고정 헤더 영역
상세 컨텐츠
본문 제목
[Advanced ML & DL Week5] word2vec: Efficient Estimation of Word Representations in Vector Space
본문

0.Abstract
이 논문에서는 매우 큰 데이터셋에서 연속적인 단어의 벡터 표현을 계산하기 위한 두 가지의 새로운 Model Architectures을 제시한다.
이렇게 만들어진 모델은 단어 유사도 task을 기준으로 기존의 다른 NN 모델들과 비교 평가되었고, 훨씬 낮은 계산 비용에서 큰 정확도의 향상을 발견했다. (16억개 단어 데이터셋을 벡터화하는 데 하루 밖에 안 걸린다고 한다.)
그리고 이 모델로 문법적syntactic, 의미적semantic 단어 유사도에서 SOTA를 달성했다고 한다.
1. Introduction
2013년 당시 많은 NLP 시스템들과 기술들은 단어를 원자 단위atomic units로 처리하였다.
atomic units로 계산하면 간단하고 범용적이며, 많은 데이터로 학습한 간단한 모델이 적은 데이터로 학습한 복잡한 모델보다 나을 수도 있다. 그러나 고품질 speech data의 양이 성능을 크게 좌우하는 위 방식처럼 간단한 기법으로 올릴 수 있는 성능에는 한계가 있다.
기계 번역에서, 현존하는 corpora(말뭉치)들은 몇 십억개, 혹은 이보다 적은 단어들로 구성되어 있다. 그러므로, 더 발전된 기법에 초점을 맞춰야 한다. 최근 기계 학습의 발전으로, 더 복잡한 모델을 더 많은 데이터 set에 대해 학습하는 것이 가능해졌고 보통 간단한 모델들의 성능을 능가한다.
1.1. Goals of the Paper
이 논문의 목표는 high-quality의 word vector를 큰 데이터 셋으로부터 학습하는 기술을 소개하는 것이다. 당시 어떤 기존 연구도 수 억개보다 많은 단어로, 50-100차원의 word vector를 성공적으로 학습한 적 없다고 한다.
벡터 표현의 성능을 측정 하기 위해 당시의 최신 기술을 사용했는데, 비슷한 의미의 단어가 가깝게 나타나는 것뿐 아니라 단어들이 multiple degrees of similarity를 갖길 기대한다고 한다. 이것은 inflectional language굴절어(fast : faster: fastet)의 문맥에서 관찰된 적 있다.
EX)
명사는 여러 어미를 가질 수 있는데, 우리가 original vector space의 subspace에서 비슷한 단어를 찾는다면,
비슷한 어미를 가진 단어를 찾을 수 있을 것이다.
(의미의 유사성 뿐만아니라 문법적인 어미의 유사성도 잡아낼 수 있다는 뜻인 듯)
놀랍게도, 단어 표현의 similarity는 단순한 문법적인 정규화 이상을 나타낸다. Word offset technique(단어 벡터에 단순한 대수적 계산을 하는 기술)을 이용하면 다음과 같은 예시의 결과를 보여준다.
vector(King) - vector(Man) + vector(Woman) ~ vector(Queen)
마치 filtering 이나 검색을 하는 듯한 효과.
논문에서 단어 간의 linear regularity는 유지하면서 벡터 operation의 정확도를 최대화하기 위해 새로운 모델 구조를 개발하고자 했다. 통사론적(문법적), 의미론적 규칙성regularities을 측정할 새로운 포괄적인 test set을 설계하고, 많은 규칙성들을 높은 정확도로 학습할 수 있다는 것을 보인다. 나아가 학습 시간과 정확도가 단어 벡터의 차원과 학습 데이터의 양에 의해 얼마나 어떻게 좌우되는지 논한다.
1.2. Previous Work
단어를 연속적인 벡터로 표현하려는 시도는 오래되었다고 한다. neural network language model(NNLM)을 추정하기 위해 모델 구조가 제안되었다. 이는 linear projection layer과 non-linear hidden layer을 갖는 feedforward neural network이며 word vector representation과 statistical language model을 jointly하게 학습했고 많은 사람들이 이것을 따라 했다고 한다.
