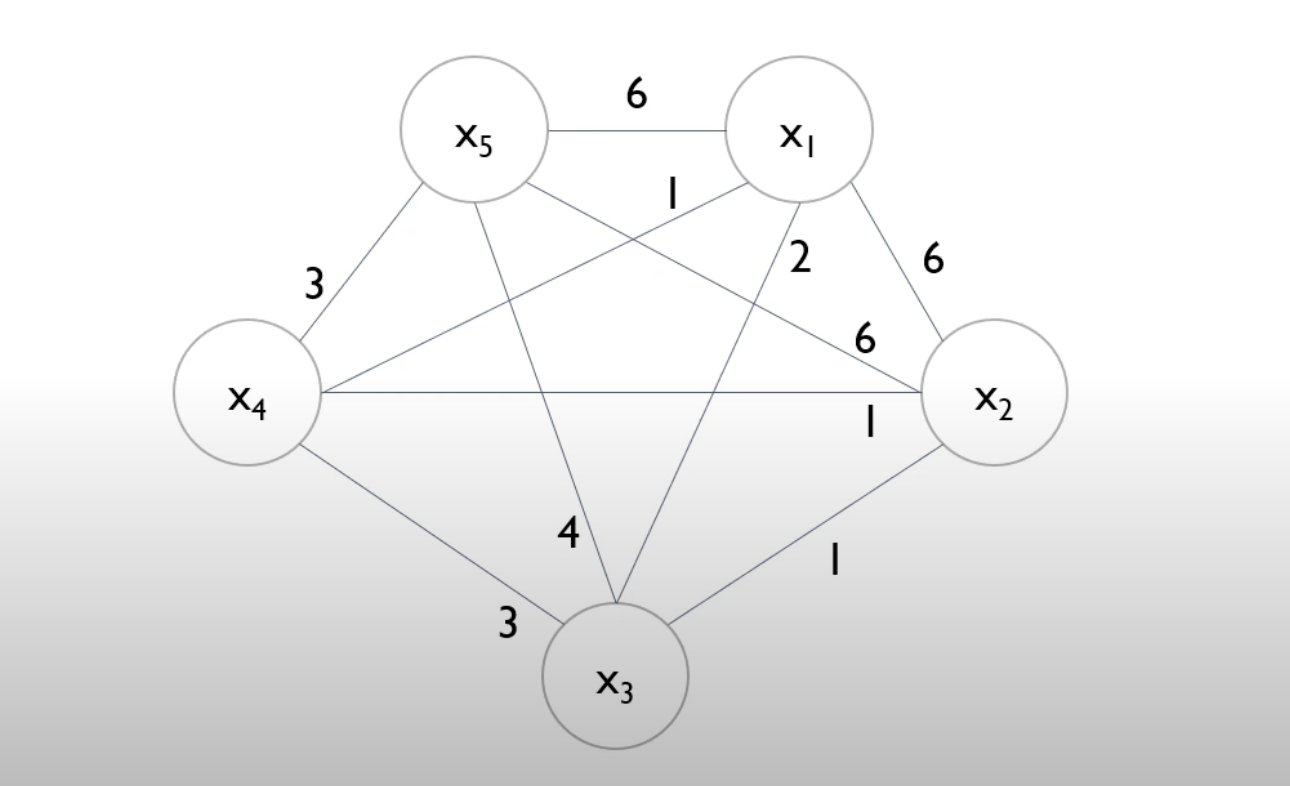
cutoff = 0.2로 결정(cut-off는 parameter)
N=10이기 때문에 10x2 = 2회 이상 non-zero value값들이 나타나게 되면 bundle를 진행하지 않는다
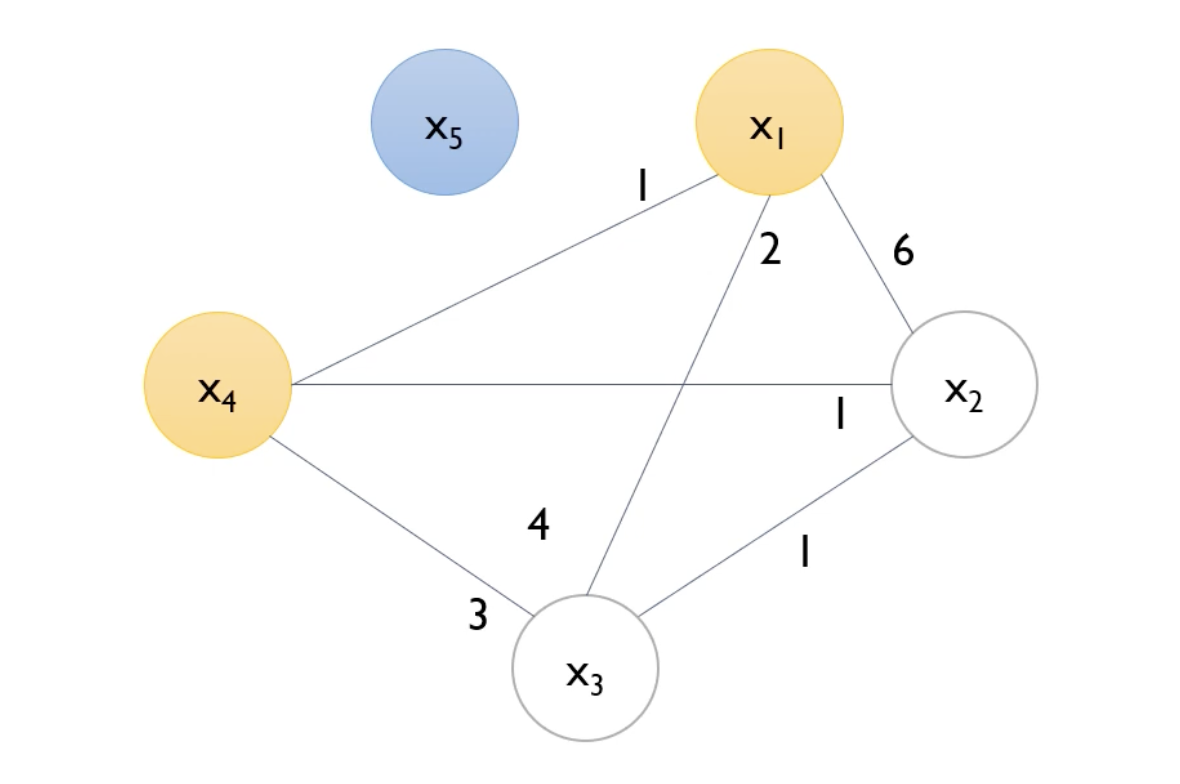
X5의 모든 node들이 끊기게 된다.
이후 다음으로 degree가 높은 X1에 대해서도 같은 과정을 진행해준다
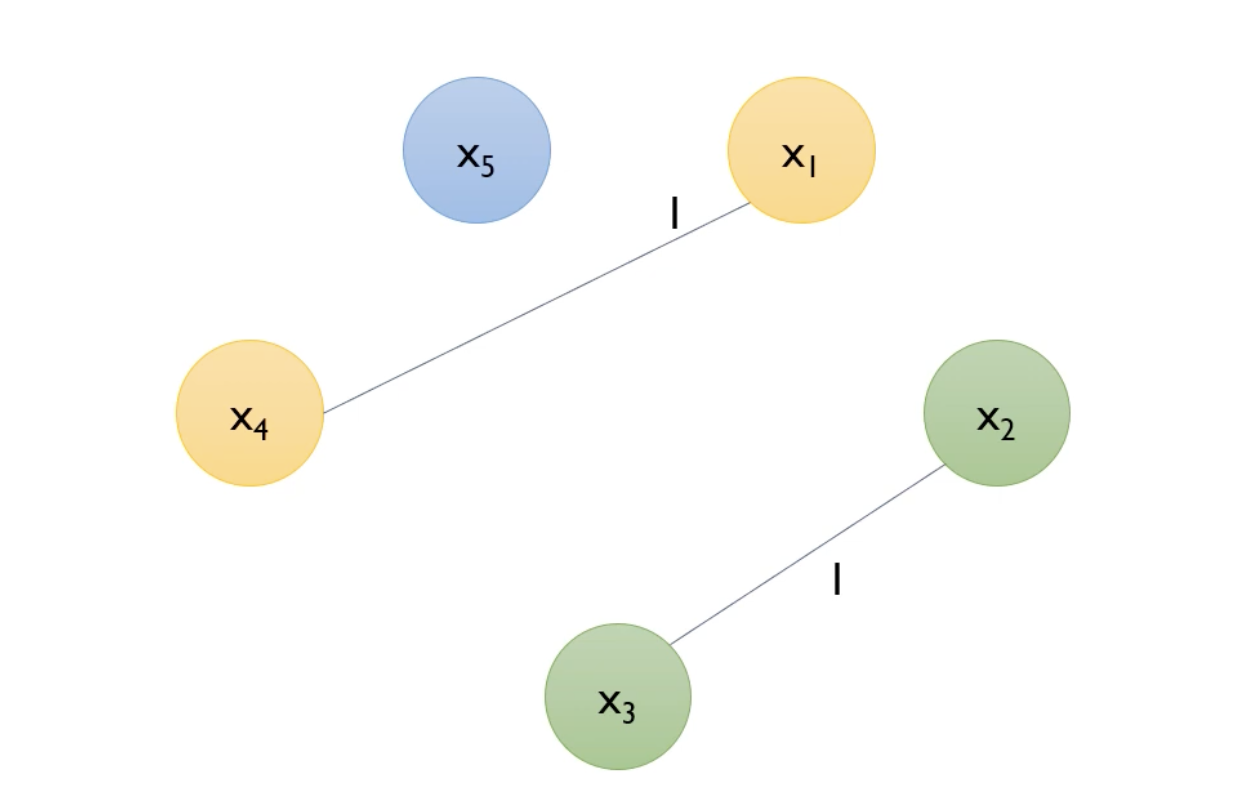
X1, X2, X3, X4, X5가 (X1,X4), (X2,X3), X5로 bundle되었다.
