고정 헤더 영역
상세 컨텐츠
본문 제목
[Advanced ML & DL Week5] Multivariate LSTM-FCNs for Time Series Classification
본문

작성자 : 14기 김태영
논문링크 : Multivariate LSTM-FCNs for Time Series Classification
Multivariate LSTM-FCNs for Time Series Classification
Over the past decade, multivariate time series classification has received great attention. We propose transforming the existing univariate time series classification models, the Long Short Term Memory Fully Convolutional Network (LSTM-FCN) and Attention L
arxiv.org
1. Time Series Classification 이란?
Time Series Classification이란 time series가 어떤 lable에 해당하는지 분류하는 태스크를 의미한다.

이 때 Time series 데이터는 univariate, multivariate 인 경우로 나누어 질 수 있다. 이는 용어 그 자체의 정의와 같다.
- Univariate : Sequence of measurements from the same variable are collected
- Multivariate : Sequence of measurments form multiple variables or sensors are collected
Time Series Classfication을 수행하기 방법론은 다음과 같이 두가지로 분류할 수 있다.
(1) Distance Based
- 특정 metric을 기반으로 시계열 데이터 간의 거리를 계산하여 가까운 거리를 기준으로 class를 분류
- Dynamic Time Warping(DTW)가 가장 좋은 성능을 내는 것으로 알려져 있음.
(2) Feature Based
- 시계열 데이터의 intrinsic feature을 추출하여 분류
- Hidden State Conditional Random Field / Hidden Unit Logistic Model이 대표적이나 intrinsic feature을 추출하는 작업은 매우 challenging함.
2. Background
2-1. Recurrent Neural Network(RNN)
(1) Vanilla RNN
가장 기본적인 RNN모델이다. RNN은 hidden state의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서 다시 hidden state의 다음 계산의 입력으로 보내는 특징을 갖는다.
(2) Stacked RNN (Multilayer RNN)
말 그대로 RNN 층을 여러개 쌓은 구조로 더 복잡한 태스크를 해결할 수 있다.
RNN에 대한 자세한 설명은 다음 링크를 통해 확인 가능하다.
1) 순환 신경망(Recurrent Neural Network, RNN)