NNLM의 다른 흥미로운 구조는 word vector를 먼저 single hidden layer의 neural network로 학습하고 이 word vector를 NNLM을 학습하는 데에 쓰는 구조이다. 그러므로 word vector는 full NNLM을 구축하지 않고도 학습된다. 이 중에서 저자는 구조를 직접적으로 확장하고 word vectors를 간단한 모델로 학습하는 첫 번째 단계에 집중한다.
나중에 word vectors가 많은 NLP 응용문제들을 개선하고 단순화하는 데에 쓰일 수 있다는 것이 드러났다. word vectors의 추정은 다른 모델 구조로 이루어지고 다양한 말뭉치를 이용해 학습된다. 그 결과 word vectors의 일부는 이후의 연구나 비교가 가능하도록 만들어졌다. 하지만 이 구조들은 앞서 제안된 구조보다 학습하는 일이 상당히 더 computationally expensive하다고 한다.
2. Model Architectures
Latent Semantic Analysis (LSA)와 Latent Dirichlet Allocation (LDA)를 포함하여 많은 다른 종류의 모델들이 단어의 연속적 표현을 추정하기 위해 제안되었다. 이를 위해 neural network로 학습하는 단어의 distributed representations에 집중한다. (LSA는 성능이 떨어지고, LDA는 큰 데이터 셋에서 계산이 매우 무겁다.)
서로 다른 모델 구조들을 비교하기 위해 먼저 모델의 computational complexity를 train과정에서 접근할 parameters의 수로 정의한다. 그리고 정확도를 최대화하면서 computational complexity를 최소화해야한다. 모든 이후의 모델들에서 training complexity는 다음에 비례한다.
O = E x T x Q (1)
E = training epoch의 수, T = training set의 단어 수, Q = 나중에 각 모델 구조에서 따로 정의.
보통 E는 3~50으로 선택되고, T는 십억까지로 정해진다. 모든 모델들은 stochastic gradient와 backpropagation을 이용해서 학습된다.
2.1. Feedforward Neural Net Language Model(NNLM)
4개의 layers: input, projection, hidden, output layer로 구성되어 있다.

input layer
- N 개의 이전 단어들이 1-of-V coding(one-hot-vector)으로 인코딩 됨 (V 는 전체 단어의 수)
- 보통 N = 10 으로 지정
- projection matrix를 통해 input이 projection layer로 전달
projection layer
- N × D dimensionality
- 상대적으로 저렴한 비용의 연산이다.
- D = 500 ~ 2000
- projection layer와 hidden layer 사이의 연산에서 상대적으로 큰 비용이 발생
- hidden layer size H = 500 ~ 1000
output layer
- V 차원의 결과를 제공
- 계산 비용 computational complexity
Q = N × D + N × D × H + H × V (2)
- 가장 큰 비용을 차지하는 부분 : H × V
- hierarchical softmax 를 사용하면 비용이 log(V) 까지 줄어들 수 있음
이 논문의 모델에서는 vocabulary를 Huffman binary tree로 표현하는 hierarchical softmax를 사용한다. 이는 단어의 frequency가 NNLM에서 classes를 얻는 데에 잘 작동한다는 관찰을 따른 것이다. Huffman trees는 frequent words에 짧은 binary codes를 부여하고 이는 나중에 evaluate 될 output unit의 수를 줄여준다.