따라서 Greedy Algorithm의 결과로 5개의 변수가 3개의 bundle이 되었다.
2. 어떻게 bundle을 merge할 것인가?
: 변수의 기존 값에 offset을 더한다

offset을 더한다는 것은 bundle 내에서 0인 값에 다른 변수의 값에다가 기존의 최댓값을 더해주는 것이다.
conflict가 발생할 때는 기준 변수를 그대로 가져오고, 이때는 정보의 손실이 발생하게 된다.
5. Experiments
1) 사용된 데이터셋

2) training time

-lgb_baseline: GOSS와 EFB를 제외한 lgb
-LightGBM: GOSS와 EFB이 있는 lgb
-LightGBM: 속도가 가장 빠름
-반면에 xgb_his은 시간이 오래걸려서 out-of-memory
3) Overall Accuracy

-SGB: lgb_baseline에 stochastic gradient boosing 적용하였음
-LightGBM이 높은 정확도를 보이며 오차범위도 적음

6. Conclusion
데이터의 양이 크고, feature의 개수가 많을 때를 위해서 Gradient-Based One-Side Sampling과 Exclusive Feature Bundling을 도입하였고, 실험에서도 이론과 같은 결과가 나오는 것을 확인하였다.
그러나 모든 모델이 그렇듯이 늘 이 모델만 좋은 성능을 가지는 것은 아니기 때문에 다른 데이터에서는 다양한 모델을 시도해보는 것이 중요하다.





댓글 영역