RNN(Recurrent Neural Network)은 입력과 출력을 시퀀스 단위로 처리하는 시퀀스(Sequence) 모델입니다. 번역기를 생각해보면 입력은 번역하고자 하는 단어…
wikidocs.net
2-2. LSTM
기존 RNN은 입력 시퀀스가 길어질 수록 back propagation시 vanishing gradient가 발생한다는 문제점을 가지고 있다. 이를 해결하기 위해 셀의 구조를 여러 gate를 추가하여 재구성한 것이 LSTM이다.
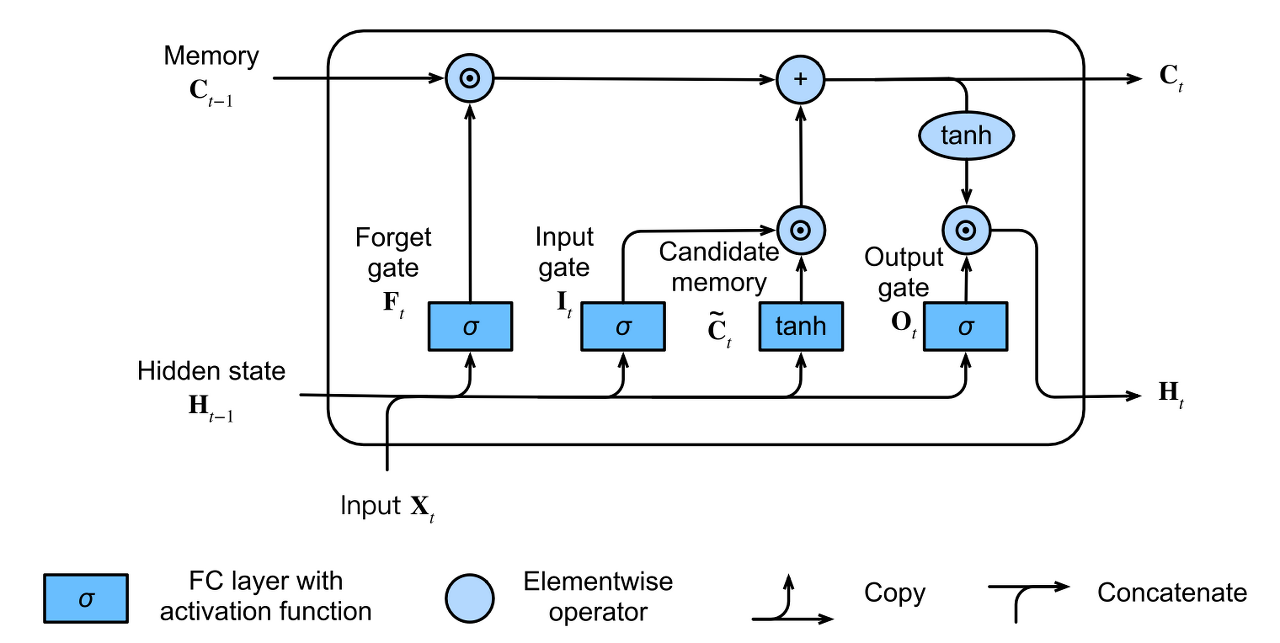
LSTM에 대한 자세한 설명은 다음 링크를 통해 확인 가능하다.
[D2L] 9. Modern RNN
RNN 계열에서 자주 쓰이는, 더 fancy한 모델에 대해 다뤄보겠다. 1. GRU(Gated Recurrent Unit) long products of matrices는 gradient vanishing, exploding 문제를 가진다. 이런 gradient anomaly가 현실에서 어떤 문제를 갖는
needmorecaffeine.tistory.com
2-3. Attention Mechanism
Bahdanau Attention Mechanism으로 불리는 Sequence to Sequence 모델이다. 기본 개념에 대해 정리하고 넘어가자면 다음과 같다.
- seq2seq 모델
- 인코더에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고 디코더는 이 컨텍스트 벡터를 통해 출력 시퀀스를 만드는 모델
- 컨텍스트 벡터를 만들면서 정보를 압축하여 정보 손실이 발생함
- 인코더에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고 디코더는 이 컨텍스트 벡터를 통해 출력 시퀀스를 만드는 모델
- Attention (자연어 처리 예제를 통한 설명)
- 디코더에서 출력값을 예측하는 매 시점마다 인코더에서의 전체 입력 문장을 다시 한번 참고함
- 이 때 전체 입력문장을 동일한 비율로 참고하는 것이 아닌, 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을 좀 더 attention하여 참고
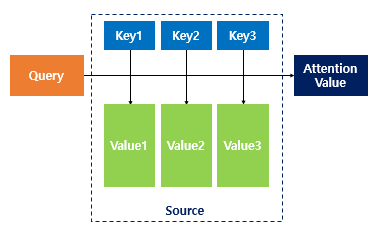
- Attention Function
- key-value 형 자료구조에서 착안
- Attention(Q,K,V) = Attention Value : 쿼리(Q)에 대해서 모든 키(Key)와의 유사도를 구함 >> 구한 유사도를 키와 맵핑되어 있는 각각의 Value(V)에 반영 >> 이 Value 값들을 모두 더해 Attention Value를 계산
- 위 인자값은 여기서 각각 다음을 의미함
- Q = t 시점의 디코더 셀에서의 hidden state
- K = 모든 시점의 인코더 셀의 hidden state
- V = 모든 시점의 인코더 셀의 hidden state
- Q = t 시점의 디코더 셀에서의 hidden state
- 여기서 Q,K,V, attention score를 계산하는 방식은 다양함 (참고링크)
- key-value 형 자료구조에서 착안
- 디코더에서 출력값을 예측하는 매 시점마다 인코더에서의 전체 입력 문장을 다시 한번 참고함
이제 Bahdanau Attention에 대해 살펴보자.