EX)
어떤 문맥 단어( "Yes") 다음에 "I'm"이라는 단어가 오도록 학습시키려고 한다면 트리를 구성하고 내려갈 때 가중치를 잘 설정해주면 된다. 단어들을 트리 배치할 때, 단어의 빈도가 잦으면 얕게, 드문 단어들은 깊게 배치한다.( 그러면 tree가 문맥 단어에 따라 달라지니까 단어별로 서로 다른 문맥 tree가 존재하겠네~)
Balanced binary tree는 log2(V)만큼의 output을 evaluate 해야 하는 반면에, Huffman tree based hierarchical softmax는 log2(unigram perplexity(V))만을 필요로 한다(vocabulary size가 백만일 때 두 배 빠름). 나중에 hidden layer가 없어서 softmax normalization의 효율에 크게 의존하는 구조를 제안할 것이다. (그래서 softmax normalization -> Huffman binary tree가 중요하다는 말). (N*D*H term이 Computational 보틀을 만들기 때문에 NNLM에 있어서 결정적인 스피드 업은 아니지만)
2.2. Recurrent Neural Net Language Model (RNNLM)
RNN기반의 언어모델은 feedforward NNLM의 한계들(e.g. 문맥의 길이(order of the model N)를 정해야 함)을 극복할 수 있고, RNN이 얕은 NN보다 복잡한 패턴을 더 잘 표현하기 때문에 제안되어왔다. RNN 모델은 projection layer를 갖지 않고, input-hidden-output layer만 갖는다. 이 모델의 특이한 점은 time-delayed connection을 이용해 hidden layer를 스스로와 연결시키는 recurrent matrix이다. 이 recurrent model이 어떤 단기 기억을 생성하게 한다. Current input과 그 전 타임 스텝의 hidden layer의 상태에 기반해서 hidden layer state가 업데이트되면서, 과거로부터의 정보를 표현하고, 단기 기억이생성된다. RNN model의 training example당 complexity는 다음과 같다.
Q = H x H + H x V (3)
단어 표현 D는 hidden layer H와 차원이 같다. 또, hidden term H*V는 hierarchical softmax를 사용하기 때문에 H*log2(V)까지 줄어든다. 대부분의 complexity는 H*H에서 온다고 한다.
2.3. Parallel Training of Neural Networks
이 논문에서는 큰 데이터 셋으로 모델을 학습시키기 위해 DistBelief(tensorflow의 이전 세대 프레임워크 라이브러리)에서 feedforward NNLM과 새로운 모델을 구현했다. 이로써 같은 모델의 여러 복제본을 병렬 처리할 수 있게 해 주고, 각각의 복제본은 모든 parameters를 유지하는 중앙 서버를 통해 gradient update를 동기화한다. 이러한 병렬 training을 위해 저자는 Adagrad라고 불리는 adaptive learning rate procedure와 함께 mini-batch asynchronous gradient descent를 사용한다. 이 프레임워크 하에서, 각각이 여러 CPU core로 백 개 혹은 그 이상의 복제본을 사용하는 것은 흔한 일이라고 한다..
3. New Log-linear Models

이 섹션에서, 저자는 computational complexity를 최소화하는 단어의 distributed representations(벡터 공간에 표현)를 학습하기 위한 두 개의 새로운 모델 구조를 제안한다. 앞 절에서는 대부분의 complexity가 model의 non-linear hidden layer에서 생겼다. 이 점이 NN을 매력적으로 만드는 부분이지만, 보다 단순한 모델을(NN만큼 정밀하게 데이터를 나타내지는 못하더라도 더 많은 데이터를 효율적으로 학습할 수 있는 모델을)탐색하기로 결정했다고 한다.
새로운 구조는 저자가 이전에 제안했던 것들을 직접 따른다. 이들은 NNLM이 성공적으로 두 단계에 걸쳐 train될 수 있음을 보여주었다.
(1)우선 간단한 모델로 연속적인 word vector을 학습하고,
(2) distributed representations of words 상에서 N-gram NNLM을 학습한다.
후에 wordvectors를 학습하는 데에 집중한 상당한 양의 연구들이 있었지만, 저자는 가장 간단한 접근을 위해 다른 방식은 고려하지 않는다.
아래 두 모델에 대해 간단히 요약하자면
CBOW는 주변에 있는 문맥 단어 여러 개(Context Word)를 가지고 타깃 단어 1개(Target Word)를 맞히는 과정에서 학습되고, 반대로 Skip-gram은 타깃 단어 한 개를 가지고 주변 문맥 단어가 무엇일지 여러 개 예측하는 과정에서 학습된다.
각각의 방식에 대해 알아보기 전, 두 모델에서 모두 등장하는 '윈도우(window)'라는 개념이 있다. 타깃 단어를 중심으로 앞뒤 몇 개의 단어를 살펴볼 것인지(= 문맥 단어로 둘 것인지)를 정해주는데, 그 범위를 윈도우라고 부른다. 여러 단어로 구성된 문장에서 첫 번째 단어부터 한 단어씩 옆으로 옮겨가며 타깃 단어를 바꾸어 나갑니다. 이러한 방식을 슬라이딩 윈도우(sliding window)라고 부른다.

