고정 헤더 영역
상세 컨텐츠
본문 제목
[Advanced ML & DL Week4] DEEP LEARNING FOR ANOMALY DETECTION: A SURVEY
본문
작성자: 15기 이병주
논문 링크: DEEP LEARNING FOR ANOMALY DETECTION: A SURVEY
리뷰 영상 :https://www.youtube.com/watch?v=wSgnhxZ3iQo (출처:DSBA)
1. Introduction
deep anomaly detection(DAD) method를 리뷰하고 다양한 도메인의 적용과 효율성을 평가하는 survey
2. What is anomaly?
데이터마이닝, 통계학에선 abnormalities, deviants, or outliers 라고도 한다.

대부분 모여있는 N1,N2가 정상 데이터, O1, O2, O3는 anomalies.
point anomalies : O1, O2 같은 event 한개 씩
contextual anomalies: 조건부 이상치, 특정 상황에서 이상치가 발생하는 것
Collective or Group Anomaly: 이상치가 대량으로 한번에 발생 (ex: 디도스 공격)
3. What are novelties?

normal이지만 그 중에서 특이한 것들이 novel (백호), 호랑이가 아닌 것들은 모두 anomalies.
8. Different aspects of deep learning-based anomaly detection.
8.1 nature of input data

데이터 타입에 따라 사용하는 모델의 종류가 다르다.
8.2 Based on availability of labels
label을 활용가능한지에 따라서 supervised, unsupervised, semi-supervised로 나뉜다.
8.2.1 Supervised deep anomaly detection
정상과 이상 데이터의 label이 모두 존재하는 경우
사실상 classification 인데 정상에 비해 이상의 데이터 수가 많이 부족해서 불균형 문제 발생, label 둘다 존재하는경우가 많지 않음.
8.2.2 Semi-supervised deep anomaly detection
대부분은 정상인 경우와 그에 따른 label을 확보하는 것이 가능하므로 가장 현실적.
8.2.3 Unsupervised deep anomaly detection
label이 아예 없을 때, 전체 데이터 대부분이 정상이라는 가정이 필요함.
ex) PCA, SVM, isolation forest, auto encoder, restricted Boltzmann machine (RBM), deep Boltzmann machine (DBM), deep belief network (DBN),recurrent neural network (RNN), Long short term memory networks(LSTM)
Anormaly Detection Models
SVM
가장 대표적인 anomaly detection 모델로 주로 OC-SVM(one class) 가 사용
정상데이터를 원점으로부터 멀리 떨어직게 하고 정상과 비정상을 구분하는 hyperplane을 찾음


w: 데이터에 따른 변동성을 최소화하겠다.
psi: 점들과 hyperplane사이의 거리
lo: 원점과 hyperplane 사이의 거리
Isolation forest

데이터들을 가지치기로 분류한다는 컨셉.
이상이 있는 데이터(outlier)는 초기 단계에서 다르게 분리되고 정상데이터는 더 늦게 분리된다.
outlier score는 다음과 같다. (최종적으로 이상이라 판단하는 스코어)

N: 랜덤하게 트리에 사용되는 max_sample의 수
E(h(x)):각 data의 평균 경로 길이
c(n): max_samples에 대한 평균 경로길이를 normalization하기위한 상수 값
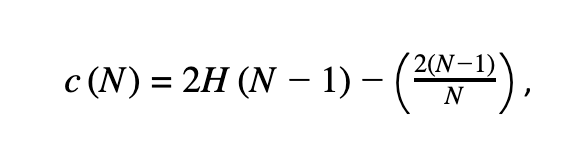
이때 H(i) ≈ ln(i) + 0.5772156649
score가 높으면 이상치, 낮으면 정상
Autoencoders

input과 output의 뉴런의 수가 같음
encoder: 낮은 차원으로 축소하여 특징을 뽑음
decoder: encoder의 output을 받아 원래 데이터로 재구성한다.

이상 데이터를 넣으면 정상데이터처럼 복원하므로 이상치는 차이가 생김
LSTM-AE
시계열에서 이상탐지에 사용됨. 오토인코더처럼 정상 데이터를 학습시키고 예측된 값과의 차이를 보는 것

Step 1 : LSTM이 이전 데이터를 학습하여 다음 l개의 데이터를 예측한다.
Step 2: 실제 데이터와 error를 계산한다.
Step 3: error가 크면 이상치





댓글 영역