그 연산 과정은 다음과 같다.
(1) Attention Score 계산
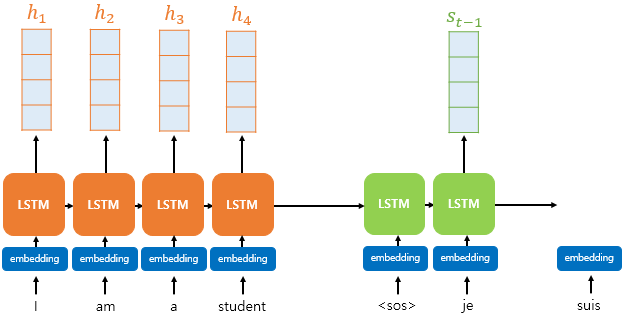
- 인코더의 hidden state = h / 디코더의 hidden state = s (두 hidden state의 차원은 같음)
- Q로 t-1 시점의 hidden state, St-1 사용
- 계산 방법
- Wa, Wb, Wc 는 가중치 행렬
- 수식 a : s와 h에 대해 각각의 attention score를 구해야 하는데 이를 위해 병렬연산 수행을 해야함.
수식 b : h1,h2,h3,h4를 H 하나의 행렬로 두고 두번째 수식으로 변경 - 수식 c : Wbst-1, WcH를 각각 구한 후 더하고 하이퍼볼릭탄젠트 함수 대입
- 수식 d : Wa (t)와 곱하여 유사도가 기록된 어텐션 스코어 벡터 e (t) 산출
- Wa, Wb, Wc 는 가중치 행렬
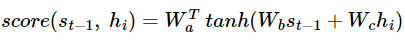


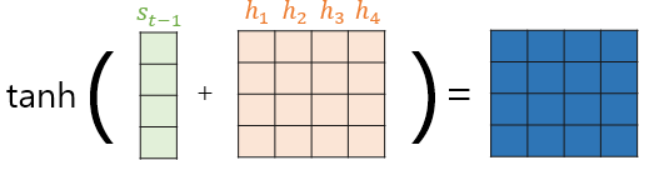
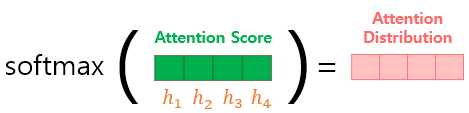
(2) 소프트맥스 함수로 Attention Distribution 계산
e (t)에 소프트맥스 함수를 적용하여 모든 값의 합이 1이 되는 확률 분포를 얻어냄.
(3) 각 인코더의 attention 가중치와 hidden state를 가중합하여 Attention Value 계산
가중합 결과의 벡터는 인코더의 문맥을 포함하고 있다고 하여 Context Vector라고 부름.

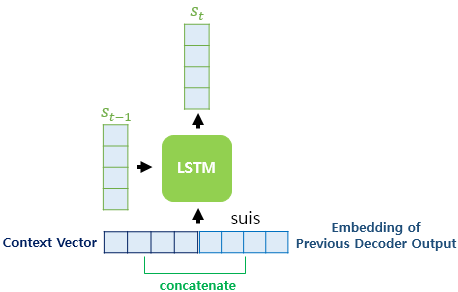
(4) Context 벡터로부터 St 계산
Context 벡터와 현재 시점의 입력값인 단어 임베딩 벡터를 concat하고 현재 시점의 새로운 입력으로 사용함.
이전 시점의 셀로부터 전달받은 hidden state St-1와 현재시점의 입력으로 St 계산.
2-4. Squeeze-and-excitation block
SENet(Squeeze and excitation network)에 적용된 주요 방법론으로 ILSVRC에서 우승한 모델이다.