3.1. Continuous Bag-of-Words Model 첫 번째 모델 구조
첫 번째 구조는 non-linear hidden layer을 없앴고 projection layer이 (projection matrix 뿐 아니라) 모든 단어에 대해서 공유된다는 점에서 feedforward NNLM과 비슷하다. 따라서 모든 단어는 같은 위치로 project 된다(벡터들의 평균을 구했다는 의미).
단어의 순서가 projection에 영향을 주지 않는다는 점에서, 저자는 이 구조를 bag-of-words model이라고 부른다. 나아가, 저자는 미래의 단어 또한 사용한다. 다음 섹션에서 최고의 성능을 얻었는데, 이는 미래와 과거 단어를 네 개씩 input으로 사용하여 중앙의 단어를 바르게 분류하는 log-linear classifier를 구성한 결과이다. 학습 complexity는 다음과 같다.
Q = N x D + D x log2(V) (4)
정리하자면 이 모델은 NNLM에서 hidden layer를 제거한 것이다. CBOW의 목표는 NNLM과 동일하게 word vector 1개를 예측하는 것이다. 다만 NNLM에서는 이전 word들만을 사용해 다음 word를 예측했다면, CBOW에서는 양방향(이전/이후)의 word 총 NN개를 사용해 예측을 진행한다.
CBOW는 NNLM에 비해 computational complexity를 감소시켰는데, NNLM에서의 projection layer는 activation function을 사용하지 않는 linear layer였다. 반면 hidden layer는 activation function을 사용하는 non-linear layer였다. hierarichial softmax를 사용한다는 가정 하에 가장 연산량이 많이 소요되는 layer가 hidden layer였으므로 이를 제거해 전체 연산량을 줄인 것이다. NNLM에서 hidden layer의 존재 의미는 여러 word embedding vector를 하나의 vector로 압축하는 것이었다면, CBOW에서는 이를 non-linear layer를 거치지 않고 단순하게 평균을 내게 된다. 따라서 CBOW의 projection layer는 word embedding vector(WpWp에서의 row)들의 평균이다.
3.2. Continuous Skip-gram Model 두 번째 모델 구조
두 번째 구조는 CBOW와 비슷한데, 문맥으로 current word를 예측하는 것이 아니라, 같은 문장의 다른 단어들의 분류를 목표로 한다. 구체적으로, 각각의 current word를 continuous projection layer을 갖는 log-linear classifier의 input으로 사용하고, current word의 앞과 뒤 특정 구간 내의 단어들을 예측하도록 한다. 저자는 구간의 범위를 늘리는 것이 word vector의 성능을 향상한다는 것을 알아냈다. 당연히 이는 computational complexity도 증가시킨다. 일반적으로 멀리 떨어진 단어일수록 current word에 덜 관련된 단어이기 때문에, training example에서 먼 단어를 덜 sampling함으로써 먼 단어에 더 적은 weight를 준다. 이 구조의 training complexity는 다음에 비례한다.
Q = C x (D + D x log2(V)) (5)
C = 단어의 최대 거리.
만약 C=5를 선택한다면 각각의 training word에 대해서 우리는 랜덤으로 1~5사이의 숫자 R(예를들어 3)을 선택하게 된다. 그리고 current word를 기준으로 앞과 뒤의 R(=3)개 단어들을 사용한다. 이것은 R*2개의 단어 분류를 필요로 한다. (current word를 input으로, R+R개 단어를 output으로) 아래의 실험에서 저자는 C=10을 사용했다.

즉, Skip-gram은 CBOW와 유사하지만 input/output이 서로 뒤바뀐 경우이다. 현재 word를 통해 이전, 이후의 word를 예측하는데, 여러 word에 대해 prediction을 수행하기 때문에 당연하게도 연산량은 CBOW에 비해 많다. 하지만 skip-gram은 input word vector를 평균내지 않고 온전히 사용하기 때문에 등장 빈도가 낮은 word들에 대해 CBOW 대비 train 효과가 크다는 장점이 있다. CBOW에서는 각 word vector들을 평균내서 사용하기 때문에 등장 빈도가 낮은 word들은 제대로 된 학습을 기대하기 힘들다.
4. Results
다른 버전의 word vectors의 성능을 비교하기 위해서 선행연구들은 일반적으로 예시 단어들과 가장 비슷한 단어들을 보여주는 표를 사용하고, 이를 직관적으로 받아들여왔다. 비록 "France"와 "Italy"라는 단어가 비슷하다는 것은 알지만, 더 복잡한 similarity task에서 이러한 벡터들을 처리하는 것은 훨씬 더 어렵다.
저자는 단어 간의 여러 종류의 similarity가 있을 수 있다는 앞선 관찰을 따르는데...
EX) big이라는 단어는 bigger과 비슷하고 이 비슷함은 small이 smaller과 비슷한 것과 같은 종류다. 다른 관계의 예시로는 big-biggest와 small-smallest가 있다. 저자는 나아가 같은 관계를 갖는 두 단어 쌍을 알아본다. "biggest"가 "big"과 비슷한 맥락에서 "small"에 가장 비슷한 단어는 무엇일까?
놀랍게도, 이 질문들은 word vectors의 간단한 대수 연산으로 대답할 수 있다. Biggest가 big과 비슷한 것과 같이 small과 가장 비슷한 단어를 찾으려면 다음 계산을 하면 된다.
X = vector("biggest") - vector("big") + vector("small")
그리고 X와 가장 가까운(cosine similarity) 단어를 vector space에서 찾아 답하면 된다. (이때 input 단어는 제외한다.) Word vector가 잘 train되었다면 이 방법을 통해 답(smallest)을 찾는 것이 가능하다.
결국, 저자는 고차원 word vector을 많은 데이터에 대해 train했을 때, 결과 vector가 단어 사이의 매우 미미한 의미 차이에 대해서도 답할 수 있다는 것을 알았다.
EX) 국가와 그 국가에 속한 나라: France-Paris와 Germany-Berlin관계는 같다. 이런 의미 관계의 word vector는 기계번역, information retrieval, question answering systems 같은 많은 NLP 응용을 향상하는데 쓰일 수 있다.
4.1. Task Description
Word vector의 성능을 측정하기 위해, 저자는 다섯 종류의 의미론적 문제와 아홉 종류의 통사론적(문법적) 문제를 포함하는 포괄적인 test set을 정의한다. 각 카테고리의 예시 두 가지씩이 표1에 나타나 있다. 전체적으로, 8869개의 의미론적 문제와 10675개의 통사론적 문제가 있다.
각 카테고리의 문제들은 두 단계에 걸쳐 만들어지는데, 먼저 유사한 단어 쌍이 수작업으로 만들어진다. 그리고, 두 단어 쌍을 연결해서 긴 질문 리스트를 만든다.
EX) 68개의 미국 대도시과 그들이 속한 주 목록을 만든다. 그리고 두 단어 쌍을 랜덤으로 뽑아 약 2500개(68C2 =2278)의 질문을 만든다. test set에 single token 단어만 포함시켰고 따라서 New York과 같은 multi-word entity는 제외한다.

저자는 모든 종류의 문제(8869개의 의미론적 문제와 10675개의 통사론적 문제)들을 구분해서 전반적인 정확도를 평가한다. 각 문제에 대해 계산된 벡터에 가장 가까운 단어closest word가 정확히 답과 일치할 때에만 옳은 답이라고 채점한다. 유의어는 오답으로 채점된다. 이는 현재 모델이 단어 형태에 대한 어떠한 input 정보도 없기 때문에, 100% 정확도가 불가능할 것임을 의미한다. 그러나, word vector의 특정 응용에서의 유용성이 이 정확도 metric과 관련있을 것이라고 생각된다. 단어의 구조에 대한 정보를 통합하면 특히 문법적인 질문에 대해 성능을 높일 수 있다.