SENet은 연산량이 크게 늘지 않으면서도 분류 정확도를 높일 수 있다는 장점이 있다. 이것이 가능한 이유는 채널 간 상호작용에 집중하여 이것을 포착하기 위해 고안된 방법론이기 때문이다.
convolution layer에서 Squeeze and Excite 라는 새로운 블록이 추가되는데 이는 원래 합성곱 신경망을 발전시키는 과정에서 등장한 네트워크 구조이지만 이를 LSTM-FCN에 적용한다.
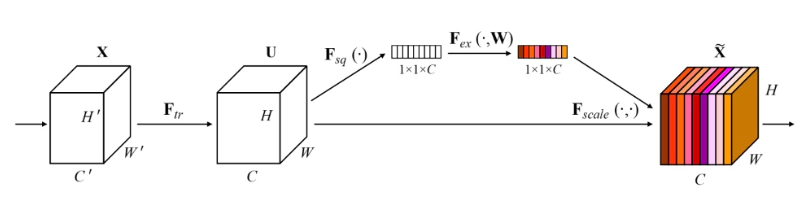
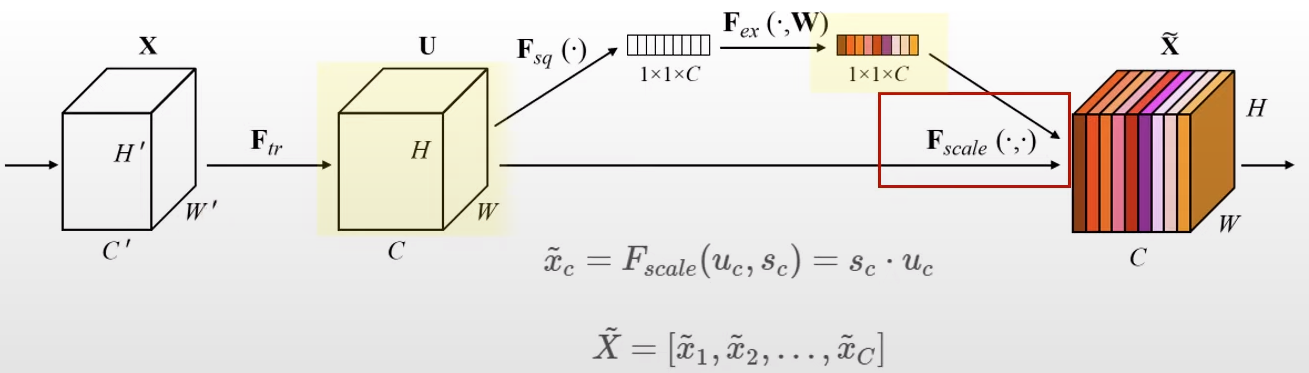
연산과정을 차례대로 살펴보면 다음과 같다.
(1) 앞의 두개의 텐서는 convolution 연산을 수행한 것으로 input X를 convolution한 결과 텐서가 U이다.

(2) Squeeze 연산
global information embedding으로도 불리며 각 채널들의 중요한 정보만을 추출하는 기능을 한다.이 때 global average pooling을 사용하여 H x W x C에서 1 x 1 x C 로 feature map 크기를 조정한다. 위 구조 사진 및 아래 연산은 이미지 데이터의 경우로 2D global average pooling을 수행하지만 시계열 데이터의 경우 시간 축을 기준으로 1D GAP를 수행한다.

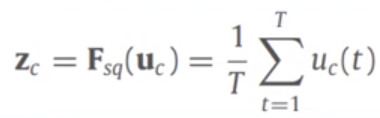
(3) Excitation 연산
앞서 Squeeze 되었던 정보를 재조정하는 연산으로 Adaptive Recalibration으로 불린다. 이 연산은 채널 간 의존성(channel-wise dependencies)를 계산하는 과정으로 아래 수식과 같이 FC layer와 비선형 활성함수를 활용한다.
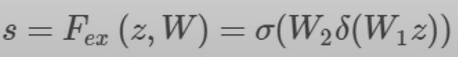
이 때 행렬 W는 C x C 차원을 갖는데 W1 (C/r x C)와 W2 (C x C/r) 로 나누어지는데 이렇게 bottleneck구조를 만드는 것은 모델의 복잡성을 제어하고 일반화를 돕는 기능을 한다. 이 때 reduction ratio r을 통해 bottleneck 정도를 결정한다.
(4) Rescale 연산
위 Squeeze-excitation을 통해 계산한 벡터를 Squeeze Excitation 연산 수행 이전의 C개의 feature map에 각각 곱해주는 연산이다. 이 연산을 통해 channel 간의 dependency 가중치 값을 반영해주는 기능을 구현하는 것이다.
또한 excitation 연산의 출력값은 합성곱 블록의 출력형태와 일치하지 않는다는 점에서도 rescale이 필요하다.
Excitation Operation을 거친 스케일된 값 Sc 들은 모두 0과 1사이의 값으로 각 채널들의 중요도를 나타낸다고 볼 수 있다.
3. Methodology
3-1. Network Architecture
네트워크 전체 구조는 다음과 같다.
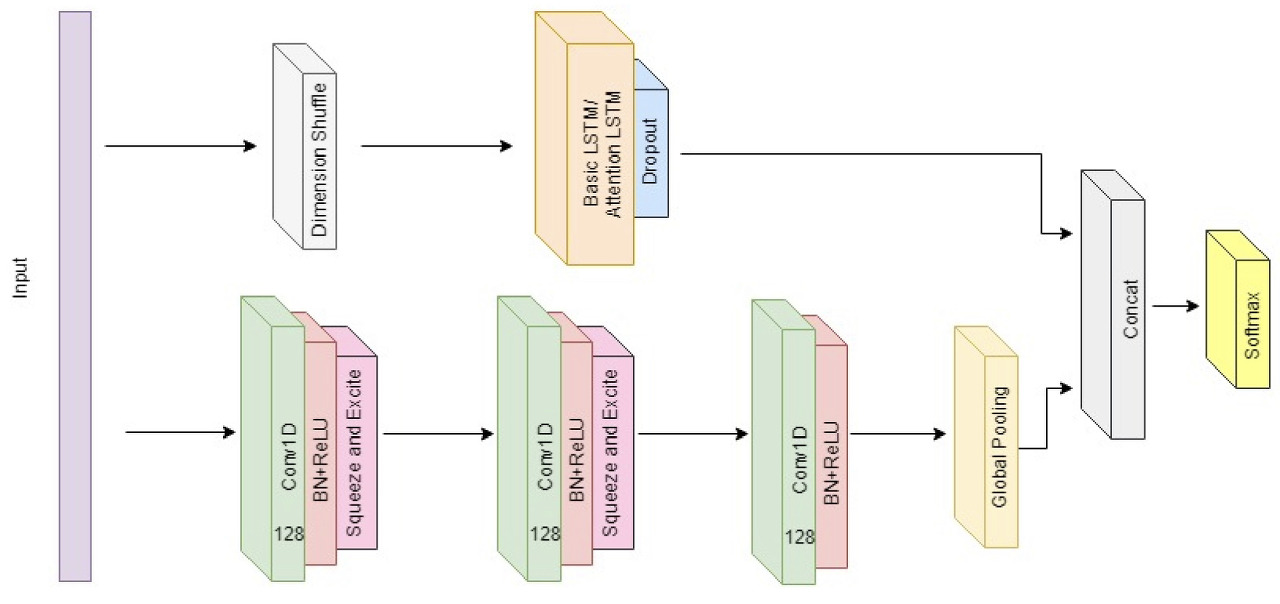
사진 기준 위는 LSTM block, 아래는 Fully convolution Block과 Squeeze-and-Excitation Block으로 구성되어 있다.