4.2. Maximization of Accuracy
저자는 word vector를 학습하는 데에 Google News corpus를 이용했다. 이 corpus는 60억 개 정도의 token을 포함한다. Vocabulary size는 frequent한 단어들에 대해서 백만개로 제한했다. 데이터를 더 쓰거나 word vector의 차원을 늘리는 것이 정확도를 향상할 것이기 때문에, 저자는 시간을 최소화하면서 최적화를 해야하는 문제를 맞닥뜨렸다. 가능한 한 좋은 결과를 빠르게 얻는 최선의 모델 구조를 평가하기 위해, 먼저 모델을 training data의 subset에 대해서 학습시켜 평가했다(단어를 가장 빈도높은 3만개로 제한). 각각 다른 차원의 word vector와 training data의 양을 늘려가며 CBOW를 이용한 결과는 표2에 나타나 있다.

어떤 시점 이후에, 차원을 더하거나 데이터를 더해도 개선 수준이 줄어드는 것을 확인할 수 있다(2 행의 4,5열). 그래서, vector의 차원과 데이터의 양을 동시에 증가시켜야 한다. 이 관찰이 사소해보이지만, word vector를 상대적으로 많은 데이터에 대해서 충분치 못한 size(50~100)로 학습하는 일이 현재 빈번하다는 것을 염두해 둬야한다. 식 (4)에 따라서, 학습데이터가 두 배로 늘어나는 것은 vector size를 두배로 늘리는 것과 같은 computational complexity 증가를 야기한다.
표 2와 4에 나타난 실험에 대해서, 저자는 stochastic gradient descent와 backpropagation으로 3 epochs를 학습했다. 시작점의 learning rate는 0.025였고, 선형적으로 감소하여 마지막 epoch에서 0이 되도록 설정했다.
4.3. Comparison of Model Architectures
먼저 저자는 다른 모델 구조에 대해 같은 학습데이터와 같은 차원(640)으로 word vector를 학습시켜 비교한다. 이후의 실험에서, 3만개의 vocabulary 제한을 두지 않고, 새로운 Semantic-Syntactic Word Relationship test set의 전체 문제를 사용한다. 우리는 또한 다른 통사론적인 similarity에 집중한 다른 test set에 대한 결과도 포함한다.
학습데이터는 몇몇의 LDC 말뭉치를 포함하고 있다.(말뭉치 오픈 소스:320M words, 82K vocabulary) 저자는 이 데이터를 이용해 pre-trained RNNLM과 비교했다. 저자는 feedforward NNLM을 같은 수의 640 hidden units로 8개의 과거 단어를 사용하고, DistBelief 병렬학습을 이용해 학습시켰다. (projection layer가 640*8이기 때문에 RNNLM보다 많은 parameter를 쓴다. )
표3에서, RNNLM에서의 word vector가 통사론적 문제에 대해서 대부분 잘 작동하는 것을 볼 수 있다. NNLM vectors는 RNN보다 상당히 잘 작동한다.(RNNLM의 word vector가 non-linear hidden layer에 직접적으로 연결되기 때문에 이는 놀라운 일이 아니다.) CBOW 구조는 통사론적, 의미론적 과제에서 NNLM보다 더 잘 작동한다. 마지막으로 Skip-gram 구조는 CBOW 보다 통사론적 구조에서 성능이 덜하지만 의미론적 구조에서는 최고의 성능을 보인다.

다음으로, 저자는 모델들을 단일 CPU를 사용하여 학습하고, public하게 이용가능한 word vector와 결과를 비교했다. 비교 결과는 표4에 나타나있다. CBOW model은 Google News data의 subset으로 하루만에 학습된 반면 Skip-gram model의 학습 시간은 3일이었다.