(1) LSTM block
LSTM block은 이전에서 설명한 LSTM과 Attention 두가지 옵션 모두 선택하여 사용가능하다.
다음의 명칭을 가진다.
- LSTM layer >> MLSTM-FCN
- Attention LSTM layer >> MALSTM-FCN


(2) Fully Convolution Block
3개의 1D convolution block을 사용하였고 필터 사이즈는 각각 128, 256, 128이며 커널 사이즈는 각각 8, 5, 3이다.
Batch Normalization과 ReLU 함수를 사용했고 처음 두개의 convolution block의 마지막에 squeeze-and-excite block을 사용했으며 이 때 r =16으로 설정하였다. 이렇게 설정함으로써 multivariate 데이터임에도 10,240개의 파라미터만이 증가해 저자는 이를 효율적이라고 평가하였다.
마지막에 global average pooling을 수행한다.
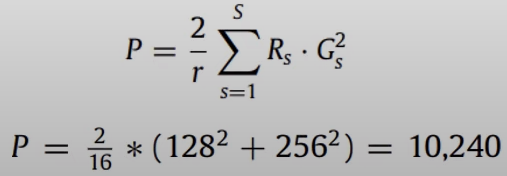
3-2. Network Input
시계열 데이터는 [Q, M] 차원을 갖는다.
- Q : time steps (시계열 길이)
- M : distinct variables per time step (변수 개수)
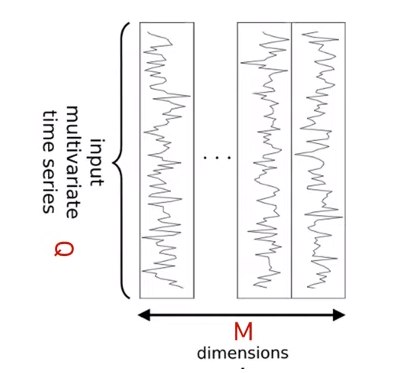
이 때 네트워크의 LSTM block과 FCN block은 다른 차원의 input 값이 주어지는데 다음과 같다.
(1) LSTM block
[M, Q] 차원의 데이터를 input으로 하는데 이는 원래 시계열 데이터 차원인 [Q, M]을 transpose 한 것으로 이것을 Dimension Shuffle이라고 한다. 이렇게 하면 M개의 변수가 Q 길이의 history 정보로 표현되는 것으로 각 변수의 global temporal information을 한번에 input으로 사용한다고도 해석할 수 있다.
Dimenstion Shuffle을 하는 이유는 일반적인 경우 M이 Q보다 작은 값을 갖는데 [M, Q] 차원을 input으로 할 경우 연산 속도가 빨라진다는 장점을 갖는다. 실험 결과 처리 속도를 59% 감소시켰다. 이런 효율성 측면에서 조작한 것으로 dimension shuffle 실행 여부에 따라 성능은 차이가 없다고 한다.
(2) FCN block
원래 시계열 데이터의 형식과 같이 [Q, M] 차원의 데이터를 input으로 갖는다. 이렇게 되면 M이 FCN에서 channel 차원이 되고 squeeze-and-excitation block을 거쳐 변수 간의 상호 의존도를 파악해 다변량 데이터셋에서 성능이 높아지는 원인이된다.
4. Experiment
다음의 총 35개의 다변량 시계열 벤치마크 데이터셋을 사용해 실험하였다.

Accuracy 기준 MALSTM-FCN이 35개의 데이터셋 중 28개의 데이터셋에서 SOTA를 달성하였다.
MLSTM-FCN은 평균 3.29등, MALSTM-FCN은 3.17등을 달성하였고 이는 비모수 사후 검정 방법으로 '모든 데이터셋에 대해서 비교 대상의 성능이 동일하다'의 귀무가설을 갖는 Nemenyi test를 통해 우수성이 입증되었다.
References





댓글 영역