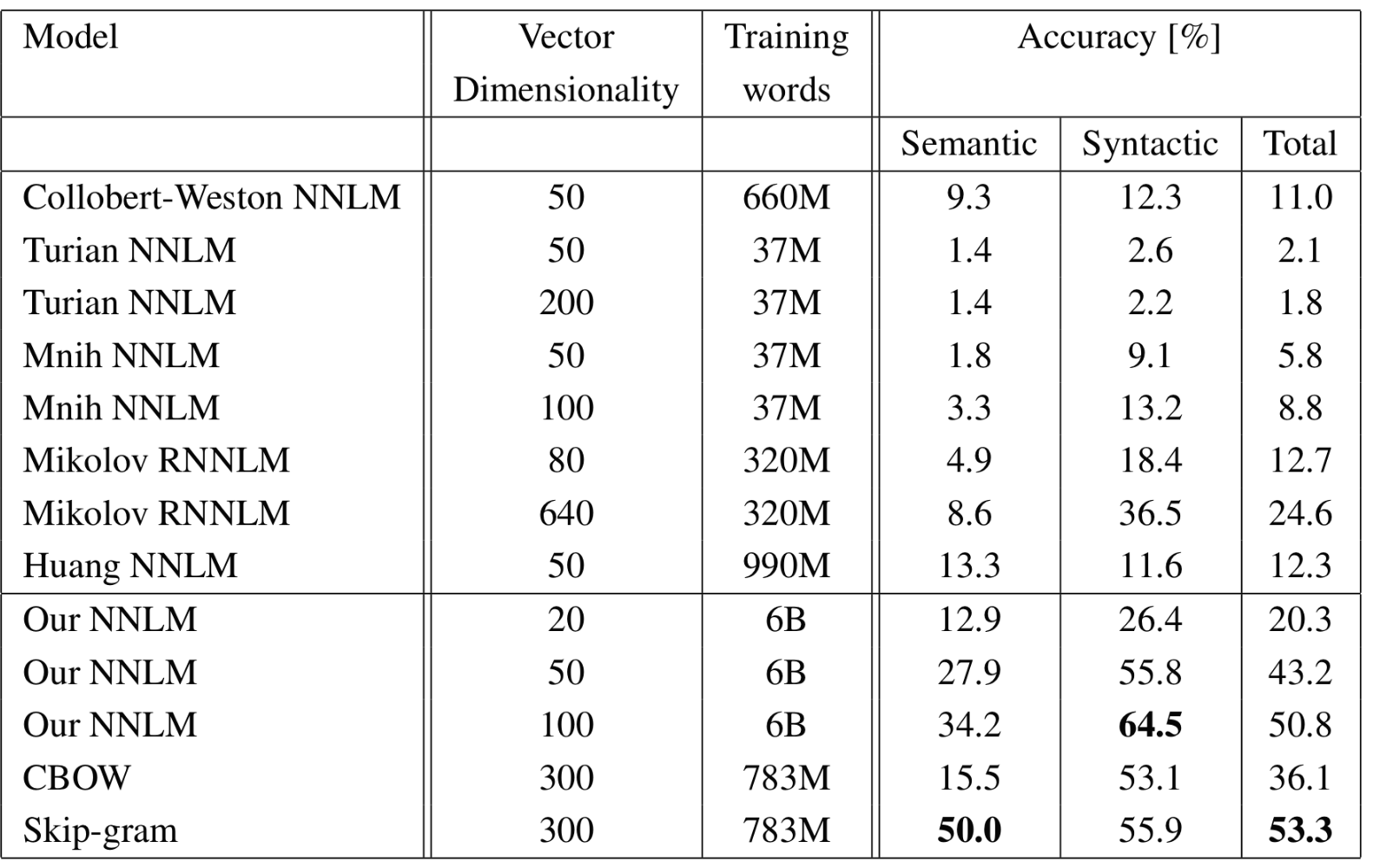
후에 나올 실험에 대해, 저자는 학습 epoch를 하나만 사용했다.(learning rate는 마지막에 0이 되도록 선형적으로 줄인다.) 모델을 두 배의 데이터에 대해 한 epoch 학습시키는 것은 같은 데이터에 대해 세 번의 epoch를 학습하는 것과 비슷하거나 더 나은 결과를 보였다. 결과는 표5에 나타난다. 그리고 추가적으로 약간 더 빠르다.

4.4. Large Scale Parallel Training of Models
앞서 언급했듯, 저자는 다양한 모델을 DistBelief라는 분산 프레임워크에서 구현했다. 아래에 우리는 Google News 6B data set에 대해 mini-batch asynchronouw gradient descent와 adaptive learning rate procedure (Adagrad)를 이용해 학습한 여러 모델의 결과를 나타낸다. 저자는 학습에서 50에서 100개의 모델 복제본을 사용했다. Data center machines가 다른 작업과 공유되고, 사용량이 유동적fluctuate이기 때문에, CPU core의 수는 추정값이다. 분산 프레임워크의 overhead 때문에, CBOW 모델과 Skip-gram 모델의 CPU 사용량은 그들의 단일 machine 구현보다 서로 훨씬 더 비슷한 것을 볼 수 있다.(앞서 하루와 3일 이라고 한 것.) 결과는 표6에 나타나 있다.

4.5. Microsoft Research Sentence Completion Challenge
Microsoft Research Sentence Completion Challenge는 language modeling과 다른 NLP 기술들을 발전시키기 위한 당시에 개최되었다. 이 challenge에서는 각 문장에서 한 단어씩을 빠뜨려 5지선다형으로 문맥에 맞는 단어를 넣는 것을 목표로 하는 1040개의 문장을 포함한다. 이 set에 대한 몇몇 기술-N-gram model, LSA-based model, log-bilinear model, RNN의 combination(당시 55.4%의 정확도로 가장 훌륭함)의 성능은 이미 알려져 있다.
저자는 이 작업에 대한 Skip-gram 구조의 성능을 알아보았다.
1) 우선, 640차원 모델을 주어진 5천만개 단어에 대해 학습한다.
2) 그리고 빈칸의 단어를 input으로 하고 문장의 내부 단어를 모두 맞추도록 하여 각 문장의 점수를 계산한다.
3) 최종 점수는 각각 예측의 합으로 한다. 문장 점수를 사용해서 가장 그럴듯한 문장을 정한다.
이전의 결과들과 새로운 결과는 표7에 짧게 요약되어있다. Skip-gram 모델은 그 자체로 LSA보다 잘 작동하진 않지만, 이 모델의 점수는 RNNLM의 점수를 보완할만 했으며 그들의 weighted combination은 58.9% 정확도를 달성할 수 있다. (학습 파트에서 59.2%, 테스트에서 58.7%)

5. Exampled of the Learned Relationships
표8은 다양한 관계에 나타나는 단어들을 보여준다. 저자는 앞서 말한 접근법을 따랐다: 관계는 단어 벡터를 빼는 것으로 정의되고 결과는 다른 단어에 더해진다. EX) Paris - France + Italy = Rome.
보다시피 정확도는 꽤 좋았지만 많은 개선의 여지가 있다. (평가 메트릭이 정확한 match 만을 채점하기 때문에 표8의 결과는 60%밖에 되지 않음). 저자는 더 큰 data set에 더 큰 차원으로 학습한 word vector가 더 잘 작동할 것이고, 새로운 혁신적 응용을 개발할 수 있을 것이라고 믿는다. 정확도를 올리는 또 다른 방법은 관계에 대해 하나 이상의 예시를 제공하는 것이다. relation vector를 만드는 데에 하나가 아니라 열 개의 예시를 적용한다면,(벡터의 평균을 사용) 정확도가 10%정도 향상됨을 볼 수 있었다.

또한 다른 일들을 해결하는데에 vector 연산을 적용할 수도 있다. 예를 들어, out-of-the-list 단어들을 선택하는 데에, 목록의 단어의 평균 벡터와 가장 먼 단어 벡터를 선택함으로서 좋은 정확도를 확인할 수 있었다. 이것은 인간의 지능 테스트에서 흔한 종류의 문제이다. 분명히, 이 기술을 활용해서 할 수 있는 많은 발견들이 여전히 있다.
6 Conclusion
이 논문에서는 CBOW와 skip-gram이라는 새로운 word embedding 학습 방법을 제안했다. 기존의 여러 model들에 비해 연산량이 현저히 적고, 간단한 model임에도 매우 높은 성능을 보였다. 또한 word embedding vector의 syntax, semantic 성능을 측정할 수 있는 새로운 dataset을 제시했다.
https://arxiv.org/abs/1301.3781
Efficient Estimation of Word Representations in Vector Space
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best per
arxiv.org
negative sampling





댓글 영역